Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
使用 Azure 机器学习设计器中的内置示例,快速开始生成自己的机器学习管道。 Azure 机器学习设计器 GitHub 存储库包含了可帮助你了解某些常见机器学习方案的详细文档。
必备条件
- Azure 订阅。 如果没有 Azure 订阅,请创建一个试用版订阅
- Azure 机器学习工作区
重要
如果看不到本文档中提到的图形元素(例如工作室或设计器中的按钮),则你可能没有适当级别的工作区权限。 请与 Azure 订阅管理员联系,验证是否已向你授予正确级别的访问权限。 有关详细信息,请参阅管理用户和角色。
使用示例管道
设计器会将示例管道的副本保存到工作室工作区。 你可以编辑管道,以根据自己的需求对其进行改编;还可以保存管道供自己使用。 可以使用这些示例作为起点来快速开始生成项目。
以下介绍如何使用设计器示例:
登录到 studio.ml.azure.cn,选择要使用的工作区。
选择“设计器”。
在“新建管道”部分下选择一个示例管道。
选择“显示更多示例”查看完整的示例列表。
若要运行管道,必须首先设置要在其上运行管道的默认计算目标。
在画布右侧的“设置”窗格中,选择“选择计算目标”。
在出现的对话框中,选择现有的计算目标或创建新的计算目标。 选择“保存”。
选择画布顶部的“提交”,提交管道作业。
根据示例管道和计算设置,作业可能需要一些时间才能完成。 默认计算设置中的最小节点大小为 0,这意味着设计器必须在空闲后分配资源。 重复的管道作业花费的时间会更少,因为计算资源已分配。 此外,设计器还对每个组件使用缓存的结果,以便进一步提高效率。
管道运行完毕后,可以查看管道,还可以查看每个组件的输出,了解详细信息。 使用以下步骤查看组件输出:
- 右键单击画布中要查看其输出的组件。
- 选择“可视化”。
从示例着手,了解一些最常见的机器学习方案。
回归
探索这些内置的回归示例。
| 标题示例 | 说明 |
|---|---|
| 回归 - 汽车价格预测(基本)。 | 使用线性回归预测汽车价格。 |
| 回归 - 汽车价格预测(高级) | 使用决策林和提升决策树回归器预测汽车价格。 比较模型以找出最佳算法。 |
分类
探索这些内置的分类示例。 可以通过打开示例并在设计器中查看组件注释来了解有关这些示例的详细信息。
| 标题示例 | 说明 |
|---|---|
| 通过特征选择进行二元分类 - 收入预测 | 使用双类提升决策树预测收入的高低。 使用皮尔逊相关选择特征。 |
| 通过自定义 Python 脚本进行二元分类 - 信用风险预测 | 将信贷申请分类为高风险或低风险。 使用“执行 Python 脚本”组件为数据加权。 |
