Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
在本文中,你将使用 Azure 机器学习工作室 UI 中的无代码体验创建负责任 AI 仪表板和记分卡(预览版)。
重要
此功能目前处于公开预览状态。 此预览版在提供时没有附带服务级别协议,我们不建议将其用于生产工作负荷。 某些功能可能不受支持或者受限。
有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
若要访问仪表板生成页并生成负责任的 AI 仪表板,请执行以下步骤:
在 Azure 机器学习中注册模型,以便能够访问无代码体验。
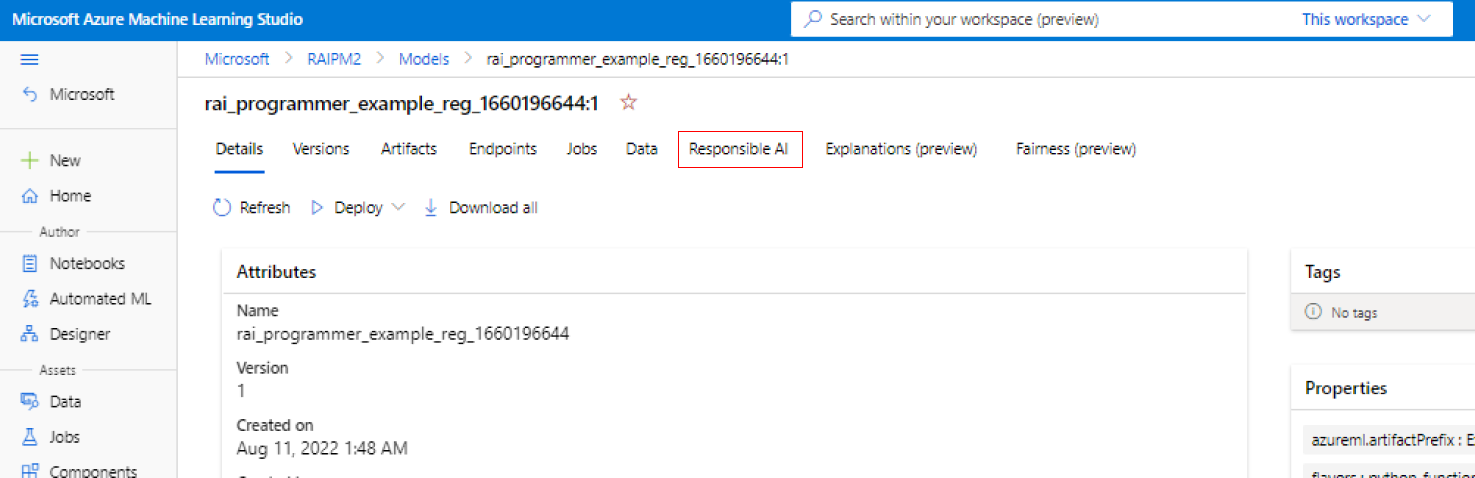
在 Azure 机器学习工作室的左侧窗格中选择“模型”选项卡。
选择要为其创建负责任 AI 见解的已注册模型,然后选择“详细信息”选项卡。
选择“创建负责任 AI 仪表板(预览版)”。

若要详细了解负责任 AI 仪表板中支持的模型类型和限制,请参阅支持的方案和限制。
仪表板生成页提供了一个界面,用于输入所有必要的参数来创建负责任的 AI 仪表板,而无需触摸代码。 该体验完全在 Azure 机器学习工作室 UI 中进行。 工作室提供引导式流程和说明文本,以帮助将填充在仪表板中的负责任 AI 组件的各种选项上下文化。
