Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.

在本文中,你将了解如何在 Azure 机器学习 SDK 和 Azure 机器学习设计器中对在运行机器学习管道时出现的错误进行故障排除。
故障排除提示
下表包含管道开发期间出现的一些常见问题,以及可能的解决方法。
| 问题 | 可能的解决方法 |
|---|---|
无法将数据传递给 PipelineData 字典 |
确保已在脚本中创建了一个目录,该目录对应于管道预期步骤要将数据输出到的位置。 大多数情况下,输入参数将定义输出目录,然后你需要显式创建该目录。 使用 os.makedirs(args.output_dir, exist_ok=True) 创建输出目录。 有关演示此设计模式的评分脚本示例,请参阅该教程。 |
| 依赖项 bug | 如果在远程管道中看到在本地测试时未发生的依赖项错误,请确认远程环境依赖项和版本与测试环境中的依赖项和版本匹配。 请参阅生成、缓存和重复使用环境 |
| 计算目标出现不明确的错误 | 请尝试删除并重新创建计算目标。 重新创建计算目标是很快的,并且可以解决某些暂时性问题。 |
| 管道未重复使用步骤 | 默认已启用步骤重复使用,但是,请确保未在管道步骤中禁用它。 如果已禁用重复使用,则步骤中的 allow_reuse 参数将设置为 False。 |
| 管道不必要地重新运行 | 为了确保步骤只在其基础数据或脚本发生更改时才重新运行,请分离每个步骤的源代码目录。 如果对多个步骤使用同一个源目录,则可能会遇到不必要的重新运行。 在管道步骤对象中使用 source_directory 参数以指向该步骤的隔离目录,并确保未对多个步骤使用同一个 source_directory 路径。 |
| 在训练时期或其他循环行为中逐步减速 | 尝试将任何文件写入操作(包括日志记录)从 as_mount() 切换到 as_upload()。 “装载”模式使用远程虚拟化文件系统,在每次将文件追加到该系统时上传整个文件。 |
| 计算目标启动时间过长 | 用于计算目标的 Docker 映像是从 Azure 容器注册表 (ACR) 加载的。 在默认情况下,Azure 机器学习会创建一个使用“基本”服务层级的 ACR。 将工作区的 ACR 更改为“标准”或“高级”层级可能会减少生成和加载映像所需的时间。 有关详细信息,请参阅 Azure 容器注册表服务层级。 |
身份验证错误
如果通过远程作业对某个计算目标执行管理操作,会收到以下错误之一:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
例如,如果尝试通过一个为实施远程执行操作而提交的机器学习管道创建或附加计算目标,会收到错误。
对 ParallelRunStep 进行故障排除
ParallelRunStep 的脚本必须包含两个函数:
init():此函数适用于后续推理的任何成本高昂或常见的准备工作。 例如,使用它将模型加载到全局对象。 此函数将在进程开始时调用一次。run(mini_batch):将针对每个mini_batch实例运行此函数。mini_batchParallelRunStep将调用 run 方法,并将列表或 pandasDataFrame作为参数传递给该方法。 如果输入是FileDataset,则 mini_batch 中的每个条目都将是文件路径;如果输入是TabularDataset,则是 pandasDataFrame。response:run() 方法应返回 pandasDataFrame或数组。 对于 append_row output_action,这些返回的元素将追加到公共输出文件中。 对于 summary_only,将忽略元素的内容。 对于所有的输出操作,每个返回的输出元素都指示输入微型批处理中输入元素的一次成功运行。 确保运行结果中包含足够的数据,以便将输入映射到运行输出结果。 运行输出将写入输出文件中,并且不保证按顺序写入,你应使用输出中的某个键将其映射到输入。
