Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: 适用于 Python 的 Azure 机器学习 SDK v1
适用于 Python 的 Azure 机器学习 SDK v1
重要
本文提供有关使用 Azure 机器学习 SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure 机器学习 CLI 和 Python SDK v2? 以及 SDK v2 参考。
本教程介绍如何在 Azure 机器学习中训练机器学习模型。 本教程是由两个部分构成的教程系列的第 2 部分。
在此系列的第 1 部分:运行“Hello world!”中,你学习了如何使用控制脚本在云中运行作业。
在本教程中,你通过提交用于训练机器学习模型的脚本来执行下一步。 此示例有助于了解 Azure 机器学习如何在本地调试和远程运行之间轻松实现一致的行为。
本教程介绍以下操作:
- 创建训练脚本。
- 使用 Conda 定义 Azure 机器学习环境。
- 创建控制脚本。
- 了解 Azure 机器学习类(
Environment、Run、Metrics)。 - 提交并运行训练脚本。
- 在云中查看代码输出。
- 将指标记录到 Azure 机器学习。
- 在云中查看指标。
先决条件
- 完成本系列的第 1 部分。
创建训练脚本
首先,在 model.py 文件中定义神经网络体系结构。 所有训练代码(包括src)都会进入子目录。
训练代码来自 PyTorch 中的介绍性示例。 Azure 机器学习概念适用于任何机器学习代码,而不只是 PyTorch。
在 src 子文件夹中创建 model.py。 将以下代码复制到文件中:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x在工具栏中,选择“保存”以保存文件。 如果需要,请关闭选项卡。
接下来,还是在 src 子文件夹中定义训练脚本。 此脚本通过使用 PyTorch
torchvision.datasetAPI 来下载 CIFAR10 数据集,设置 model.py 中定义的网络,并通过使用标准 SGD 和互熵损失对该数据集进行两个时期的训练。在 src 子文件夹中创建 train.py 脚本:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")现在你拥有以下文件夹结构:
在本地测试
选择“保存并在终端中运行脚本”,以直接在计算实例上运行 train.py 脚本。
脚本完成后,选择文件文件夹上方的“刷新”。 你会看到名为get-started/data的新数据文件夹。展开此文件夹,查看已下载的数据。
创建 Python 环境
Azure 机器学习提供了环境概念来表示一个可重现的、进行了版本控制的 Python 环境,以便用来运行试验。 从本地 Conda 或 pip 环境创建一个环境很简单。
首先,你会创建包含包依赖项的文件。
在 get-started 文件夹中创建新的文件,名为 :
name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvision在工具栏中,选择“保存”以保存文件。 如果需要,请关闭选项卡。
创建控制脚本
下面的控制脚本和用于提交“Hello world!”的脚本的差异在于,你添加了几个额外的行来设置环境。
在 get-started 文件夹中创建新的 Python 文件,名为 :
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
提示
如果在创建计算群集时使用了其他名称,请确保也调整代码 compute_target='cpu-cluster' 中的名称。
了解代码更改
env = ...
