Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: 适用于 Python 的 Azure 机器学习 SDK v1
适用于 Python 的 Azure 机器学习 SDK v1
重要
本文中的一些 Azure CLI 命令使用适用于 Azure 机器学习的 azure-cli-ml 或 v1 扩展。 对 CLI v1 的支持于 2025 年 9 月 30 日结束。 Microsoft将不再为此服务提供技术支持或更新。 使用 CLI v1 的现有工作流将继续在支持终止日期后运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议尽快过渡到 mlv2 扩展。 有关 v2 扩展的详细信息,请参阅 Azure 机器学习 CLI 扩展和 Python SDK v2。
重要
本文提供有关使用 Azure 机器学习 SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure 机器学习 CLI 和 Python SDK v2? 以及 SDK v2 参考。
提示
正在查找当前版本? 本文介绍已弃用的 SDK v1。 有关使用 SDK v2 的当前方法,请参阅 设置 AutoML 以训练计算机视觉模型(v2 )。
本文介绍如何使用 Azure 机器学习 Python SDK 中的自动化机器学习基于图像数据训练计算机视觉模型。
自动化 ML 支持将模型训练用于图像分类、物体检测和实例分段等计算机视觉任务。 目前支持通过 Azure 机器学习 Python SDK 为计算机视觉任务创作 AutoML 模型。 可以从 Azure 机器学习工作室 UI 访问生成的试验运行、模型和输出。 详细了解用于图像数据计算机视觉任务的自动化的机器学习。
注意
只能通过 Azure 机器学习 Python SDK 使用用于计算机视觉任务的自动化 ML。
先决条件
Azure 机器学习工作区。 若要创建工作区,请参阅创建工作区资源。
已安装 Azure 机器学习 Python SDK。 若要安装该 SDK,你可以:
创建一个计算实例,该实例会自动安装 SDK 并已针对 ML 工作流进行预配置。 有关详细信息,请参阅创建和管理 Azure 机器学习计算实例。
自行安装
automl包,其中包括 SDK 默认安装。
注意
SDK v1 AutoML 计算机视觉支持需要 Python 3.7 或 3.8,这两个版本都已停止维护,不再接收安全更新。 对于受支持的Python版本,请使用 SDK v2。
选择任务类型
用于图像的自动化 ML 支持以下任务类型:
| 任务类型 | AutoMLImage 配置语法 |
|---|---|
| 图像分类 | ImageTask.IMAGE_CLASSIFICATION |
| 多标签图像分类 | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| 图像物体检测 | ImageTask.IMAGE_OBJECT_DETECTION |
| 图像实例分割 | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
此任务类型是必需的参数,将使用 task 中的 AutoMLImageConfig 参数来传入。
例如:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
训练和验证数据
若要生成计算机视觉模型,需要以 Azure 机器学习 TabularDataset 的形式引入标记的图像数据作为模型训练的输入。 你可以使用从数据标注项目导出的TabularDataset,或者使用标记的训练数据创建新的TabularDataset。
如果你的训练数据采用不同的格式(例如 pascal VOC 或 COCO),则可以应用示例笔记本中包含的帮助程序脚本,以将数据转换为 JSONL。 详细了解如何使用自动化 ML 为计算机视觉任务准备数据。
警告
仅支持使用 SDK 从 JSONL 格式的数据创建表格数据集来实现这一功能。 目前不支持通过 UI 创建数据集。 目前 UI 无法识别 StreamInfo 数据类型,也就是 JSONL 格式的图像 URL 使用的数据类型。
注意
训练数据集需要至少有 10 张图像才能提交 AutoML 运行。
JSONL 架构示例
TabularDataset 的结构取决于手头的任务。 对于计算机视觉任务类型,它由以下字段组成:
| 字段 | 说明 |
|---|---|
image_url |
包含文件路径作为 StreamInfo 对象 |
image_details |
图像元数据信息由高度、宽度和格式组成。 此字段是可选的,因此可能存在,也可能不存在。 |
label |
图像标签的 json 表示形式,基于任务类型。 |