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
如果推理脚本所在的同一目录中包含另一个文件或文件夹,可以通过查找当前工作目录来引用此文件或文件夹。
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
ParallelRunConfig 的参数
ParallelRunConfig 是 ParallelRunStep 实例在 Azure 机器学习管道中的主要配置。 使用它来包装脚本并配置所需的参数,包括所有以下条目:
entry_script:作为将在多个节点上并行运行的本地文件路径的用户脚本。 如果source_directory存在,则使用相对路径。 否则,请使用计算机上可访问的任何路径。mini_batch_size:传递给单个run()调用的微型批处理的大小。 (可选;默认值对于FileDataset是10个文件,对应TabularDataset是1MB。)- 对于
FileDataset,它是最小值为1的文件数。 可以将多个文件合并成一个微型批处理。 - 对于
TabularDataset,它是数据的大小。 示例值为1024、1024KB、10MB和1GB。 建议值为1MB。TabularDataset中的微批永远不会跨越文件边界。 例如,如果你有各种大小的 .csv 文件,最小的文件为 100 KB,最大的文件为 10 MB。 如果设置mini_batch_size = 1MB,则大小小于 1 MB 的文件将被视为一个微型批处理。 大小大于 1 MB 的文件将被拆分为多个微型批处理。
- 对于
error_threshold:在处理过程中应忽略的TabularDataset记录失败数和FileDataset文件失败数。 如果整个输入的错误计数超出此值,则作业将中止。 错误阈值适用于整个输入,而不适用于发送给run()方法的单个微型批处理。 范围为[-1, int.max]。-1部分指示在处理过程中忽略所有失败。output_action:以下其中一个值指示将如何整理输出:summary_only:用户脚本将存储输出。ParallelRunStep仅将输出用于错误阈值计算。append_row:对于所有输入,仅在输出文件夹中创建一个文件来追加所有按行分隔的输出。
append_row_file_name:用于自定义 append_row output_action 的输出文件名(可选;默认值为parallel_run_step.txt)。source_directory:文件夹的路径,这些文件夹包含要在计算目标上执行的所有文件(可选)。compute_target:仅支持AmlCompute。node_count:用于运行用户脚本的计算节点数。process_count_per_node:每个节点的进程数。 最佳做法是设置为一个节点具有的 GPU 或 CPU 数量(可选;默认值为1)。environment:Python 环境定义。 可以将其配置为使用现有的 Python 环境或设置临时环境。 定义还负责设置所需的应用程序依赖项(可选)。logging_level:日志详细程度。 递增详细程度的值为:WARNING、INFO和DEBUG。 (可选;默认值为INFO)run_invocation_timeout:run()方法调用超时(以秒为单位)。 (可选;默认值为60)run_max_try:微型批处理的run()的最大尝试次数。 如果引发异常,则run()失败;如果达到run_invocation_timeout,则不返回任何内容(可选;默认值为3)。
可以指定 mini_batch_size、node_count、process_count_per_node、logging_level、run_invocation_timeout 和 run_max_try 作为 PipelineParameter 以便在重新提交管道运行时,可以微调参数值。 在此示例中,对 mini_batch_size 和 Process_count_per_node 使用 PipelineParameter,并在稍后重新提交运行时更改这些值。
