Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
在 Azure 机器学习中,了解如何创建和运行数据标记项目以标记文本数据。 指定要应用于每个文本项的单个或多个标签。
还可以使用 Azure 机器学习中的数据标记工具创建图像标记项目。
文本标记功能
Azure 机器学习数据标记是可用于创建、管理和监视数据标记项目的工具。 使用它可执行以下操作:
- 可以协调数据、标签和团队成员,以有效地管理标记任务。
- 跟踪进度并维护未完成标记任务的队列。
- 启动和停止项目并控制标记进度。
- 检查已标记的数据,并将其导出为 Azure 机器学习数据集。
重要
在 Azure 机器学习数据标记工具中处理的文本数据必须在 Azure Blob 存储数据存储中可用。 如果没有现有的数据存储,则可以在创建项目时将数据文件上传到新的数据存储。
以下数据格式可用于文本数据:
- .txt:每个文件表示一个要标记的项。
- .csv 或 .tsv:每一行表示一个呈现给标记人员的项。 你可以决定标记人员在标记行时可查看哪些列。
先决条件
使用以下项目在 Azure 机器学习中设置文本标记:
- 本地文件或 Azure Blob 存储中要标记的数据。
- 要应用的一组标签。
- 标记说明。
- Azure 订阅。 如果没有 Azure 订阅,可在开始前创建一个试用帐户。
- Azure 机器学习工作区。 请参阅创建 Azure 机器学习工作区。
创建文本标记项目
标记项目是在 Azure 机器学习中管理的。 使用机器学习中的“数据标记”页来管理项目。
如果数据已在 Azure Blob 存储中,则在创建标记项目之前,确保以数据存储的形式提供这些数据。
若要创建项目,请选择“添加项目”。
对于“项目名称”,请输入项目的名称。
即使删除了项目,也无法重复使用项目名称。
若要创建文本标记项目,请为“媒体类型”选择“文本”。
对于“标记任务类型”,请选择适用于你的方案的选项:
- 若要仅将单个标签应用于一组标签中的每段文本,请选择“多类文本分类”。
- 若要将一个或多个标签应用于一组标签中的每段文本,请选择“多标签文本分类”。
- 若要将标签应用于单个文本单词或每个条目中的多个文本单词,请选择“文本命名实体识别”。
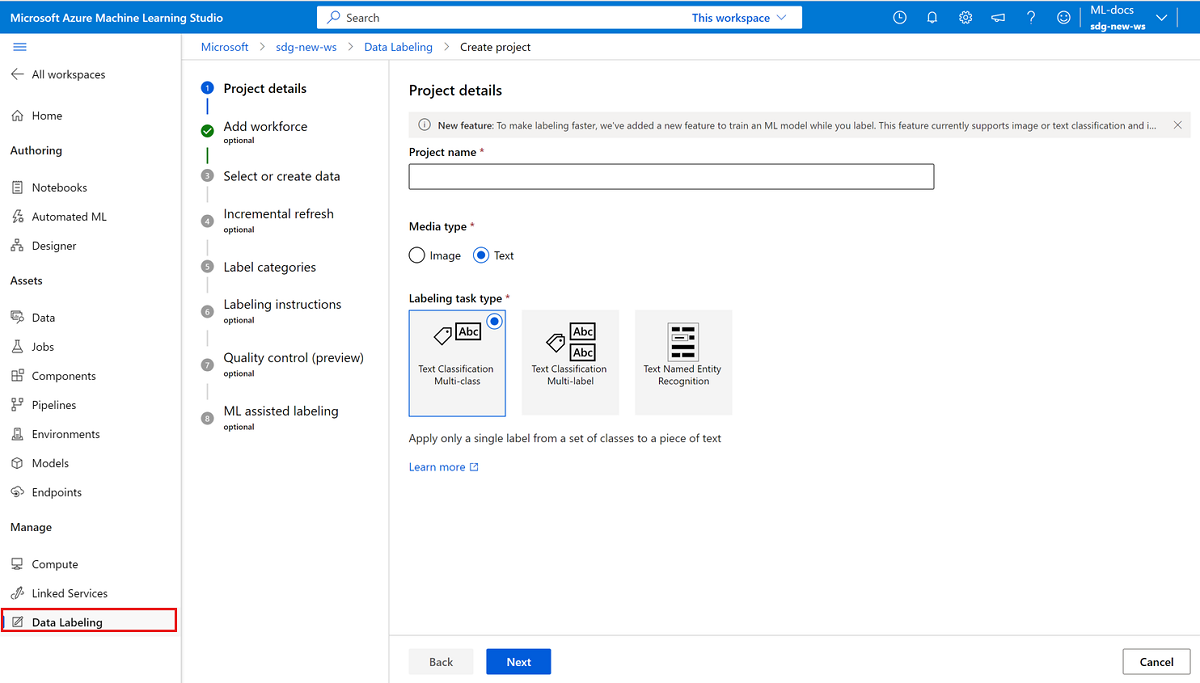
选择“下一步”继续操作。
添加工作人员(可选)
只有当你已从 Azure 市场中使用数据标签公司时,才需要选择“使用来自 Azure 市场的供应商标签公司”。 然后选择供应商。 如果列表中未显示你的供应商,请清除此选项。
请确保首先与供应商联系并签署合同。 有关详细信息,请参阅与数据标签供应商公司协作(预览版)。