引用前面创建的依赖项文件。
config.run_config.environment = env
将该环境添加到 ScriptRunConfig。
将该运行提交到 Azure 机器学习
选择“保存并在终端中运行脚本”来运行 run-pytorch.py 脚本。
你会在打开的终端窗口中看到链接。 选择该链接以查看作业。
注意
你可能看到以“加载 azureml_run_type_providers.... 时出错”开头的警告。可以忽略这些警告。 使用这些警告底部的链接查看输出。
查看输出
- 在打开的页面中,你会看到作业状态。 首次运行此脚本时,Azure 机器学习会从 PyTorch 环境生成新的 Docker 映像。 完成整个作业可能需要约 10 分钟的时间。 在将来的作业中将会重复使用此映像,以加快作业的运行速度。
- 可以在 Azure 机器学习工作室中查看 Docker 生成日志。 要查看生成日志:
- 选择“输出 + 日志”选项卡。
- 选择“azureml-logs”文件夹。
- 选择“20_image_build_log.txt”。
- 作业状态为“已完成”时,选择“输出 + 日志”。
- 依次选择“user_logs”、“std_log.txt”以查看作业的输出。
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
如果看到错误 Your total snapshot size exceeds the limit,则表明数据文件夹位于在 中使用的 source_directory 中。
选择文件夹末尾的“...”,然后选择“移动”,将“数据”移动到 get-started 文件夹 。
记录训练指标
你已在 Azure 机器学习中进行了模型训练,可以开始跟踪一些性能指标了。
当前训练脚本将指标输出到终端。 Azure 机器学习提供了一种机制,用于记录具有更多功能的指标。 通过添加几行代码,你可以在工作室中可视化指标并在多个作业之间比较指标。
修改 train.py 以包含日志记录
修改 train.py 脚本,以包含另外两行代码:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to Azure Machine Learning run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')保存此文件,然后根据需要关闭该选项卡。
了解这两行额外添加的代码
在 train.py 中,你通过使用 方法从训练脚本本身中访问 run 对象,并使用该对象来记录指标:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to Azure Machine Learning
