Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
使用批处理终结点,可以部署模型以大规模执行长期推理。 部署模型时,必须创建和指定评分脚本(也称为 批处理驱动程序脚本),以指示如何使用模型通过输入数据创建预测。 本文介绍如何在不同方案中在模型部署中使用评分脚本。 你还将了解批处理终结点的最佳实践。
提示
MLflow 模型不需要评分脚本。 服务会为你自动生成它。 有关批处理终结点如何与 MLflow 模型配合工作的详细信息,请参阅专门的教程在批处理部署中使用 MLflow 模型。
警告
若要在批处理终结点下部署自动化 ML 模型,请注意,自动化 ML 提供仅适用于联机终结点的评分脚本。 该评分脚本不用于批处理执行。 有关如何创建为模型定制的评分脚本的详细信息,请参阅以下指南。
了解评分脚本
评分脚本是一个 Python 文件(.py),指定如何运行模型并读取批处理部署执行程序提交的输入数据。 每个模型部署都在创建时提供评分脚本(以及其他所有必需的依赖项)。 评分脚本通常如下所示:
评分脚本必须包含两个方法:
init 方法
init() 方法用于任何成本较高的或者一般性的准备工作。 例如,使用它将模型加载到内存中。 整个批处理作业开始时会调用该函数一次。 模型的文件在环境变量 AZUREML_MODEL_DIR 确定的路径中可用。 根据模型注册方式,其文件可能包含在文件夹中。 在下一个示例中,模型在一个名为 model 的文件夹中有多个文件。 有关详细信息,请访问如何确定模型使用的文件夹。
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
在此示例中,将模型置于全局变量 model中。 若要提供对评分函数执行推理所需的资产,请使用全局变量。
run 方法
使用 run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] 方法处理批处理部署生成的每个小型批处理的评分。 对于为输入数据生成的每个 mini_batch,会调用这种方法一次。 批处理部署根据配置部署的方式分批读取数据。
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
该方法接收文件路径列表作为参数 (mini_batch)。 可以使用此列表循环访问并逐个处理每个文件,或读取整个批处理并一次性处理所有文件。 最佳选择取决于计算内存和需要实现的吞吐量。 有关描述如何一次性读取整个数据批的示例,请访问高吞吐量部署。
注意
工作是如何分布的?
批处理部署在文件级别分配工作,这意味着,如果某个文件夹包含 100 个文件并以 10 个文件为一个微批,则会生成 10 个批,每批包含 10 个文件。 请注意,相关文件的大小没有相关性。 对于文件太大而无法以大型小型批处理进行处理,请将文件拆分为较小的文件,以实现更高的并行度,或减少每个小型批处理的文件数。 目前,批处理部署无法处理文件大小分布的偏差。
run() 方法应返回 Pandas DataFrame 或数组/列表。 每个返回的输出元素指示输入 mini_batch 中成功运行一次输入元素。 对于文件或文件夹数据资产,返回的每个行/元素表示已处理的单个文件。 对于表格数据资产,返回的每个行/元素表示已处理的文件中的一行。
重要
如何写入预测?
函数 run() 返回的所有内容都追加到批处理作业生成的输出预测文件中。 必须从此函数返回正确的数据类型。 需要输出单个预测时,请返回数组。 需要返回多条信息时,请返回 pandas 数据帧。 例如,对于表格数据,你可能希望将预测追加到原始记录。 使用 pandas 数据帧执行此操作。 尽管 pandas DataFrame 可能包含列名称,但输出文件不包含这些名称。
若要以不同的方式编写预测,可以在 批处理部署中自定义输出。
警告
在 run 函数中,不要输出 pandas.DataFrame 之外的复杂数据类型(或复杂数据类型的列表)。 这些输出将转换为字符串,并且难以读取。
生成的数据帧或数组将追加到指示的输出文件中。 对结果的基数没有要求。 一个文件可以在输出中生成一个或多个行/元素。 结果数据帧或数组中的所有元素会按原样写入输出文件(假设 output_action 不是 summary_only)。
用于评分的 Python 包