生成过程分为六个部分:
- 训练数据集
- 测试数据集
- 建模任务
- 仪表板组成部分
- 组件参数
- 试验配置
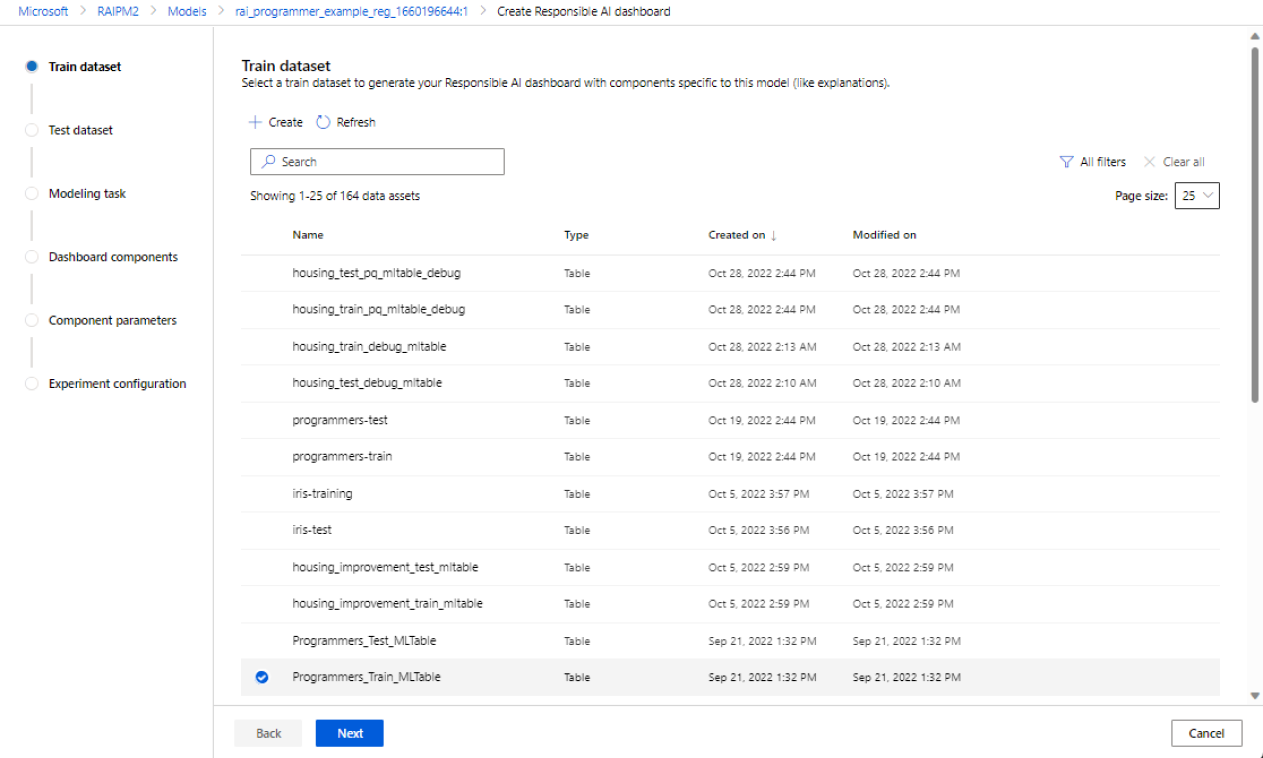
选择数据集
在前两个部分,你将选择训练模型时使用的训练和测试数据集,以生成模型调试见解。 对于不需要模型的因果分析等组件,可使用训练数据集训练因果模型以生成因果见解。
注释
仅支持 ML 表中的表格数据集格式。
选择用于训练的数据集:在 Azure 机器学习工作区中已注册数据集的列表中,选择要用来为组件(例如模型解释和错误分析)生成负责任 AI 见解的数据集。
选择用于测试的数据集:在已注册数据集的列表中,选择要用于填充负责任 AI 仪表板可视化效果的数据集。
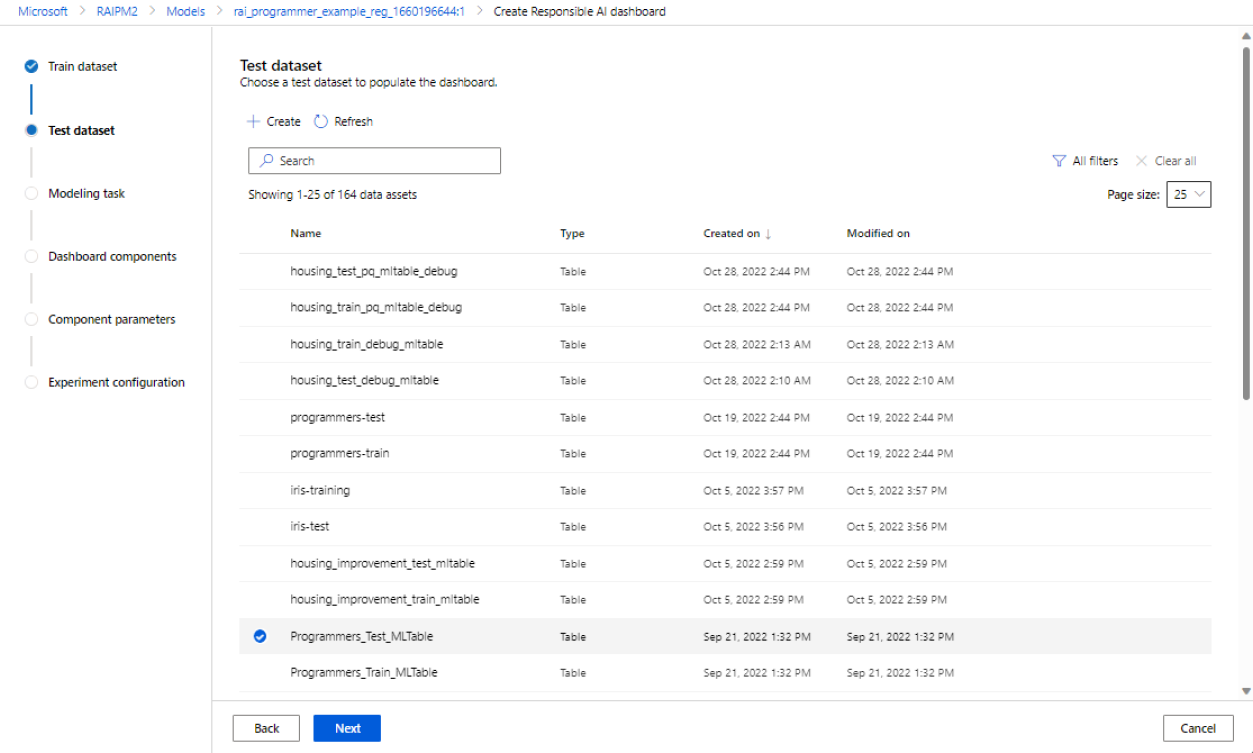
如果你要使用的训练或测试数据集未列出,请选择“创建”以上传数据集。


选择建模任务
选择数据集后,选择建模任务类型,如下图所示:

选择仪表板组件
负责任 AI 仪表板提供两个配置文件,其中包含可生成的建议工具集:
模型调试:使用错误分析、反事实假设示例和模型可解释性来了解和调试机器学习模型中错误的数据队列。
现实干预:使用因果分析来了解和调试机器学习模型中错误的数据队列。