选择“下一步”继续操作。
选择或创建数据集
如果已创建包含数据的数据集,请从“选择现有数据集”下拉菜单中它。 还可以选择“创建数据集”以使用现有的 Azure 数据存储或上传本地文件。
注意
一个项目最多可包含 500,000 个文件。 如果数据集超过了此文件数限制,则只加载前 500,000 个文件。
从 Azure 数据存储创建数据集
在许多情况下,可以上传本地文件。 但是,使用 Azure 存储资源管理器可以更快、更可靠地传输大量数据。 建议将存储资源管理器用作移动文件的默认方式。
若要基于已存储在 Azure Blob 存储中的数据创建数据集,请执行以下操作:
- 选择“创建”。
- 对于“名称”,输入数据集的名称。 (可选)输入说明。
- 选择“数据集类型”:
- 如果使用的是 .csv 或 .tsv 文件,并且每行都包含一个响应,请选择“表格”。
- 如果对每个响应使用单独的 .txt 文件,请选择“文件”。
- 选择“下一步”。
- 选择“从 Azure 存储”,然后选择“下一步”。
- 选择数据存储,然后选择“下一步”。
- 如果数据位于 Blob 存储中的子文件夹中,请选择“浏览”以选择相应的路径。
- 若要包括所选路径的子文件夹中的所有文件,请将
/**追加到路径中。 - 若要包括当前容器及其子文件夹中的所有数据,请将
**/*.*追加到路径中。
- 若要包括所选路径的子文件夹中的所有文件,请将
- 选择“创建”。
- 选择创建的数据资产。
基于上传的数据创建数据集
若要直接上传数据:
- 选择“创建”。
- 对于“名称”,输入数据集的名称。 (可选)输入说明。
- 选择“数据集类型”:
- 如果使用的是 .csv 或 .tsv 文件,并且每行都包含一个响应,请选择“表格”。
- 如果对每个响应使用单独的 .txt 文件,请选择“文件”。
- 选择“下一步”。
- 选择“从本地文件”,然后选择“下一步”。
- (可选)选择一个数据存储。 默认值将上传到机器学习工作区的默认 Blob 存储 (workspaceblobstore)。
- 选择“下一页”。
- 选择“上传”>“上传文件”或“上传”>“上传文件夹”,以选择要上传的本地文件或文件夹。
- 在浏览器窗口中查找文件或文件夹,然后选择“打开”。
- 继续选择“上传”,直到指定所有文件和文件夹。
- (可选)选中“覆盖(如果已存在)”复选框。 验证文件和文件夹的列表。
- 选择“下一页”。
- 确认详细信息。 选择“后退”以修改设置,或选择“创建”以创建数据集。
- 最后,选择创建的数据资产。
配置增量刷新
如果打算向数据集添加新的数据文件,请使用增量刷新将这些文件添加到项目。