需要在运行批处理部署的环境中指明你的评分脚本需要运行的任何库。 对于评分脚本,为每个部署指定环境。 通常要使用 conda.yml 依赖项文件指明你的要求,该文件可能如下所示:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
以不同的方式编写预测
默认情况下,批处理部署会将模型的预测写入部署中所示的单个文件中。 但是,在某些情况下,必须在多个文件中编写预测。 例如,对于分区输入数据,您可能还希望生成分区输出。 在此类情况下,可以在批处理部署中自定义输出以指示:
- 用于编写预测的文件格式(CSV、parquet、json 等)
- 数据在输出中的分区方式
有关详细信息,请参阅 自定义批量部署中的输出。
评分脚本的源代码管理
将评分脚本放在源代码管理下。
编写评分脚本的最佳做法
编写处理大量数据的评分脚本时,请考虑多种因素,包括
- 每个文件的大小
- 每个文件中的数据量
- 读取每个文件所需的内存量
- 读取整批文件所需的内存量
- 模型的内存占用情况
- 在输入数据上运行时模型内存占用量
- 计算中的可用内存
批处理部署在文件级别分发工作。 此分配意味着一个包含 100 个文件的文件夹以 10 个文件为小批处理单元,生成 10 批 10 个文件(无论涉及的文件大小如何)。 对于文件太大而无法以大型小型批处理进行处理,请将文件拆分为较小的文件,以实现更高的并行度,或减少每个小型批处理的文件数。 目前,批处理部署无法考虑文件大小分布中的偏差。
并行度与评分脚本之间的关系
部署配置控制每个微批的大小以及每个节点上的辅助进程数量。 当决定是否读取整个小型批处理以执行推理、按文件逐个运行推理,还是逐行运行推理时(对于表格),此配置很重要。 有关详细信息,请参阅 在小型批处理、文件或行级别运行推理。
在同一实例上运行多个辅助角色时,请记住所有辅助角色共享内存。 如果增加每个节点的工作者数量,那么通常应该减少小批量大小;或者,如果数据大小和计算 SKU 保持不变,则更改评分策略。
在迷你批次、文件或行级别运行推理
批处理终结点将在每个微批中调用一次评分脚本中的 run() 函数。 但是,你可以决定是要对整个批处理运行推理,一次运行一个文件,还是一次运行一行表格数据。
微批级别
通常通过整个批处理运行推理计算,以在批处理评估过程中实现高吞吐量。 如果通过 GPU 运行推理,而你希望使推理设备饱和,则此方法非常有效。 如果数据不适合内存,您可能还会依赖于自动批处理数据加载程序,例如TensorFlow或PyTorch数据加载程序。 在这些情况下,你将对整个批处理运行推理。
警告
在批处理级别运行推理可能需要密切控制输入数据大小,以便能准确衡量内存要求并避免出现内存不足异常。 能否在内存中加载整个微批取决于微批的大小、群集中实例的大小以及每个节点上的辅助进程数量。
不妨访问高吞吐量部署,了解如何实现此目的。 此示例一次处理整批文件。
文件级别
执行推理的最简单方法是循环访问小型批处理中的所有文件,然后对每个文件运行模型。 在某些情况下,例如图像处理,此方法非常有效。 对于表格数据,需要估计每个文件中的行数。 此估计显示模型是否可以处理内存要求,以便将整个数据加载到内存中,并对其进行推理。 一些模型(尤其是基于反复神经网络的模型)会展开并呈现内存占用,并具有潜在的非线性行计数。 对于内存费用较高的模型,请考虑在行级别运行推理。
提示
请考虑将过大的文件拆分为多个较小的文件,以提高并行处理效率。
若要了解如何执行此操作,请访问使用批处理部署进行图像处理。 此示例一次处理一个文件。
行级别(表格)
对于在输入大小方面存在挑战的模型,可以考虑在行级别运行推理。 批处理部署仍为评分脚本提供一批小型文件。 但是,你读取一个文件,一次一行。 这种方法似乎效率低下,但对于一些深度学习模型,这样做可能是在不纵向扩展硬件资源的情况下执行推理的唯一方法。
若要了解如何执行此操作,请访问使用批处理部署进行文本处理。 此示例一次处理一行。
使用作为文件夹的模型
AZUREML_MODEL_DIR环境变量包含所选模型位置的路径。 该 init() 函数通常用于将模型加载到内存中。 但是,某些模型可能包含其文件在文件夹中,在加载它们时可能需要考虑该结构。 可按如下所示确定模型的文件夹结构:
转到 Azure 机器学习工作室门户。
转到“模型”部分。
选择要部署的模型,然后选择“项目”选项卡。
记下显示的文件夹。 注册模型时指定此文件夹。
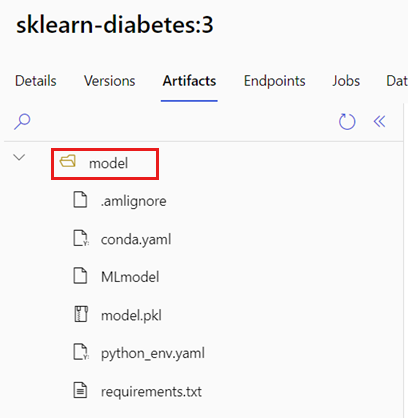

使用此路径加载模型:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)