Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.

本文介绍如何使用 Azure 机器学习 SDK 来创建并运行机器学习管道。 使用 ML 管道来创建将各种不同 ML 阶段拼结在一起的工作流。 然后发布该管道,以便以后访问或与他人共享。 跟踪 ML 管道,以了解模型在实际应用场合的表现并检测数据偏移。 ML 管道非常适合用于批量评分方案、使用多种计算的情况、重复使用步骤而不是重新运行的情况,以及与他人共享 ML 工作流的情况。
本文不是教程。 有关创建首个管道的指南,请参阅教程:生成用于批量评分的 Azure 机器学习管道或在 Python 的 Azure 机器学习管道中使用自动化 ML。
尽管可以使用另一种称为 Azure 管道的管道来实现 ML 任务的 CI/CD 自动化,但这种类型的管道不会存储在工作区中。 比较这些不同的管道。
Azure 机器学习工作区的成员可以看到创建的 ML 管道。
ML 管道在计算目标上执行(请参阅 Azure 机器学习中的计算目标是什么)。 管道可以在支持的 Azure 存储文档位置读取和写入数据。
如果没有 Azure 订阅,可在开始前创建一个试用帐户。 试用免费版或付费版 Azure 机器学习。
先决条件
Azure 机器学习工作区。 创建工作区资源。
配置开发环境以安装 Azure 机器学习 SDK,或使用已经安装了 SDK 的 Azure 机器学习计算实例。
首先附加工作区:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
设置机器学习资源
创建运行 ML 管道所需的资源:
设置一个数据存储,用于访问管道步骤中所需的数据。
配置
Dataset对象,使之指向驻留在数据存储中的或可在数据存储中访问的持久性数据。 为在管道步骤间传递的临时数据配置OutputFileDatasetConfig对象。设置计算目标,管道步骤将在其上运行。
设置数据存储
数据存储用于存储可供管道访问的数据。 每个工作区有一个默认的数据存储。 你可以注册更多数据存储。
创建工作区时,会将 Azure 文件存储和 Azure Blob 存储附加到该工作区。 已注册一个用于连接 Azure Blob 存储的默认数据存储。 要了解详细信息,请参阅确定何时使用 Azure 文件存储、Azure Blob 或 Azure 磁盘。
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
步骤通常使用数据并生成输出数据。 步骤可以创建数据,例如模型、包含模型和依赖文件的目录,或临时数据。 然后,此数据可供管道中的其他后续步骤使用。 若要详细了解如何将管道连接到数据,请参阅如何访问数据和如何注册数据集这两篇文章。
使用 Dataset 和 OutputFileDatasetConfig 对象配置数据
向管道提供数据的首选方法是使用 Dataset 对象。 Dataset 对象指向驻留在数据存储中的或者可从数据存储或 Web URL 访问的数据。 Dataset 类是抽象类,因此你将创建 FileDataset(引用一个或多个文件)或 TabularDataset(由一个或多个具有分隔数据列的文件创建)的实例。
使用 from_files 或 from_delimited_files 之类的方法来创建 Dataset。
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
中间数据(或步骤的输出)由 PipelineData 对象表示。 output_data1 生成为步骤的输出。 还可以调用 register_on_complete 将此数据注册为数据集。 如果在一个步骤中创建一个 OutputFileDatasetConfig 并将其作为另一个步骤的输入,这种步骤之间的数据依赖关系将在管道中创建一个隐式的执行顺序。
OutputFileDatasetConfig 对象返回目录,并且默认将输出写入工作区的默认数据存储。
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