下面是用于图像分类的示例 JSONL 文件:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
以下代码是用于物体检测的示例 JSONL 文件:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
消费数据
将数据设置为 JSONL 格式后,可使用以下代码创建 TabularDataset:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
自动化 ML 不会对计算机视觉任务的训练或验证数据大小施加任何限制。 最大数据集大小仅受数据集后的存储层(即 Blob 存储)的限制。 图像或标签没有最小数量限制。 但是,我们建议最初为每个标签至少提供 10-15 个样本,以确保输出模型得到充分训练。 标签/类的总数越大,每个标签所需的样本越多。
训练数据是必需的,将使用 training_data 参数来传入。 可以选择性地使用 AutoMLImageConfig 的 validation_data 参数,将另一个 TabularDataset 指定为用于模型的验证数据集。 如果未指定验证数据集,则默认将使用 20% 的训练数据进行验证,除非传递了具有不同值的 validation_size 参数。
例如:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
用于运行试验的计算环境
提供计算目标,以便自动化 ML 执行模型训练。 用于计算机视觉任务的自动化 ML 模型要求使用 GPU SKU 并支持 NC 和 ND 系列。 建议使用 NCsv3 系列(具有 v100 GPU)以加快训练速度。 使用多 GPU VM SKU 的计算目标利用多个 GPU 来加快训练速度。 此外,在设置具有多个节点的计算目标的过程中,可以在优化模型的超参数时,通过并行度来更快地执行模型训练。
计算目标是必需的参数,将使用 compute_target 的 AutoMLImageConfig 参数来传入。 例如:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
配置模型算法和超参数
借助对计算机视觉任务的支持,可以控制模型算法并调整超参数。 这些模型算法和超参数将作为参数空间传入以进行扫描。
模型算法是必需的,将通过 model_name 参数来传入。 可以指定单个 model_name,也可以在多个参数之间进行选择。
支持的模型算法
下表汇总了每个计算机视觉任务支持的模型。
| 任务 | 模型算法 | 字符串字面量语法default_model* 用 * 表示 |
|---|---|---|
| 图像分类 (多类和多标签) |
MobileNet:适用于移动应用程序的轻型模型 ResNet:残差网络 ResNeSt:拆分注意力网络 SE-ResNeXt50:压缩奖惩网络 ViT:视觉变换器网络 |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224(小)vitb16r224*(基本)vitl16r224(大) |
| 对象检测 | YOLOv5:单阶段物体检测模型 Faster RCNN ResNet FPN:双阶段物体检测模型 RetinaNet ResNet FPN:通过焦点损失函数解决类别不平衡问题 注意:有关 YOLOv5 模型大小,请参阅 model_size 超参数。 |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| 实例分割 | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
注意
SDK v2 中提供了其他模型体系结构(HuggingFace、MMDetection)。 请参阅 v2 模型体系结构列表。
除了控制模型算法之外,还可以优化用于模型训练的超参数。 虽然公开的许多超参数与模型无关,但在某些情况下,超参数特定于任务或特定于模型。 详细了解这些实例的可用超参数。
数据增强
一般情况下,深度学习模型的性能通常可以随着数据的增加而提高。 数据增强是一种放大数据集的数据大小和可变性的实用技术,有助于防止过度拟合,并提高模型对不可见数据的泛化能力。 在将输入图像馈送到模型之前,自动化 ML 将根据计算机视觉任务应用不同的数据增强技术。 目前未公开任何超参数来控制数据增强。
| 任务 | 受影响的数据集 | 应用的数据增强技术 |
|---|---|---|
| 图像分类(多类和多标签) | 培训 验证和测试 |
随机调整大小和裁剪、水平翻转、颜色抖动(亮度、对比度、饱和度和色调)、使用通道范围 ImageNet 的平均值和标准偏差进行规范化 调整大小、中心裁剪、归一化 |
| 物体检测、实例分段 | 培训 验证和测试 |
围绕边界框随机裁剪、展开、水平翻转、规范化、调整大小 归一化、调整大小 |