注释
多类分类不支持现实干预分析配置文件。

- 选择要使用的配置文件。
- 选择“下一步”。
为仪表板组件配置参数
** 选择配置文件后,将出现用于模型调试的相应组件的配置参数窗格。

用于模型调试的组件参数:
目标特征(必需):指定训练的模型要预测的特征。
分类特征:指明哪些特征是分类的,以便在仪表板 UI 中正确地将其呈现为分类值。 此字段会根据您的数据集元数据预加载。
生成错误树和热度地图:切换为打开或关闭,以便为负责任 AI 仪表板生成错误分析组件。
错误热度地图的功能:选择最多两个要预生成错误热度地图的功能。
高级配置:指定其他参数,例如 错误树的最大深度、 错误树中的叶数和 每个叶节点的最小样本数。
生成反事实假设示例:切换为打开或关闭,以便为负责任 AI 仪表板生成反事实假设组件。
反事实示例数(必需):指定要为每个数据点生成的反事实示例数。 应至少生成 10 个以启用特征的条形图视图,在一般情况下,对这些特征进行最大扰动才实现了所需的预测结果。
值预测范围(必需):为回归方案指定希望反事实示例从中获取预测值的范围。 对于二元分类场景,范围设置为为每个数据点的相反类生成反事实实例。 对于多分类方案,请使用下拉列表来指定要将每个数据点预测为哪个类。
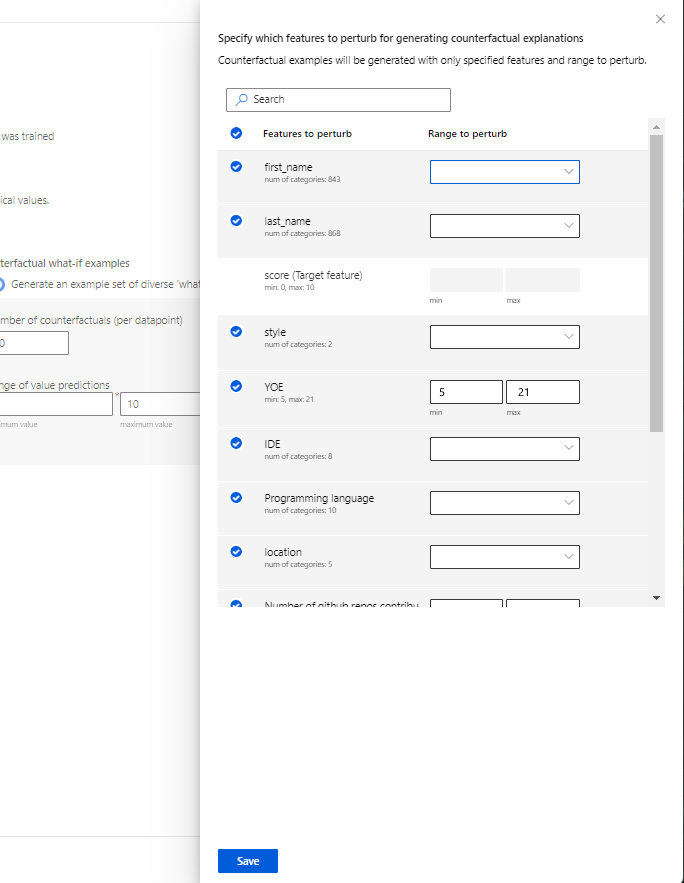