| 二元分类 - 客户关系预测 | 使用双类提升决策树预测客户流失率。 使用 SMOTE 对有偏差的数据采样。 |
| 文本分类 - 维基百科 SP 500 数据集 | 使用多类逻辑回归对维基百科文章中的公司类型进行分类。 |
| 多类分类 - 字母识别 | 创建二元分类器的系综,对手写字母进行分类。 |
计算机视觉
探索这些内置的计算机视觉示例。 可以通过打开示例并在设计器中查看组件注释来了解有关这些示例的详细信息。
| 标题示例 | 说明 |
|---|---|
| 使用 DenseNet 进行的图像分类 | 使用计算机视觉组件基于 PyTorch DenseNet 构建图像分类模型。 |
推荐器
探索这些内置的推荐器示例。 可以通过打开示例并在设计器中查看组件注释来了解有关这些示例的详细信息。
| 标题示例 | 说明 |
|---|---|
| 基于广度和深度的推荐 - 餐馆评分预测 | 基于餐馆/用户功能和评分构建餐馆推荐器引擎。 |
| 推荐 - 电影评级推文 | 基于电影/用户特征和评级生成电影推荐器引擎。 |
实用工具
详细了解用于演示机器学习实用工具和功能的示例。 可以通过打开示例并在设计器中查看组件注释来了解有关这些示例的详细信息。
| 标题示例 | 说明 |
|---|---|
| 使用 Vowpal Wabbit 模型的二元分类 - 成人收入预测 | Vowpal Wabbit 是一个机器学习系统,它使用在线、哈希、全约简、约简、learning2search、主动和交互式学习等技术来开拓机器学习的领域。 此示例展示了如何使用 Vowpal Wabbit 模型来构建二元分类模型。 |
| 使用自定义 R 脚本 - 航班延误预测 | 使用自定义 R 脚本预测所计划的客运航班是否会延迟 15 分钟以上。 |
| 二元分类的交叉验证 - 成人收入预测 | 使用交叉验证生成用于预测成人收入的二元分类器。 |
| 排列特征重要性 | 使用排列特征重要性来计算测试数据集的重要性评分。 |
| 优化二元分类的参数 - 成人收入预测 | 使用“优化模型超参数”找出用于生成二元分类器的最佳超参数。 |
数据集
在 Azure 机器学习设计器中创建新管道时,其中会默认包含多个示例数据集。 设计器主页中的示例管道使用这些示例数据集。
示例数据集在“数据集-示例”类别下提供。 可以在设计器的画布左侧的组件面板中找到它。 将其中的任何数据集拖放到画布中即可在自己的管道中使用它们。
| 数据集名称 | 数据集说明 |
|---|---|