| 使用 yolov5 进行物体检测 | 培训 验证和测试 |
马赛克、随机仿射(旋转、平移、缩放、剪切)、水平翻转 信箱格式调整大小 |
配置试验设置
在执行大规模扫描以搜索最佳模型和超参数之前,我们建议尝试使用默认值来获取第一个基线。 接下来,可以在扫描多个模型及其参数之前探索同一模型的多个超参数。 这样,就可以采用更具迭代性的方法,因为对于多个模型以及每个模型的多个超参数,搜索空间将呈指数增长,因此需要执行更多次的迭代才能找到最佳配置。
如果你希望为给定的算法(例如 yolov5)使用默认超参数值,可按如下所示指定 AutoML 图像运行的配置:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
生成基线模型后,你可能想要优化模型性能,以扫描模型算法和超参数空间。 可使用以下示例配置扫描每个算法的超参数,并从 learning_rate、optimizer、lr_scheduler 等的一系列值中进行选择,以生成具有最佳主要指标的模型。 如果未指定超参数值,则为指定的算法使用默认值。
主要指标
用于模型优化和超参数优化的主要指标取决于任务类型。 目前不支持使用其他主要指标值。
- 适用于 IMAGE_CLASSIFICATION 的
accuracy - 适用于 IMAGE_CLASSIFICATION_MULTILABEL 的
iou - 适用于 IMAGE_OBJECT_DETECTION 的
mean_average_precision - 适用于 IMAGE_INSTANCE_SEGMENTATION 的
mean_average_precision
试验预算
可以选择性地使用 experiment_timeout_hours(试验终止之前的时长,以小时为单位)指定 AutoML 视觉试验的最大时间预算。 如果未指定,则默认试验超时为 7 天(最大值为 60 天)。
扫描模型的超参数
在训练计算机视觉模型时,模型性能在很大程度上取决于所选的超参数值。 你经常需要优化超参数以获得最佳性能。 借助对自动化 ML 中计算机视觉任务的支持,可以扫描超参数以找到模型的最佳设置。 此功能将应用 Azure 机器学习中的超参数优化功能。 了解如何优化超参数。
定义参数搜索空间
可以定义模型算法和超参数,以便在参数空间中扫描。
- 有关每种任务类型支持的模型算法的列表,请参阅配置模型算法和超参数。
- 请参阅计算机视觉任务的超参数,了解每种计算机视觉任务类型的超参数。
- 请参阅关于离散和连续超参数支持的分布的详细信息。
扫描的采样方法
扫描超参数时,需要指定用于扫描所定义的参数空间的采样方法。 目前,hyperparameter_sampling 参数支持以下采样方法:
注意
目前只有随机采样和网格采样支持条件性超参数空间。
提前终止策略
可以使用提前终止策略自动终止性能不佳的运行。 提前终止可提高计算效率,节省原本会花费在不太有效的配置上的计算资源。 用于图像的自动化 ML 支持以下使用 early_termination_policy 参数的提前终止策略。 如果未指定终止策略,则所有配置将运行到完成为止。
详细了解如何为超参数扫描配置提前终止策略。
用于扫描的资源
可以通过为扫描指定 iterations 和 max_concurrent_iterations 来控制在超参数扫描上花费的资源。
| 参数 | 详细信息 |
|---|---|
iterations |
扫描最大数量的配置所需的参数。 必须是介于 1 到 1000 之间的整数。 仅探索给定模型算法的默认超参数时,请将此参数设置为 1。 |
max_concurrent_iterations |
最大可并发运行的次数。 如果未指定此项,所有运行都将并行启动。 如果指定了此项,则必须是 1 和 100 之间的整数。 注意:并发运行数根据指定计算目标中的可用资源进行限制。 请确保计算目标能够为所需的并发性提供足够的可用资源。 |
注意
有关完整的扫描配置示例,请参阅此教程。
参数
可以将在参数空间扫描期间不会更改的固定设置或参数作为自变量进行传递。 自变量以名称-值对的形式传递,名称必须以双短划线作为前缀。
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
增量训练(可选)
训练运行完成后,可以选择通过加载已训练的模型检查点来进一步训练模型。 可以使用同一数据集或不同数据集进行增量训练。
有两个可用于增量训练的选项。 你可以
- 传递要从中加载检查点的运行 ID。
- 通过 FileDataset 传递检查点。
通过运行 ID 完成检查点
若要根据所需模型查找运行 ID,可以使用以下代码。
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
若要通过运行 ID 传递检查点,需要使用 checkpoint_run_id 参数。