重要
Azure 不会自动删除使用 OutputFileDatasetConfig 存储的中间数据。
你应以编程方式在管道运行结束时删除中间数据,使用具有短数据保留策略的数据存储,或定期执行手动清理。
提示
只上传与当前工作相关的文件。 数据目录内任何文件的更改都将被视为下次运行管道时重新运行该步骤的理由,即使指定了重复使用。
设置计算目标
在 Azure 机器学习中,术语“计算”(或“计算目标”)是指在机器学习管道中执行计算步骤的计算机或群集 。 请参阅用于模型训练的计算目标以获取计算目标的完整列表,并参阅创建计算目标以了解如何创建计算目标并将其附加到工作区。 无论是要训练模型还是要运行管道步骤,创建和/或附加计算目标的过程都是相同的。 创建并附加计算目标后,请使用管道步骤中的 ComputeTarget 对象。
重要
内部远程作业不支持对计算目标执行管理操作。 由于机器学习管道作为远程作业提交,因此请勿对管道内的计算目标使用管理操作。
Azure 机器学习计算
可以创建 Azure 机器学习计算用于运行步骤。 其他计算目标的代码与此类似,只是参数会因类型的不同而略有差异。
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
配置训练运行的环境
下一步是确保远程训练运行包含训练步骤所需的所有依赖项。 通过创建和配置 RunConfiguration 对象来设置依赖项和运行时上下文。
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
以上代码显示了处理依赖项的两个选项。 如前所述,当 USE_CURATED_ENV = True,配置基于特选环境。 特选环境中“预先准备”有常见的互依赖库,可以加快联机速度。 特选环境在 Microsoft 容器注册表中具有预先生成的 Docker 映像。 有关详细信息,请参阅 Azure 机器学习特选环境。
将 USE_CURATED_ENV 更改为 False 所采用的路径显示了显式设置依赖项的模式。 在这种情况下,将在资源组内的 Azure 容器注册表中创建和注册新的自定义 Docker 映像(请参阅 Azure 中的专用 Docker 容器注册表简介)。 创建和注册此映像可能需要几分钟的时间。
构造管道步骤
创建计算资源和环境后,即可定义管道的步骤。 Azure 机器学习 SDK 提供了许多内置步骤,如 azureml.pipeline.steps 包的参考文档中所示。 最灵活的类是运行 Python 脚本的 PythonScriptStep。
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
上述代码展示了典型的初始管道步骤。 数据准备代码位于子目录中(在此示例中,"prepare.py" 位于目录 "./dataprep.src" 中)。 在管道创建的过程中,此目录将被压缩并上传到 compute_target,该步骤会运行指定为 script_name 的值的脚本。
arguments 值指定该步骤的输入和输出。 在上面的示例中,基线数据是 my_dataset 数据集。 相应数据会下载到计算资源,因为代码将其指定为 as_download()。 脚本 prepare.py 执行与手头任务相应的任何数据转换任务,并将数据输出到 OutputFileDatasetConfig 类型的 output_data1。 有关详细信息,请参阅将数据移入 ML 管道和在 ML 管道之间移动数据的步骤 (Python)。
该步骤将使用配置 aml_run_config 在由 compute_target 定义的计算机上运行。
在协作环境中使用管道时,重复使用以前的结果 (allow_reuse) 非常关键,因为消除不必要的重新运行可以提高敏捷性。 当步骤的 script_name、输入和参数保持不变时,“重复使用”是默认行为。 允许重复使用时,上一次运行的结果将立即发送到下一步骤。 如果 allow_reuse 设置为 False,则在管道执行过程中将始终为此步骤生成新的运行。