指定要扰动的功能:默认情况下,所有功能都会被扰动。 但是,如果只希望扰动特定功能,请选择“指定要扰动哪些功能以生成反事实解释”,以显示一个可以选择功能的窗格。
选择“指定要扰动的特征”时,可以指定允许扰动的范围。 例如,对于特征 YOE(多年经验),应指定反事实的特征值范围为 10 到 21,而不是默认的 5 到 21。
生成解释:切换为打开或关闭,以便为负责任 AI 仪表板生成模型解释组件。 无需配置,因为默认的模拟不透明框的解释器会生成特征重要性。

或者,如果选择 实际干预 配置设置,则会看到以下屏幕生成因果分析。 此方法可帮助你了解想要“处理”的特征对你想优化的特定结果的因果影响。

现实干预的组件参数使用因果分析。 执行以下步骤:
- 目标特征(必需):选择要为其计算因果效应的结果。
- 处理特征(必需):选择要更改(“处理”)的一个或多个特征以优化目标结果。
- 分类特征:指明哪些特征是分类的,以便在仪表板 UI 中正确地将其呈现为分类值。 此字段会根据您的数据集元数据预加载。
- 高级设置:为因果分析指定其他参数,例如异类特征以及要使用的因果模型。 异类特征 是用于了解分析中因果分段的功能,以及治疗特征。
配置试验
最后,配置试验以启动一个作业来生成负责任 AI 仪表板。