如果已设置“启用定期增量刷新”,则将根据标记完成率定期检查数据集,以将新文件添加到项目。 项目包含的文件达到最大数 500,000 时,新数据检查将停止。
如果希望项目持续监视数据存储中的新数据,请选择“启用定期增量刷新”。
如果不希望数据存储中的新文件自动添加到项目,请清除该选择。
重要
启用增量刷新后,请勿为要更新的数据集创建新版本。 如果这样做,将看不到更新,因为数据标记项目已固定到初始版本。 请改用 Azure 存储资源管理器在 Blob 存储中修改相应文件夹中的数据。
此外,请勿移除数据。 从项目使用的数据集中移除数据会导致项目中出现错误。
创建项目后,使用“详细信息”选项卡更改增量刷新,查看上次刷新的时间戳,并请求立即刷新数据。
注意
使用表格(.csv 或 .tsv)数据集输入的项目可以使用增量刷新。 但增量刷新只会添加新的表格文件。 刷新操作无法识别对现有表格文件的更改。
指定标签类别
在“标签类别”页上,指定类集以对数据进行分类。
标记人员能否在类中进行选择会影响其准确性和速度。 例如,不要拼写出植物或动物的完整属类和物种,而是使用字段代码或者将属类缩写。
可以使用简单列表或创建标签组。
要创建平面列表,请选择“添加标签类别”以创建每个标签。
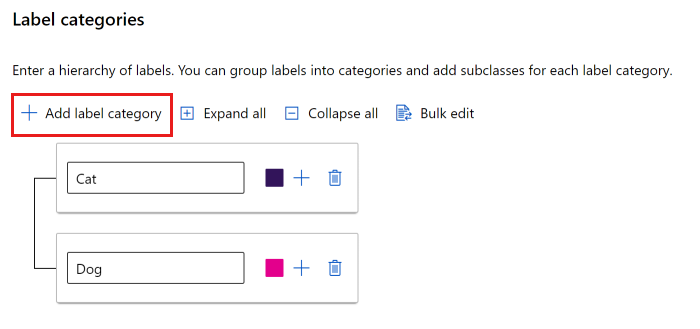
若要在不同的组中创建标签,请选择“添加标签类别”以创建顶级标签。 然后,选择每个顶级下的加号 (+),为该类别创建下一级别的标签。 最多可以为任何分组创建 6 个级别。
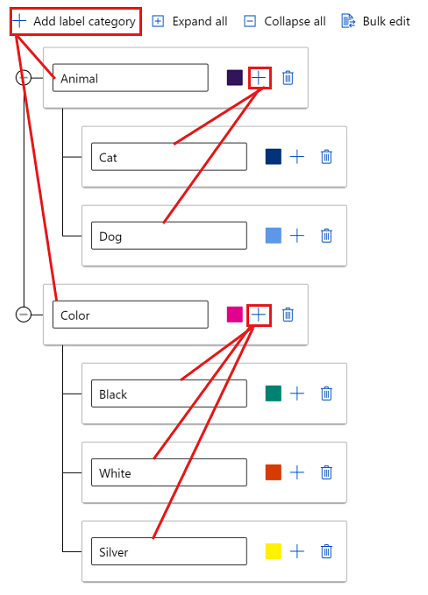
在标记过程中,可以选择任何级别的标签。 例如,标签 Animal、Animal/Cat、Animal/Dog、Color、Color/Black、Color/White 和 Color/Silver 都是标签的可用选项。 在多标签项目中,无需从每个类别中选择一个。 如果你打算这样做,请确保在说明中包含此信息。
说明文本标记任务
清楚地解释标记任务非常重要。 在“标记说明”页上,可以添加包含标记说明的外部站点的链接,也可以在该页上的编辑框中提供说明。 让说明面向任务并适合受众。 请考虑以下问题:
- 标记人员将看到哪些标签,他们如何在标签之间进行选择? 是否提供了参考文本?
- 如果没有合适的标签,应该怎么办?
- 如果没有合适的多个标签,应该怎么办?
- 他们应当向标签应用什么置信度阈值? 如果标记人员不确定,是否需要“最佳推测”?
- 他们应该如何处理部分封闭或重叠的相关对象?
- 如果某个相关对象被图像边缘剪裁,应该怎么办?
- 如果他们在提交标签后认为自己犯了错误,应该怎么办?