| 成年人口收入二元分类数据集 | 1994 年人口普查数据库的子集(其中在职人士年龄大于 16,调整后的收入指数大于 100)。 使用情况:使用人口统计信息对人员分类,预测某人的年收入是否超过 5 万。 相关研究:Kohavi, R.、Becker, B.(1996 年)。 UCI 机器学习存储库。 加州大学欧文分校的信息与计算机科学学院 |
| 汽车价格数据(原始) | 有关汽车品牌和型号的信息,包括价格、汽缸数和 MPG 等特性以及保险风险评分。 风险评分最初与自动定价关联。 然后,针对精算师所熟知符号化过程中的实际风险进行调整。 值为 +3 表明汽车存在风险,值为 -3 表明汽车可能安全。 使用情况:按特性、使用回归或多元分类预测风险评分。 相关研究:Schlimmer, J.C. (1987)。 UCI 机器学习存储库。 加州大学欧文分校的信息与计算机科学学院。 |
| 共享的 CRM 亲和力标签 | 来自 KDD Cup 2009 客户关系预测挑战赛的标签 (orange_small_train_appetency.labels)。 |
| 共享的 CRM 流失情况标签 | 来自 KDD Cup 2009 客户关系预测挑战赛的标签 (orange_small_train_churn.labels)。 |
| 共享的 CRM 数据集 | 此数据来自 KDD Cup 2009 客户关系预测挑战赛 (orange_small_train.data.zip)。 数据集包含法国电信公司 Orange 的 50K 个客户。 每个客户都有 230 个匿名特征,其中 190 个是数字的,其余 40 个是分类的。 特征非常稀疏。 |
| 共享的 CRM 追加销售标签 | 来自 KDD Cup 2009 客户关系预测挑战赛的标签 (orange_large_train_upselling.labels |
| 航班延误数据 | 从美国的 TranStats 数据收集中获得的客运航班正常率数据。交通部(准时)。 数据集涵盖 2013 年 4 月到 10 月的时间段。 在上传到设计器之前,数据集的处理如下所述: - 数据集经筛选,仅涵盖美国本土 70 个最繁忙的机场 - 取消的航班标记为延误超过 15 分钟 - 转机航班已筛选掉 - 已选择以下各列:Year、Month、DayofMonth、DayOfWeek、Carrier、OriginAirportID、DestAirportID、CRSDepTime、DepDelay、DepDel15、CRSArrTime、ArrDelay、ArrDel15、Canceled |