在 “训练作业 ”或“ 试验配置 ”窗格中,执行以下步骤:
- 名称:为仪表板指定唯一的名称,以便在查看给定模型的仪表板列表时可以区分该仪表板。
- 试验名称:选择一个现有试验来运行作业,或创建新的试验。
- 现有试验:选择现有试验。
- 选择计算类型:指定要用于运行作业的计算类型。
- 选择计算:选择要使用的计算。 如果没有现有的计算资源,请选择加号 (+) 创建新的计算资源,然后刷新列表。
- 说明:为负责任 AI 仪表板添加较长的说明。
- 标记:将任何标记添加到此负责任 AI 仪表板。
完成试验配置后,选择“ 创建 ”开始生成负责任的 AI 仪表板。 作业页会将你重定向到试验页,以跟踪作业的进度,并链接到生成的“负责任的 AI”仪表板。
若要了解如何查看和使用负责任 AI 仪表板,请参阅在 Azure 机器学习工作室中使用负责任 AI 仪表板。
如何生成负责任 AI 记分卡(预览版)
创建仪表板后,可以在 Azure 机器学习工作室中使用无代码 UI 来自定义并生成负责任 AI 评分卡。 通过此方法,你可以与非技术和技术利益干系人共享对模型负责部署的关键见解,例如公平性和特征重要性。 与创建仪表板类似,可以使用以下步骤访问记分卡生成页面:
- 从 Azure 机器学习工作室的左窗格中导航到“ 模型 ”选项卡。
- 选择要为其创建记分卡的已注册模型,然后选择“负责任 AI”选项卡。