- 如果他们发现图像质量问题(包括照明条件不佳、反光、失焦、不希望包括的背景、相机角度异常等),该怎么处理?
- 如果多个审阅者对应用标签有不同的意见,他们该怎么办?
注意
标记人员可以使用数字键 1 到 9 选择前 9 个标签。
质量控制(预览版)
若要获取更准确的标签,请使用“质量控制”页将每个项发送给多个标记工具。
重要
共识标记目前以公共预览版提供。
该预览版在提供时没有附带服务级别协议,建议不要将其用于生产工作负载。 某些功能可能不受支持或者受限。
有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
若要将每个项发送到多个标记人员,请选择“启用共识标签(预览版)”。 然后,设置“最小标记人员数量”和“最大标记人员数量”的值以指定要使用的标记人员数量。 确保可用标记人员数量与最大数量一样多。 项目启动后无法更改这些设置。
如果使用最小标记工具数量能够达成共识,则会标记该项。 如果无法达成共识,则会将该项发送给更多标记人员。 如果将项发送给最大数量的标记人员后未能达成共识,则其状态将更改为“需要评审”,需由项目所有者负责标记该项。
使用 ML 辅助数据标记
为了加速完成标记任务,在“ML 辅助标记”页中可以触发自动机器学习模型。 机器学习 (ML) 辅助标记可处理文件 (.txt) 和表格 (.csv) 文本数据输入。
使用 ML 辅助标记:
- 选择“启用 ML 辅助标记”。
- 为项目选择数据集语言。 此列表显示 TextDNNLanguages 类支持的所有语言。
- 指定要使用的计算目标。 如果工作区中没有计算目标,则此步骤会创建一个计算群集,并将它添加到工作区。 创建的群集最少有 0 个节点,在不使用时不会花费任何成本。
有关 ML 辅助标记的详细信息
在标记项目的开头,项将按随机顺序排列,以减少潜在的偏差。 但是,训练的模型会反映数据集中存在的任何偏差。 例如,如果 80% 的项属于单个类,则用于训练模型的大约 80% 的数据属于该类。
为了训练 ML 辅助标记使用的文本 DNN 模型,每个训练示例的输入文本限制为文档中大约前 128 个单词。 对于表格输入,在应用此限制之前,将连接所有文本列。 施加此实用限制是为了在合理的时长内完成模型训练。 文档(用于文件输入)或一组文本列(用于表格输入)中的实际文本可超过 128 个单词。 该限制仅适用于训练过程中模型在内部使用的内容。
启动辅助标记所需的标记项数不是固定数字。 此数目可能根据标记项目的不同而有很大的差异。 该差异取决于许多因素,包括标签类的数量和标签分布。
使用共识标记时,共识标签用于训练。
由于最终的标签仍依赖于标记人员的输入,因此,此技术有时称为“人机回圈”标记。
注意
ML 辅助数据标记不支持虚拟网络后面保护的默认存储帐户。 对于 ML 辅助数据标记,必须使用非默认存储帐户。 可在虚拟网络后面保护非默认存储帐户。
预标记
提交足够的标签用于训练后,已训练的模型将用于预测标记。 标记人员现在会看到一些页面,其中显示每个项上存在的预测标签。 该任务随后涉及审查这些预测,并更正任何错误标记的项,然后提交页面。
在基于手动标记的数据训练机器学习模型后,将在手动标记项的测试集上评估该模型。 评估有助于确定模型在不同置信度阈值下的准确性。 评估过程会设置置信度阈值,如果超过该阈值,则表示模型足够准确,可以显示预先标签。 然后,将会根据未标记的数据评估模型。 预测结果的置信度高于此阈值的项将用于预先标记。
初始化文本标记项目
在初始化标记项目后,项目的某些方面是不可变的。 无法更改任务类型或数据集。 可以修改任务说明的标签和 URL。 请在创建项目之前仔细检查设置。 提交项目后,将返回到“数据标记”概述页,其中显示项目状态为“正在初始化”。
注意
概述页面可能不会自动刷新。 暂停后,手动刷新页面会看到项目状态为“已创建”。
疑难解答
有关创建项目或访问数据时出现的问题,请参阅排查数据标签问题。