| 德国信用卡 UCI 数据集 | 使用 german.data 文件的 UCI Statlog(德国信用卡)数据集 (Statlog+German+Credit+Data)。 数据集将用户(由一组属性描述)分为两类:低信用风险或高信用风险。 每个示例表示一位用户。 有 20 个特征,包括数值和分类,以及二进制标签(信用风险值)。 高信用风险条目具有标签 = 2,低信用风险条目具有标签 = 1。 将低风险示例错误分类为高的成本是 1,反之将高风险示例错误分类为低的成本是 5。 |
| IMDB 电影标题 | 数据集包含 Twitter 推文中给电影评分的有关信息:IMDB 电影 ID、电影名称、风格和制作年份。 数据集中有 17K 个电影。 报告“S. Dooms、T. De Pessemier 和 L. Martens. MovieTweetings:从 Twitter 收集的电影评分数据集。 有关适用于推荐器系统 (CrowdRec at RecSys 2013) 的众包和人工计算研讨会。”中引用了该数据集。 |
| 电影评分 | 该数据集是电影迷你推文数据集的扩展版本。 数据集中具有 170K 个电影评分,从 Twitter 上结构良好的推文中提取。 每个实例表示一篇推文,是一个元组:用户 ID、IMDB 电影 ID、评分、时间戳、收藏此推文的数目和转发此推文的数目。 数据集由 A. Said、S. Dooms、B. Loni 和 D. Tikk 提供,用于 Recommender Systems Challenge 2014。 |
| 天气数据集 | 美国国家海洋和大气局每小时发布的陆基天气观测(从 201304 到 201310 的合并数据)。 该天气数据包括从机场气象站获取的观测结果,涵盖的时间段为 2013 年 4 月到 10 月。 在上传到设计器之前,数据集的处理如下所述: - 将气象站 ID 映射到相应的机场 ID - 与 70 个最繁忙的机场无关的气象站已筛选掉 - Date 列已拆分为单独的 Year、Month 和 Day 列 - 已选择以下各列:AirportID、Year、Month、Day、Time、TimeZone、SkyCondition、Visibility、WeatherType、DryBulbFarenheit、DryBulbCelsius、WetBulbFarenheit、WetBulbCelsius、DewPointFarenheit、DewPointCelsius、RelativeHumidity、WindSpeed、WindDirection、ValueForWindCharacter、StationPressure、PressureTendency、PressureChange、SeaLevelPressure、RecordType、HourlyPrecip、Altimeter |
