Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
在当前的模型调试实践中,最大的难点之一在于使用聚合指标根据基准数据集对模型进行评分。 模型准确度在数据子组之间可能不一致,并且可能存在模型失败频率更高的输入队列。 这些失败会导致缺乏可靠性和安全性、出现公平性问题,以及完全失去对机器学习的信任。

错误分析不使用聚合准确度指标。 它以透明方式向开发人员公开错误分布,让开发人员能够有效地识别和诊断错误。
负责任 AI 仪表板的错误分析组件让机器学习从业者更深入地了解模型故障分布,并帮助他们快速识别错误的数据队列。 此组件标识与总体基准误差率相比,具有较高错误率的数据队列。 它通过以下方式为模型生命周期工作流的识别阶段提供帮助:
- 显示错误率较高的队列的决策树。
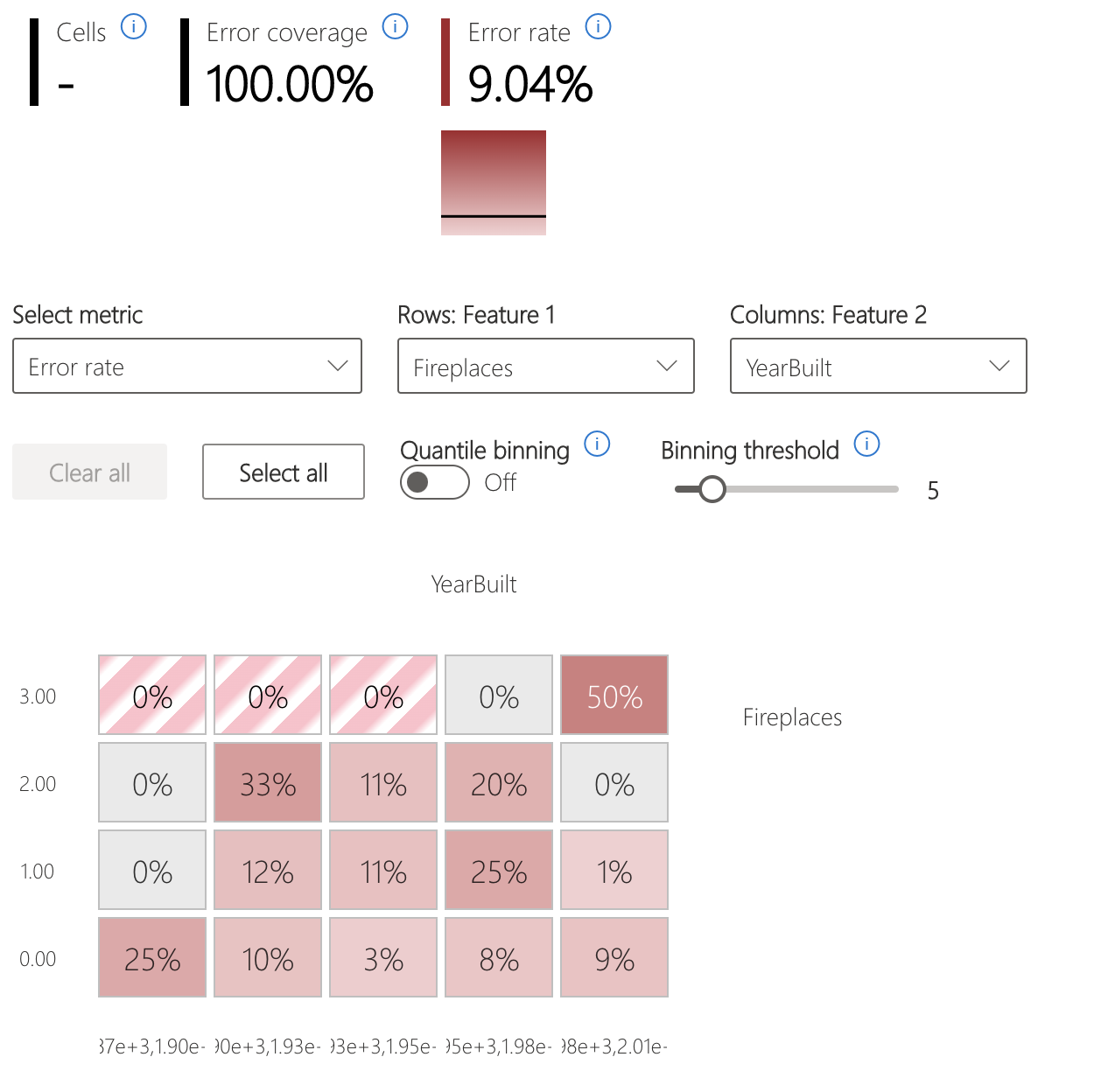
- 直观显示输入特征如何影响各个队列的错误率的热度地图。
当系统对训练数据中的特定人口群体或不经常观察到的输入队列表现不佳时,可能会出现误差。
此组件的功能来自错误分析包,该包生成模型错误概况。
以下情况下需要使用错误分析:
- 深入了解模型故障在数据集以及多个输入和特征维度中的分布方式。
- 分解聚合性能指标以自动发现错误的队列,以便你可以采取有针对性的缓解步骤。
错误树
错误模式通常很复杂,涉及多个或两个功能。 你可能很难探索所有可能的特征组合,以发现隐藏的数据口袋,其中存在严重故障。
为了减轻负担,二进制树可视化会自动将基准数据分区为可解释的子组,这些子组具有出乎意料的高或低错误率。 换句话说,此树使用输入功能尽可能地将模型错误与成功区分开来。 对于定义数据子组的每个节点,可以调查以下信息:
- 错误率:模型不正确节点中的实例部分。 可视化效果通过红色的强度显示此值。
- 错误覆盖范围:所有错误中落入节点内的部分。 可视化效果通过节点的填充率显示此值。
- 数据表示形式:错误树的每个节点中的实例数。 可视化效果通过指向节点的边缘粗细以及节点内的实例总数来显示此值。

错误热力图
此视图基于输入特征的一维或二维网格对数据进行切片。 可以选择感兴趣的输入特征进行分析。
热度地图使用较深的红色来可视化出现高错误的单元格,以引起人们对这些区域的注意。 当不同分区中的错误主题不同时(在实践中经常出现此类情况),此功能特别有用。 在此错误识别视图中,知识或假设指导分析,并帮助你了解哪些功能对于理解失败最为重要。
后续步骤
- 了解如何通过
CLI 和 SDK 或Azure Machine Learning studio UI 。 - 探索受支持的错误分析可视化。
- 了解如何根据在负责任 AI 仪表板中观察到的见解生成负责任 AI 记分卡。