- 在顶部面板中选择“创建负责任 AI 见解(预览版)”,然后选择“生成新的 PDF 记分卡”。
仪表板生成页允许你自定义 PDF 记分卡,而无需触摸代码。 整个体验都在 Azure 机器学习工作室中,这有助于理解 UI 各种选择的上下文。 此方法通过引导流程和说明文本,帮助您选择要在记分卡中填充的组件。 页面分为七个步骤,第八步(公平性评估)仅适用于具有分类功能的模型:
- PDF 记分卡摘要
- 模型性能
- 工具选择
- 数据分析(以前称为数据资源管理器)
- 因果分析
- 可解释性
- 试验配置
- 公平性评估(仅当存在分类特征时)
配置记分卡
输入记分卡的描述性标题。 还可以输入有关模型功能、用于训练和评估模型的数据、体系结构类型等的可选说明。
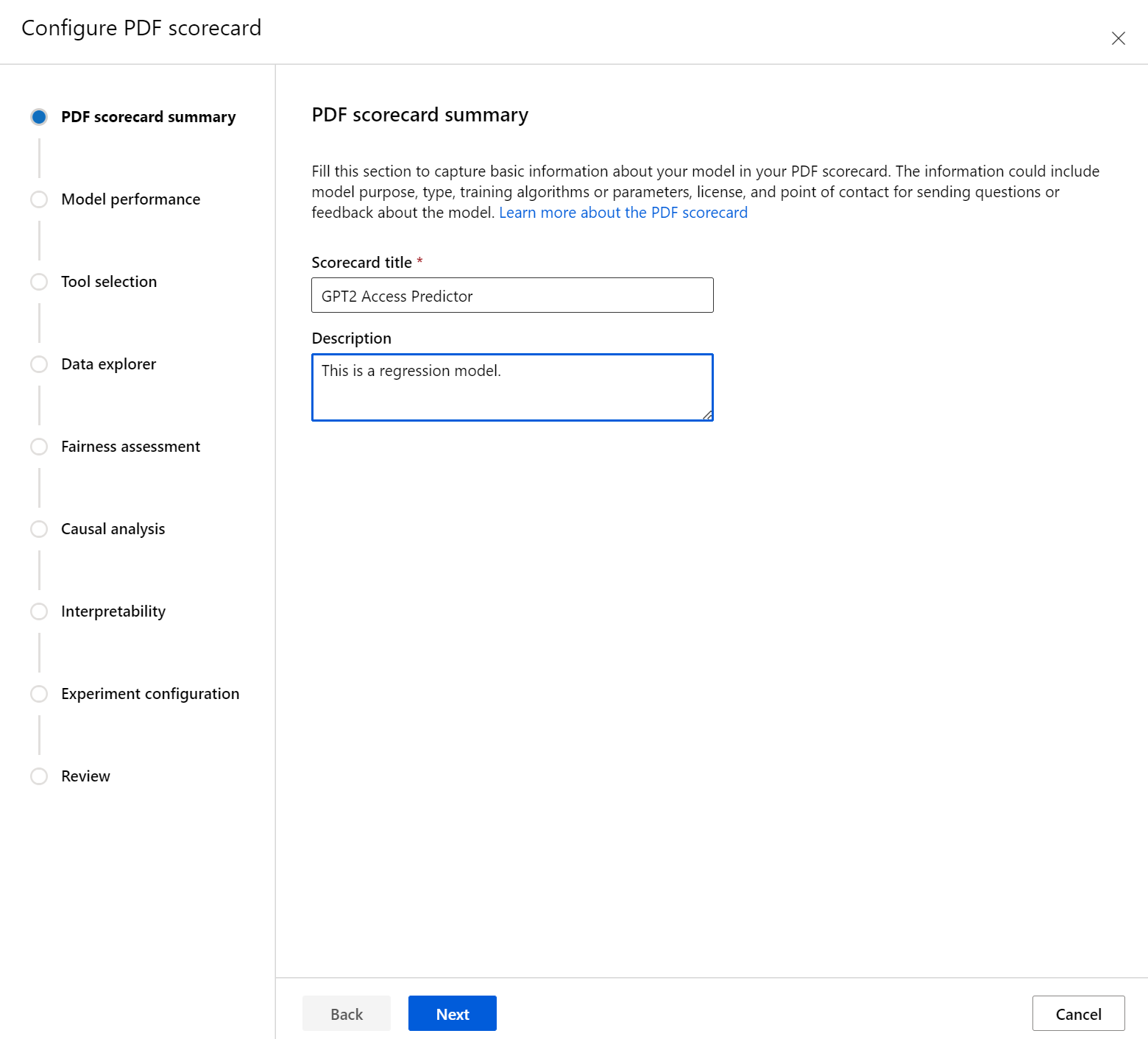
在“模型性能”部分,可以将行业标准模型评估指标纳入记分卡,同时还可为所选指标设置所需的目标值。 使用下拉列表选择所需的性能指标(最多三个)和目标值。
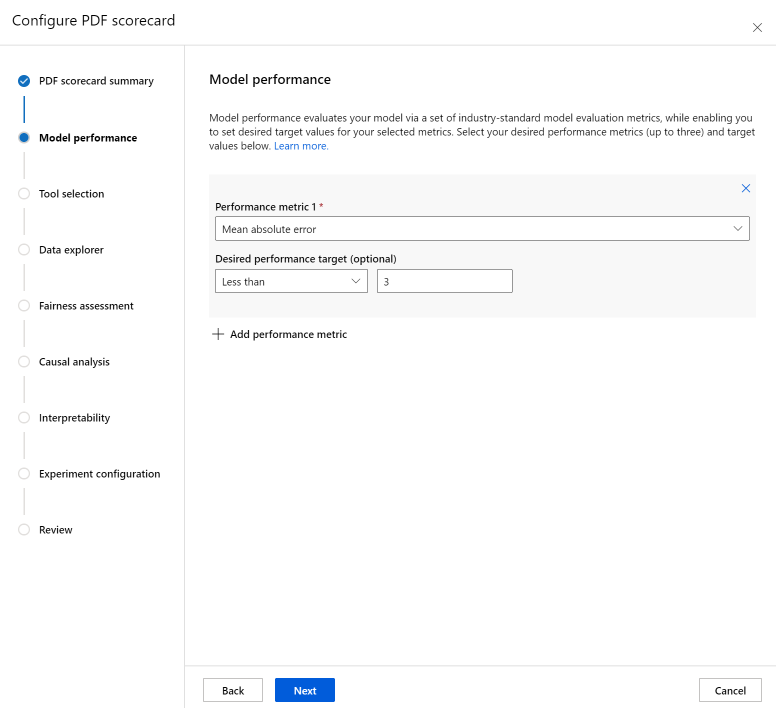
使用“工具选择”步骤可以选择要包含在记分卡中的后续组件。 选择包括在记分卡中以包括所有组件,或单独选择每个组件。 若要了解有关组件的详细信息,请选择组件旁边的信息图标(“i”)。