| 维基百科 SP 500 数据集 | 数据来自维基百科 (https://www.wikipedia.org/),基于每个标准普尔 500 强公司的文章,存储为 XML 数据。 在上传到设计器之前,数据集的处理如下所述: - 提取每个具体公司的文本内容 - 去除 wiki 格式设置 - 去除非字母数字字符 - 将所有文本都转换为小写 - 添加了已知的公司类别 请注意,可能找不到某些公司的文章,因此记录数小于 500。 |
| 餐馆特色数据 | 一组关于餐馆及其特色的元数据,如食物种类、就餐样式和位置。 使用情况:将此数据集与其他两个餐馆数据集结合使用,以便训练和测试推荐器系统。 相关研究:Bache, K. 和 Lichman, M.(2013 年)。 UCI 机器学习存储库。 加州大学欧文分校的信息与计算机科学学院。 |
| 餐馆评分 | 包含用户对餐馆的评分,分数范围从 0 到 2。 使用情况:将此数据集与其他两个餐馆数据集结合使用,以便训练和测试推荐器系统。 相关研究:Bache, K. 和 Lichman, M.(2013 年)。 UCI 机器学习存储库。 加州大学欧文分校的信息与计算机科学学院。 |
| 餐馆客户数据 | 一组关于客户的元数据,其中包括人口统计信息和偏好。 使用情况:将此数据集与其他两个餐馆数据集结合使用,以便训练和测试推荐器系统。 相关研究:Bache, K. 和 Lichman, M.(2013 年)。 UCI 机器学习存储库 Irvine, CA:欧文分校的信息与计算机科学学院。 |
清理资源
重要
可以使用你创建的、用作其他 Azure 机器学习教程和操作指南文章的先决条件的资源。
删除所有内容
如果你不打算使用所创建的任何内容,请删除整个资源组,以免产生任何费用。
在 Azure 门户的窗口左侧选择“资源组”。
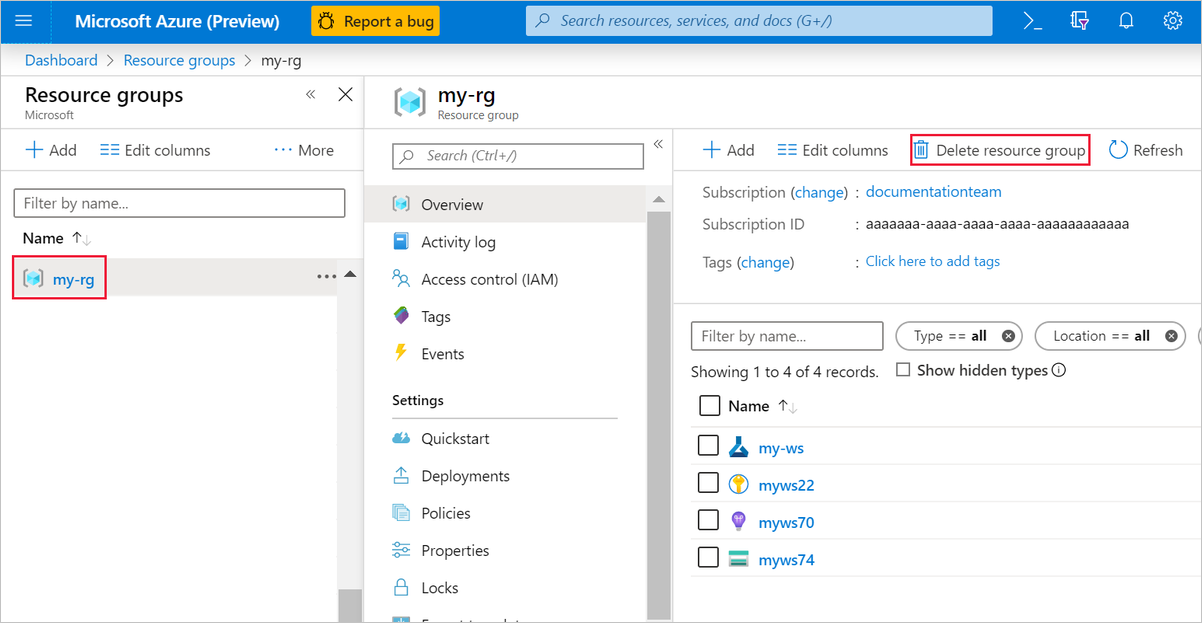
在列表中选择你创建的资源组。
选择“删除资源组”。
删除该资源组也会删除在设计器中创建的所有资源。
删除各项资产
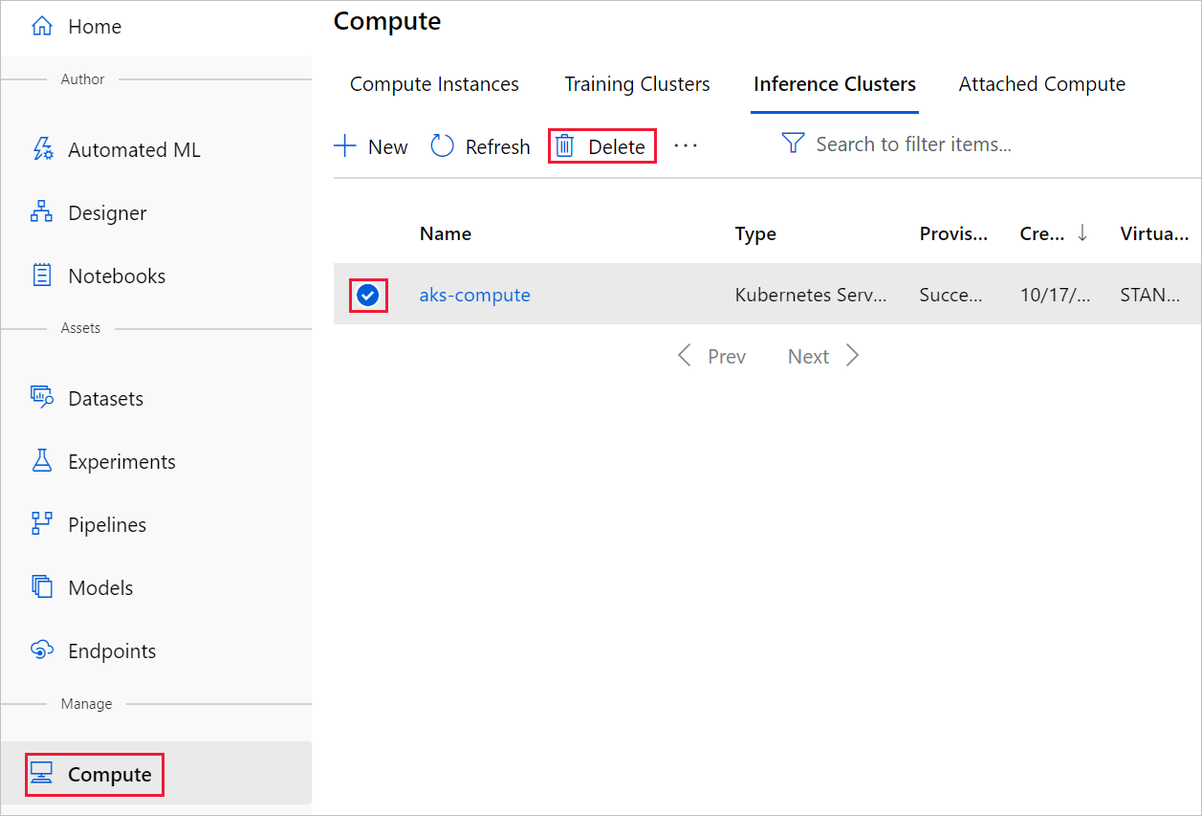
在创建试验的设计器中删除各个资产,方法是将其选中,然后选择“删除”按钮。
此处创建的计算目标在未使用时,会自动缩减到零个节点。 此操作旨在最大程度地减少费用。 若要删除计算目标,请执行以下步骤:
可以通过选择每个数据集并选择“注销”,从工作区中注销数据集。
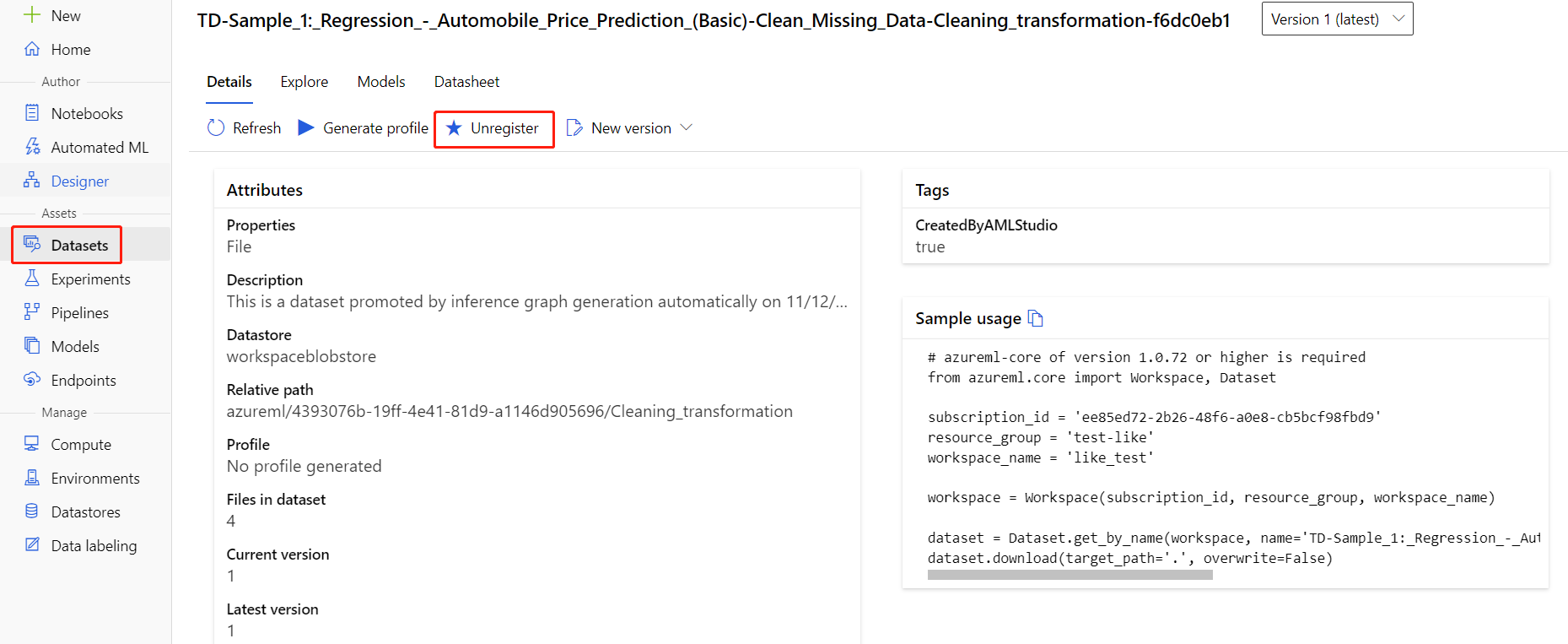
若要删除数据集,请使用 Azure 门户或 Azure 存储资源管理器访问存储帐户,然后手动删除这些资产。
后续步骤
使用以下教程了解有关预测分析和机器学习的基础知识 - 教程:使用设计器预测汽车价格