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
通过 FileDataset 传递检查点
若要通过 FileDataset 传递检查点,需要使用 checkpoint_dataset_id 和 checkpoint_filename 参数。
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
提交运行任务
准备好 AutoMLImageConfig 对象后,可以提交试验。
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
输出和评估指标
自动化 ML 训练任务生成的成果包括输出模型文件、评估指标、日志和部署工件,如评分文件和环境文件,这些文件可以从子任务的输出、日志和指标选项卡中查看。
提示
在查看运行结果部分查看如何导航到作业结果。
有关为每次运行提供的性能图表和指标的定义和示例,请参阅评估自动化机器学习试验结果
注册和部署模型
运行完成后,可以注册从最佳运行(产生了最佳主要指标的配置)创建的模型
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
注册要使用的模型后,可将其部署为 Azure 容器实例 (ACI) 或 Azure Kubernetes 服务 (AKS) 上的 Web 服务。 ACI 是测试部署的完美选择,而 AKS 更适合大规模生产使用。
此示例将模型部署为 AKS 中的 Web 服务。 若要在 AKS 中部署,请先创建 AKS 计算群集或使用现有的 AKS 群集。 可为部署群集使用 GPU 或 CPU VM SKU。
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC4AS_T4_V3",
location="chinaeast2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
接下来,可以定义描述如何设置包含模型的 Web 服务的推理配置。 可以在推理配置中使用训练运行中的评分脚本和环境。
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
然后,可将模型部署为 AKS Web 服务。
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
或者,可以从 Azure 机器学习工作室 UI 部署模型。 在自动化 ML 运行的“模型”选项卡中导航到要部署的模型,然后选择“部署” 。
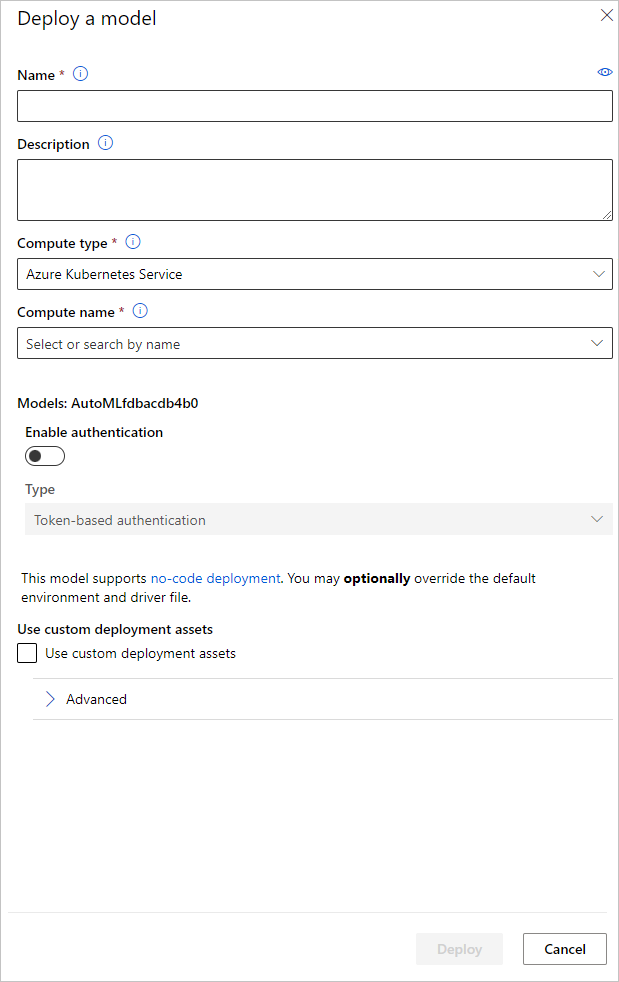
可以在“部署模型”窗格中配置模型部署所用的部署终结点名称和推理群集。
更新推理配置
在上一步骤中,我们已将最佳模型中的评分文件 outputs/scoring_file_v_1_0_0.py 下载到了本地 score.py 文件,并使用它创建了 InferenceConfig 对象。 在下载此脚本之后、创建 InferenceConfig 之前,可根据需要修改此脚本,以更改特定于模型的推理设置。 例如,下面是在评分文件中初始化模型的代码部分:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
每个任务(和某些模型)在 model_settings 字典中都有一组参数。 默认情况下,我们将为参数使用在训练和验证期间所用的相同值。 根据使用模型进行推理时所需的行为,我们可以更改这些参数。 在下面可以找到每个任务类型和模型的参数列表。
| 任务 | 参数名称 | 默认 |
|---|---|---|
| 图像分类(多类和多标签) | valid_resize_sizevalid_crop_size |
256 224 |
| 对象检测 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
使用 yolov5 进行物体检测 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 中 0.1 0.5 |
| 实例分割 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 假 JPG |
有关特定于任务的超参数的详细说明,请参阅自动化机器学习中计算机视觉任务的超参数。
如果你要使用平铺并想要控制平铺行为,可使用以下参数:tile_grid_size、tile_overlap_ratio 和 tile_predictions_nms_thresh。 有关这些参数的更多详细信息,请查看使用 AutoML 训练小物体检测模型。
示例笔记本
查看用于自动化机器学习的 GitHub 笔记本存储库示例中的详细代码示例和用例。 检查具有“image-”前缀的文件夹,以获取特定于生成计算机视觉模型的示例。