虽然可以通过单个步骤创建管道,但你几乎始终会选择将整个过程拆分为几个步骤。 例如,你可能有用于数据准备、训练、模型比较和部署的步骤。 例如,可以想象,在上面指定 data_prep_step 之后,下一步可能是训练:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
上述代码与数据准备步骤中的代码非常相似。 训练代码位于与数据准备代码不同的目录中。 数据准备步骤的 OutputFileDatasetConfig 输出 output_data1 用作训练步骤的输入。 创建了一个新的 OutputFileDatasetConfig 对象 training_results,用来保存结果以在稍后的比较或部署步骤中使用。
有关其他代码示例,请参阅如何生成两步 ML 管道和如何在运行完成时将数据写回数据存储。
定义步骤后,使用其中的部分或所有步骤生成管道。
注意
定义步骤或生成管道时,不会将任何文件或数据上传到 Azure 机器学习。 文件会在你调用 Experiment.submit() 时上传。
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
使用数据集
从 Azure Blob 存储、Azure 文件存储、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure SQL 数据库和 Azure Database for PostgreSQL 创建的数据集可以用作任何管道步骤的输入。 可以将输出写入 DataTransferStep、DatabricksStep,如果要将数据写入特定数据存储,请使用 OutputFileDatasetConfig。
重要
仅 Azure Blob、Azure 文件共享、ADLS Gen 1 和 Gen 2数据存储支持使用 OutputFileDatasetConfig 将输出数据写回到数据存储。
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
然后,使用 Run.input_datasets 字典检索管道中的数据集。
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Run.get_context() 行值得强调。 此函数检索 Run(表示当前试验运行)。 在上面的示例中,我们使用它来检索已注册数据集。 Run 对象的另一个常见用途是检索试验本身和试验所在的工作区:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
有关更多详细信息(包括传递数据和访问数据的替代方法),请参阅将数据移入 ML 管道步骤和在 ML 管道步骤之间移动数据 (Python)。
缓存和重复使用
若要优化和自定义管道的行为,可以围绕缓存和重复使用来采取某些措施。 例如,可以选择:
- 在步骤定义期间通过设置
allow_reuse=False来禁用默认的重复使用步骤运行输出的行为。 在协作环境中使用管道时,“重复使用”非常关键,因为消除不必要的运行可以提高敏捷性。 但是,可以选择禁用重复使用。 - 使用
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)强制对运行中的所有步骤重新生成输出
默认情况下,已启用步骤的 allow_reuse,步骤定义中指定的 source_directory 将进行哈希处理。 因此,如果给定步骤的脚本保持不变(script_name、输入和参数)并且 source_directory 中的其他内容没有更改,则会重用上一步运行的输出,不会将作业提交到计算,而上一步运行的结果立即可用于下一步。
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
注意
如果数据输入的名称发生更改,该步骤将重新运行,即使基础数据未更改。 必须显式设置输入数据 (data.as_input(name=...)) 的 name 字段。 如果未显式设置此值,则会将 name 字段设置为一个随机 GUID,并且不会重用该步骤的结果。