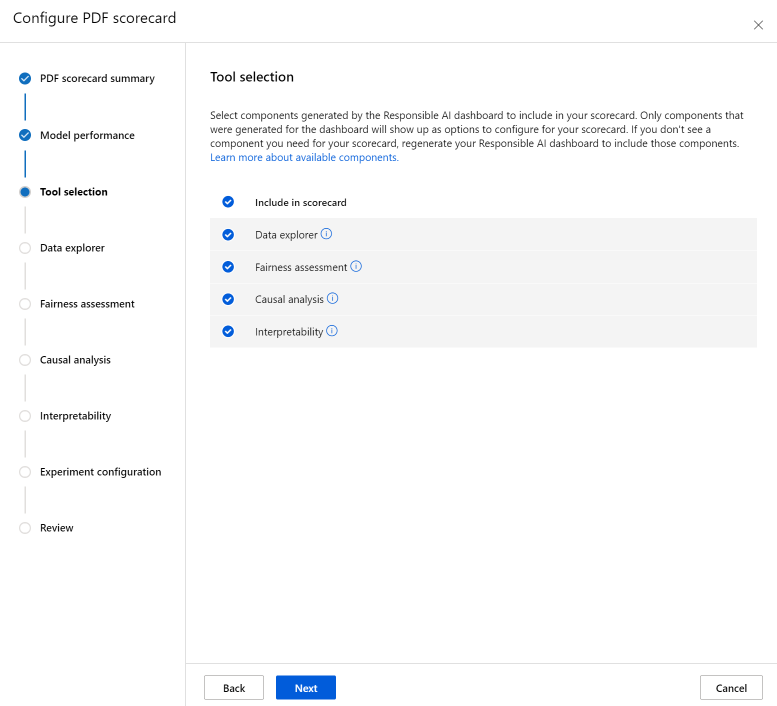
在“数据分析”部分(以前称为数据资源管理器)可以进行队列分析。 在这里,可以识别过度和不足表示的问题,了解如何在数据集中对数据进行聚类分析,以及模型预测如何影响特定数据队列。 在下拉列表中选择特征作为感兴趣的特征,以识别其相关队列上的模型性能。
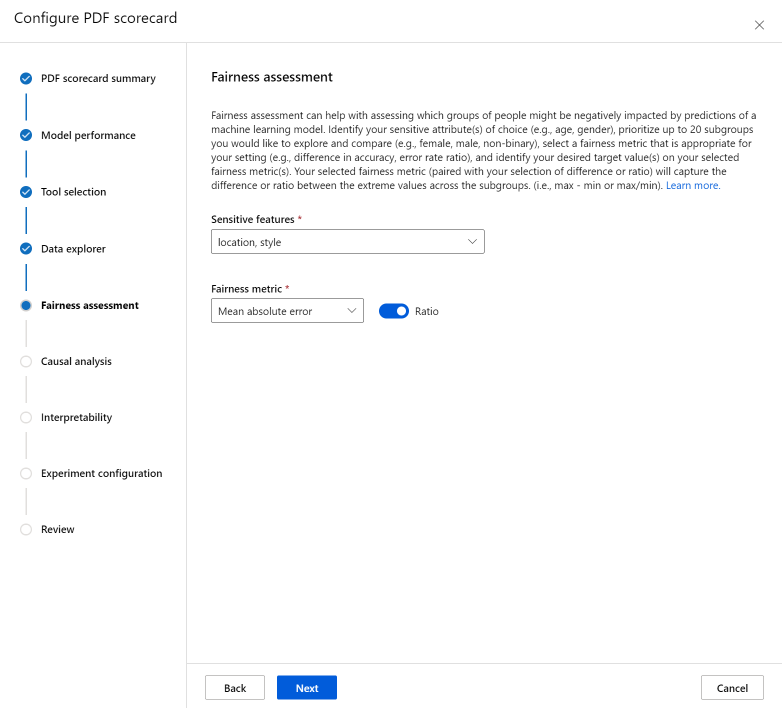
公平性评估 部分可以帮助评估机器学习模型的预测可能对哪些人群产生负面影响。 此部分有两个字段。
敏感特征:通过确定要浏览和比较的 20 个子组的优先级来确定所选的敏感属性(例如年龄、性别)。
公平性指标:选择适合设置的公平性指标,例如准确性或错误率比率的差异。 根据所选公平性指标确定所需的目标值。 所选的公平性指标与您选择的差异或比率结合使用切换按钮,用于衡量子组中极端值之间的差异或比率。 (最大值 - 最小值或最大值/最小值)。
注释
公平性评估目前仅适用于分类敏感属性,例如性别。
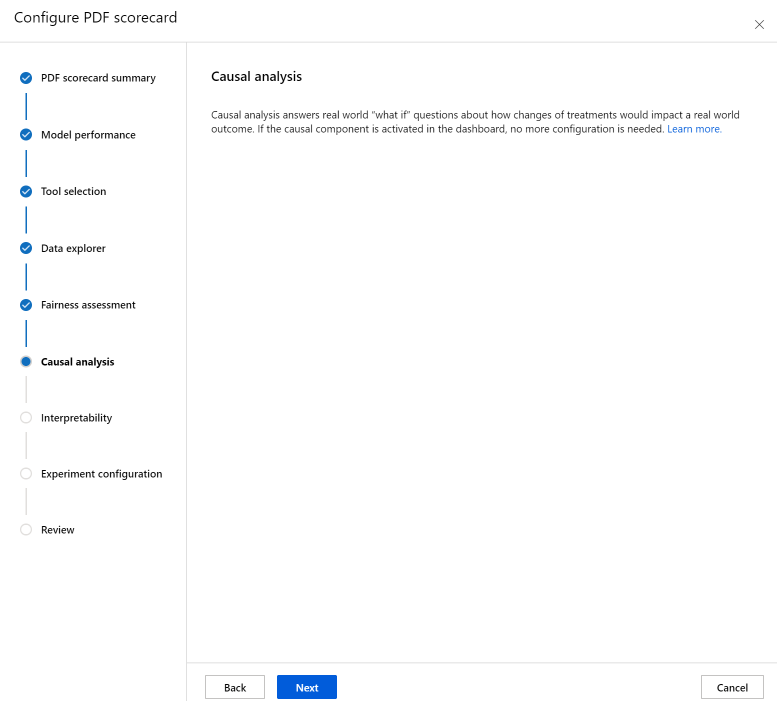
因果分析 部分回答了现实世界的“如果”问题,即治疗的变化如何影响现实世界的结果。 如果你正在为其生成记分卡的负责任 AI 仪表板中已激活因果组件,则无需进行更多配置。