run.log('loss', loss)
Azure 机器学习中的指标具有以下特点:
- 按试验和运行进行组织,因此可以轻松地跟踪和比较指标。
- 配备了一个 UI,使你能够在工作室中可视化训练性能。
- 设计用于进行扩展,因此即使在运行数百个试验的情况下,你也始终有这些优势。
更新 Conda 环境文件
train.py 脚本只有一个依赖于 azureml.core 的新依赖项。 更新 pytorch-env.yml 以反映此更改:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
请确保在提交运行之前保存此文件。
将该运行提交到 Azure 机器学习
选择 run-pytorch.py 脚本的选项卡,然后选择“保存并在终端中运行脚本”,来重新运行 run-pytorch.py 脚本。 请确保先将更改保存到pytorch-env.yml。
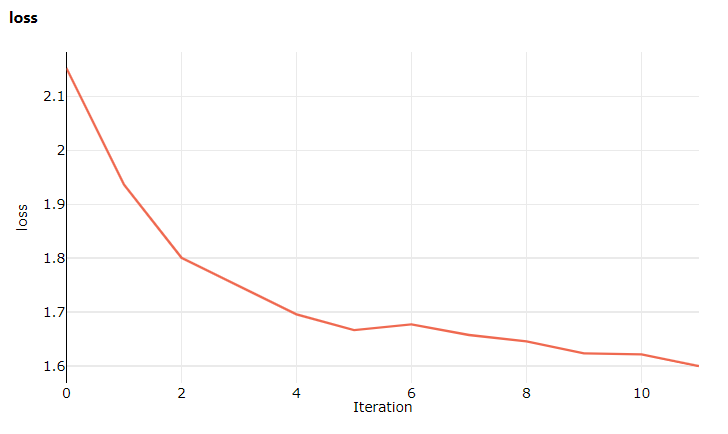
这一次,当你访问工作室时,请转到“指标”选项卡,此时可以看到有关模型训练损失的实时更新! 训练开始之前可能需要 1 到 2 分钟。
清理资源
如果你现在打算继续学习另一个教程,或者开始自己的训练作业,请跳到相关资源。
停止计算实例
如果不打算现在使用它,请停止计算实例:
- 在工作室的左侧,选择“计算”。
- 在顶部选项卡中,选择“计算实例”
- 在列表中选择该计算实例。
- 在顶部工具栏中,选择“停止”。
删除所有资源
重要
已创建的资源可用作其他 Azure 机器学习教程和操作方法文章的先决条件。
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
在 Azure 门户的搜索框中输入“资源组”,然后从结果中选择它。
从列表中选择你创建的资源组。
在“概述”页面上,选择“删除资源组”。
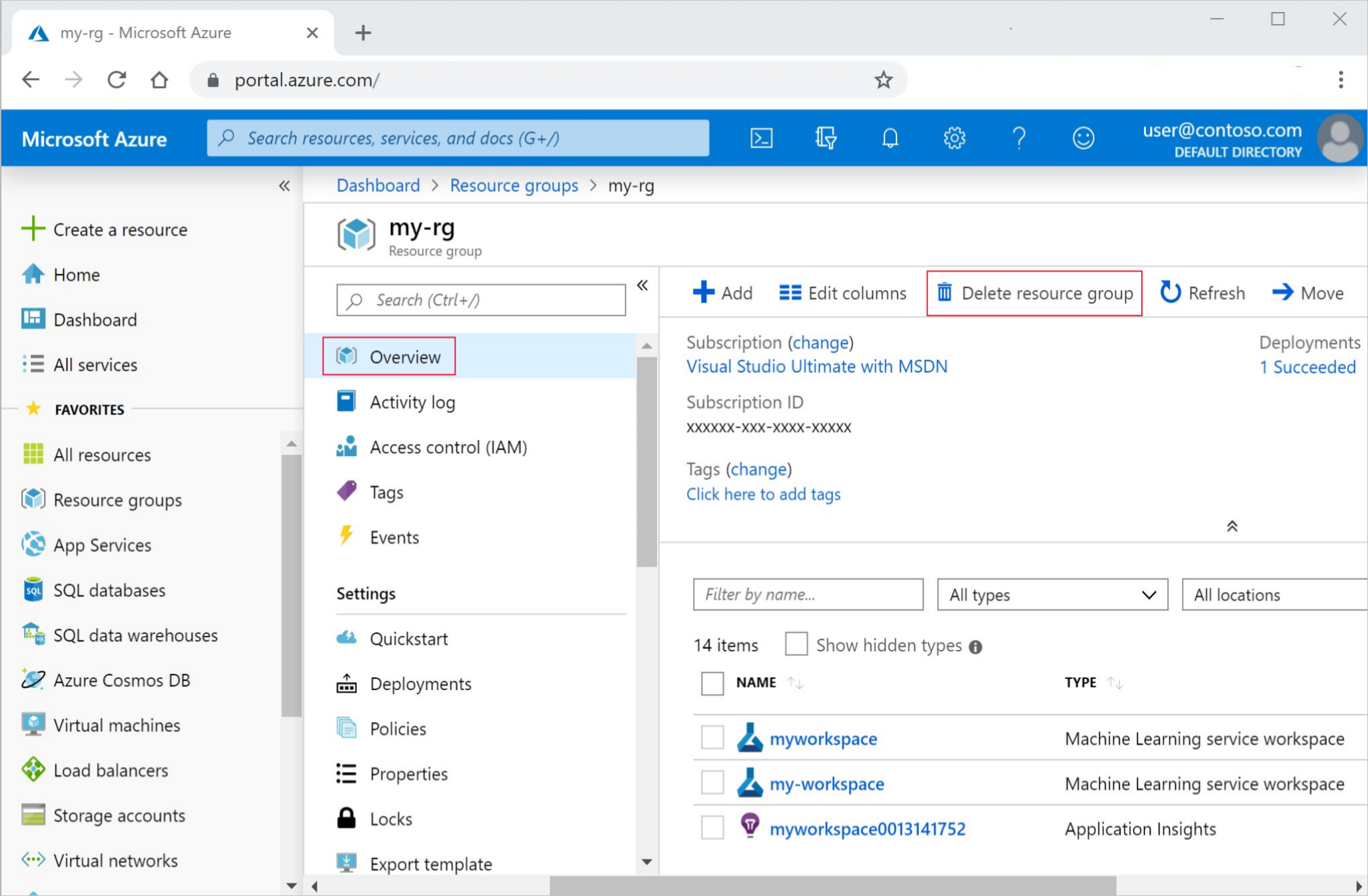
输入资源组名称。 然后选择“删除”。
还可保留资源组,但请删除单个工作区。 显示工作区属性,然后选择“删除”。
相关资源
在此会话中,你从基本的“Hello world!”脚本升级到了需要特定 Python 环境来运行的更现实的训练脚本。 你已了解如何使用特选的 Azure 机器学习环境。 最后,你看到了如何通过几行代码将指标记录到 Azure 机器学习。
创建 Azure 机器学习环境还有其他方法,包括从 pip 的 requirements.txt 文件创建,或者从现有的本地 Conda 环境创建。