用于创建 ParallelRunStep 的参数
使用脚本、环境配置和参数创建 ParallelRunStep。 将已附加到工作区的计算目标指定为推理脚本的执行目标。 使用 ParallelRunStep 创建批处理推理管道步骤,该步骤采用以下所有参数:
name:步骤的名称,但具有以下命名限制:唯一、3-32 个字符和正则表达式 ^[a-z]([-a-z0-9]*[a-z0-9])?$。parallel_run_config:ParallelRunConfig对象,如前文所述。inputs:要分区以进行并行处理的一个或多个单类型 Azure 机器学习数据集。side_inputs:无需分区就可以用作辅助输入的一个或多个参考数据或数据集。output:与输出目录相对应的OutputFileDatasetConfig对象。arguments:传递给用户脚本的参数列表。 使用 unknown_args 在入口脚本中检索它们(可选)。allow_reuse:当使用相同的设置/输入运行时,该步骤是否应重用以前的结果。 如果此参数为False,则在管道执行过程中将始终为此步骤生成新的运行。 (可选;默认值为True。)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
调试方法
调试管道有三种主要方法:
- 在本地计算机上调试单个管道步骤
- 使用日志记录和 Application Insights 来隔离并诊断问题根源
- 将远程调试器附加到 Azure 中运行的管道
在本地调试脚本
管道中最常见的失败情形之一是,域脚本未按预期运行,或者在难以调试的远程计算上下文中包含运行时错误。
管道本身无法在本地运行,但在本地计算机上的隔离位置运行脚本可以更快地进行调试,因为无需等待计算和环境生成过程完成。 执行此操作需要完成一些开发工作:
- 如果数据位于云数据存储中,则需要下载数据并使其可供脚本使用。 使用较小的数据样本能够很好地在运行时减少系统开销,并快速获取有关脚本行为的反馈
- 如果你正在尝试模拟某个中间管道步骤,可能需要手动生成特定脚本预期前一步骤提供的对象类型
- 还需要定义自己的环境,并复制远程计算环境中定义的依赖项
在本地环境中运行脚本安装后,执行如下所述的调试任务就会容易得多:
- 附加自定义调试配置
- 暂停执行和检查对象状态
- 捕获运行时之前不会公开的类型或逻辑错误
提示
确认脚本按预期运行后,合理的下一步是在单步管道中运行该脚本,然后尝试在包含多个步骤的管道中运行该脚本。
配置、写入和查看管道日志
在开始生成管道之前,在本地测试脚本是调试主要代码段和复杂逻辑的适当方式,但在某个时间点,你可能需要在执行实际管道运行本身期间调试脚本,尤其是在诊断与管道步骤交互期间发生的行为时。 我们建议在步骤脚本中充分使用 print() 语句,以便可以查看远程执行期间的对象状态和预期值,就像在调试 JavaScript 代码时一样。
日志记录选项和行为
下表提供了针对管道的各个调试选项的信息。 这不是一个详尽的列表,因为除了此处显示的 Azure 机器学习、Python 和 OpenCensus 以外,还有其他选项。
| 库 | 类型 | 示例 | 目标 | 资源 |
|---|---|---|---|---|
| Azure 机器学习 SDK | 指标 | run.log(name, val) |
Azure 机器学习门户 UI | 如何跟踪试验 azureml.core.Run 类 |
| Python 打印/日志记录 | 日志 | print(val)logging.info(message) |
驱动程序日志、Azure 机器学习设计器 | 如何跟踪试验 Python 日志记录 |
| OpenCensus Python | 日志 | logger.addHandler(AzureLogHandler())logging.log(message) |