提交管道
提交管道时,Azure 机器学习将检查每个步骤的依赖项,并上传指定的源目录的快照。 如果未指定源目录,则上传当前的本地目录。 该快照也作为试验的一部分存储在工作区中。
重要
为了防止在快照中包含不必要的文件,请在目录中创建 ignore 文件(.gitignore 或 .amlignore)。 将要排除的文件和目录添加到此文件中。 有关此文件中使用的语法的详细信息,请参阅 .gitignore 的语法和模式。 .amlignore 文件使用相同的语法。 如果同时存在这两个文件,则会使用 .amlignore 文件,不会使用 .gitignore 文件。
有关详细信息,请参阅快照。
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
第一次运行管道时,Azure 机器学习会:
将项目快照从与工作区关联的 Blob 存储下载到计算目标。
生成对应于管道中每个步骤的 Docker 映像。
将每个步骤的 Docker 映像从容器注册表下载到计算目标。
配置对
Dataset和OutputFileDatasetConfig对象的访问权限。 在as_mount()访问模式下,FUSE 用于提供虚拟访问。 如果不支持装载,或者如果用户将访问指定为as_upload(),则改为将数据复制到计算目标。运行在步骤定义中指定的计算目标中的步骤。
创建项目,例如日志、stdout 和 stderr、指标以及步骤指定的输出。 然后上传这些项目并将其保存在用户的默认数据存储中。
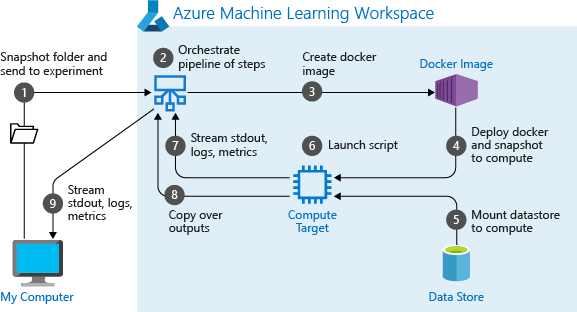
有关详细信息,请参阅 Experiment 类参考。
对推理时更改的参数使用管道参数
有时,管道内单个步骤的自变量与开发和训练时段相关:例如训练率和动量或数据或配置文件的路径等。 但是,在部署模型时,需要动态传递用于推理的自变量(即生成的模型要响应的查询!)。 应将这些类型的自变量设置为管道参数。 若要在 Python 中执行此操作,请使用 azureml.pipeline.core.PipelineParameter 类,如下面的代码片段所示:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Python 环境如何处理管道参数
如先前在配置训练运行的环境中所讨论的一样,环境状态和 Python 库依赖项是使用 Environment 对象所指定。 通常,可以通过引用现有 Environment 的名称和版本(可选)来指定它:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
但是,如果选择使用 PipelineParameter 对象在运行时为管道步骤动态设置变量,则不能使用这种引用现有 Environment 的技术。 而如果想要使用 PipelineParameter 对象,则必须将 RunConfiguration 的 environment 字段设置为 Environment 对象。 你需要负责确保此类 Environment 正确设置了它对外部 Python 包的依赖项。
查看管道的结果
在工作室中查看所有管道的列表及其运行详细信息:
登录到 Azure 机器学习工作室。
在左侧,选择“管道”以查看所有管道运行。
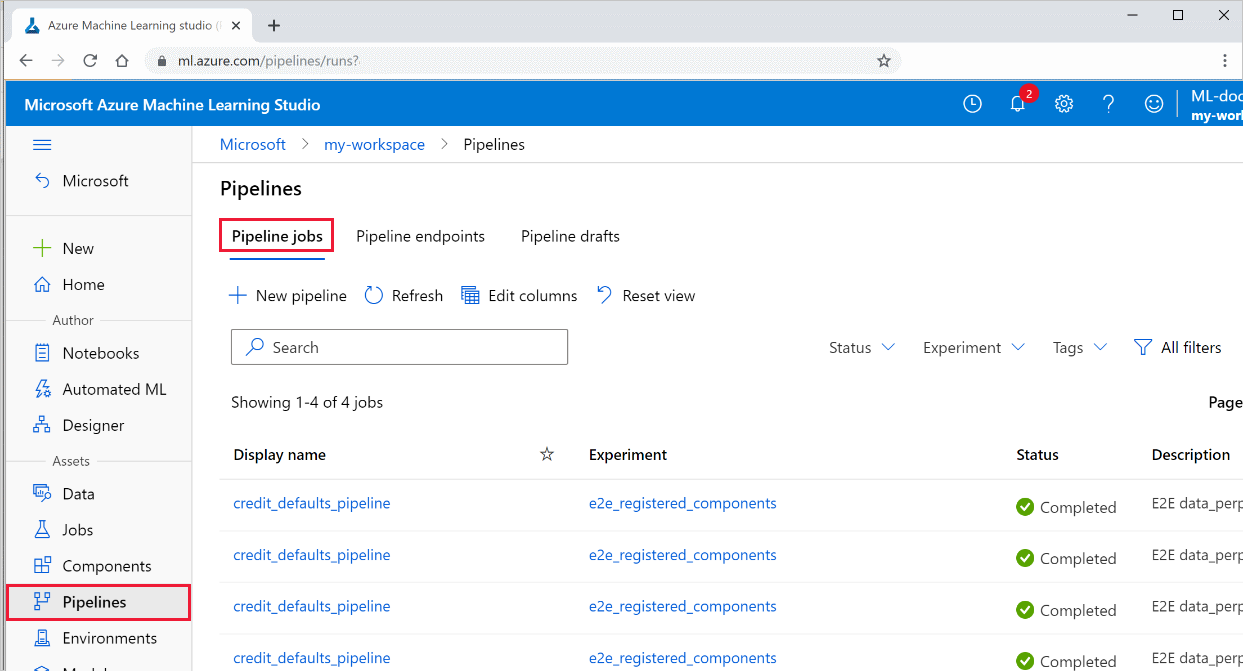
选择特定的管道以查看运行结果。
Git 跟踪与集成
如果以本地 Git 存储库作为源目录开始训练运行,有关存储库的信息将存储在运行历史记录中。 有关详细信息,请参阅 Azure 机器学习的 Git 集成。
后续步骤
- 若要与同事或客户共享管道,请参阅发布机器学习管道
- 使用 GitHub 上的这些 Jupyter 笔记本来进一步探索机器学习管道
- 参阅有关 azureml-pipelines-core 包和 azureml-pipelines-steps 包的 SDK 参考帮助信息
- 参阅操作指南,以获取有关调试管道和排查管道问题的提示。
- 阅读使用 Jupyter 笔记本探索此服务一文,了解如何运行笔记本。