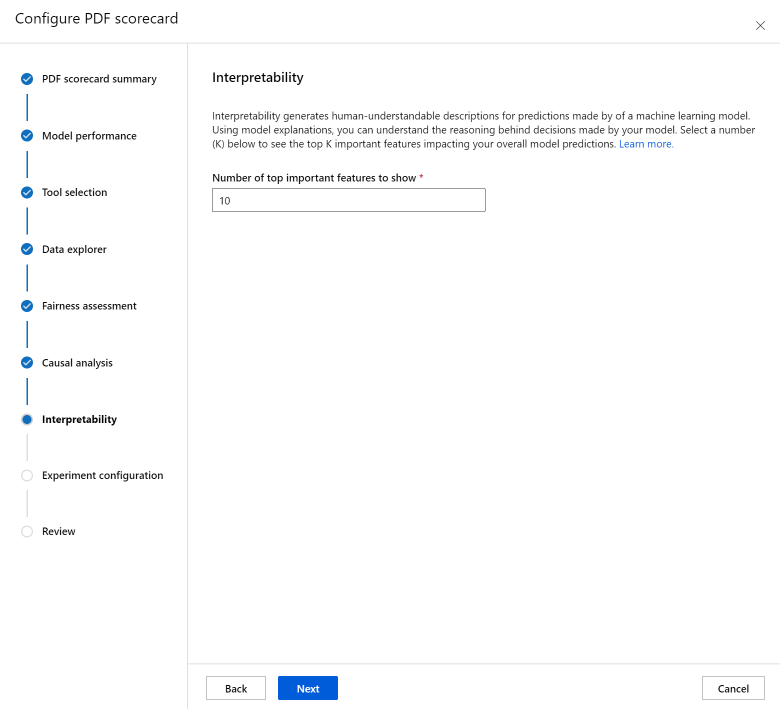
“可解释性”部分为机器学习模型做出的预测生成人类可理解的说明。 使用模型解释可以理解模型做出决策的理由。 选择一个数字(K),以查看影响总体模型预测的顶级 K 重要特征。 K 的默认值为 10。
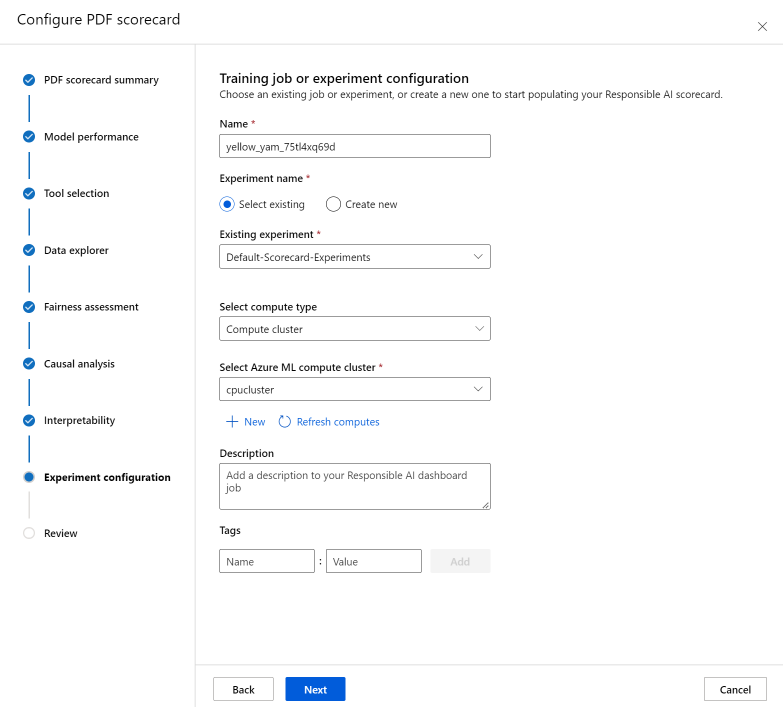
配置实验以启动任务生成记分卡。 这些配置与负责任 AI 仪表板的配置相同。
最后,检查配置并选择“创建”以启动作业!
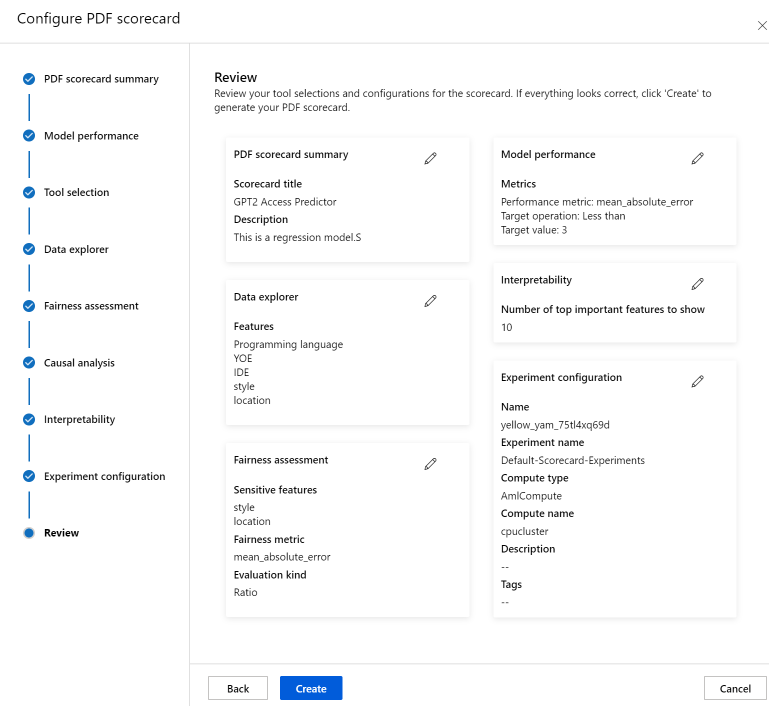
启动作业后,它会将你重定向到试验页,以跟踪作业的进度。 若要了解如何查看和使用负责任 AI 记分卡,请参阅使用负责任 AI 记分卡(预览版)。









相关内容
- 生成负责任的 AI 仪表板后, 查看如何在 Azure 机器学习工作室中访问和使用它。
- 详细了解负责任 AI 仪表板背后的概念和技术。
- 详细了解如何负责地收集数据。
- 参阅此技术社区博客文章,详细了解如何使用负责任 AI 仪表板和记分卡来调试数据和模型,并为更好的决策提供信息。
- 参阅真实客户案例,了解英国国家医疗服务体系 (NHS) 如何使用负责任 AI 仪表板和记分卡。