Application Insights - 跟踪 | 在 Application Insights 中调试管道 OpenCensus Azure Monitor Exporters(OpenCensus Azure Monitor 导出程序) Python 日志记录指南 |
日志记录选项示例
import logging
from azureml.core.run import Run
from opencensus.ext.azure.log_exporter import AzureLogHandler
run = Run.get_context()
# Azure ML Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
# Python logging with OpenCensus AzureLogHandler
logger.warning("I am an OpenCensus warning statement, find me in Application Insights!")
logger.error("I am an OpenCensus error statement with custom dimensions", {'step_id': run.id})
Azure 机器学习设计器
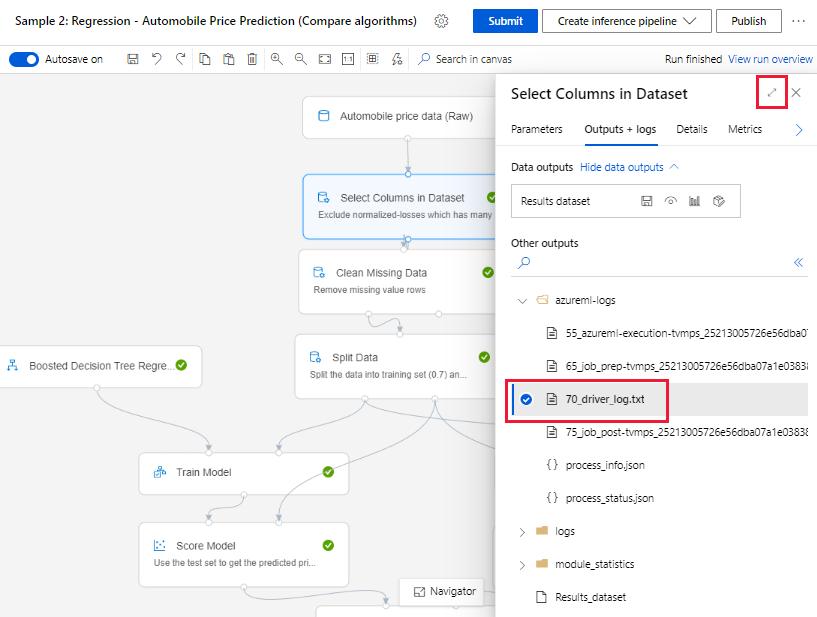
对于在设计器中创建的管道,可以在创作页或管道运行详细信息页中找到 70_driver_log 文件。
为实时终结点启用日志记录
若要在设计器中排查和调试实时终结点问题,必须使用 SDK 启用 Application Insight 日志记录。 使用日志记录可排查和调试模型部署和使用问题。 有关详细信息,请参阅对部署的模型进行日志记录。
从创作页获取日志
提交管道运行并停留在创作页时,可以找到在每个组件完成运行时为每个组件生成的日志文件。
选择已完成在创作画布中运行的组件。
在该组件的右窗格中,转到“输出 + 日志”选项卡。
展开右窗格,然后选择 70_driver_log.txt 并在浏览器中查看该文件。 还可以在本地下载日志。
从管道运行获取日志
还可以在管道运行详细信息页找到特定运行的日志文件,文件位于工作室的“管道”或“试验”部分。
选择在设计器中创建的一个管道运行。
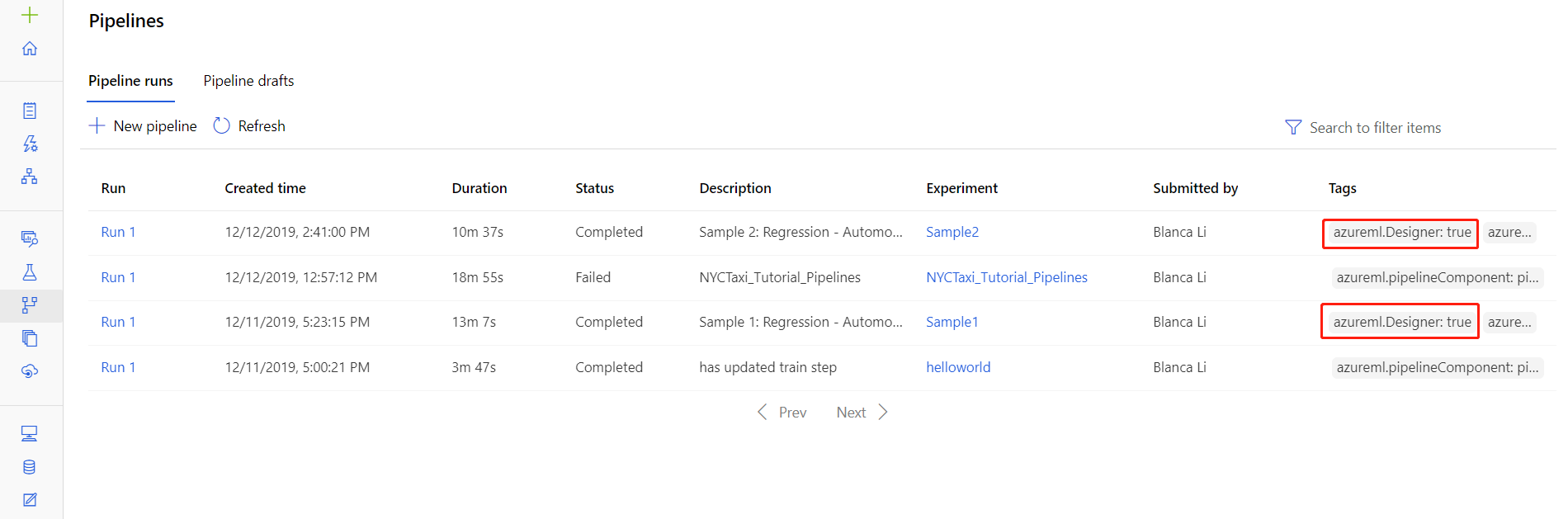
在预览窗格中选择一个组件。
在该组件的右窗格中,转到“输出 + 日志”选项卡。
展开右侧窗格以在浏览器中查看 std_log.txt 文件,或者选择该文件以将日志下载到本地。
重要
若要从管道运行详细信息页更新管道,必须将管道运行克隆到新管道草稿。 管道运行是管道的快照。 它类似于日志文件,并且无法更改。
Application Insights
有关以此方式使用 OpenCensus Python 库的详细信息,请参阅此指南:在 Application Insights 中对机器学习管道进行调试和故障排除
使用 Visual Studio Code 进行交互式调试
在某些情况下,可能需要以交互方式调试 ML 管道中使用的 Python 代码。 通过使用 Visual Studio Code (VS Code) 和 debugpy,可以在训练环境中运行代码时附加到该代码。 有关详细信息,请访问在 VS Code 指南中进行交互式调试。
后续步骤
有关使用
ParallelRunStep的完整教程,请参阅教程:生成 Azure 机器学习管道以用于批量评分中的说明操作。有关显示 ML 管道中自动化机器学习的完整示例,请参阅在 Python 的 Azure 机器学习管道中使用自动化 ML。
有关 azureml-pipelines-core 包和 azureml-pipelines-steps 包的帮助信息,请参阅 SDK 参考。
请参阅设计器异常和错误代码的列表。