Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.

本教程介绍了如何在 Azure 机器学习中上传并使用你自己的数据来训练机器学习模型。 本教程是由三个部分构成的教程系列的第 3 部分。
在第 2 部分:训练模型中,你已使用 PyTorch 中的示例数据在云中训练了一个模型。 你还通过 PyTorch API 中的 torchvision.datasets.CIFAR10 方法下载了这些数据。 在本教程中,你将使用下载的数据来了解用于在 Azure 机器学习中处理自己数据的工作流。
在本教程中,你将了解:
- 将数据上传到 Azure。
- 创建控制脚本。
- 了解新的 Azure 机器学习概念(传递参数、数据集、数据存储)。
- 提交并运行训练脚本。
- 在云中查看代码输出。
先决条件
需要上一教程中下载的数据。 请确保已完成以下步骤:
调整训练脚本
现在,你的训练脚本 (get-started/src/train.py) 已在 Azure 机器学习中运行,并且你可以监视模型性能。 让我们通过引入参数来将训练脚本参数化。 使用参数可轻松比较不同的超参数。
我们的训练脚本目前设置为在每次运行时下载 CIFAR10 数据集。 以下 Python 代码已调整为从某个目录中读取数据。
注意
使用 argparse 将脚本参数化。
打开 train.py 并将其替换为以下代码:
import os import argparse import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run run = Run.get_context() if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_path', type=str, help='Path to the training data' ) parser.add_argument( '--learning_rate', type=float, default=0.001, help='Learning rate for SGD' ) parser.add_argument( '--momentum', type=float, default=0.9, help='Momentum for SGD' ) args = parser.parse_args() print("===== DATA =====") print("DATA PATH: " + args.data_path) print("LIST FILES IN DATA PATH...") print(os.listdir(args.data_path)) print("================") # prepare DataLoader for CIFAR10 data transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) trainset = torchvision.datasets.CIFAR10( root=args.data_path, train=True, download=False, transform=transform, ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD( net.parameters(), lr=args.learning_rate, momentum=args.momentum, ) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 run.log('loss', loss) # log loss metric to AML print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')保存文件。 如果需要,请关闭选项卡。
了解代码更改
train.py 中的代码已使用 argparse 库来设置 data_path、learning_rate 和 momentum。
# .... other code
parser = argparse.ArgumentParser()
parser.add_argument('--data_path', type=str, help='Path to the training data')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Learning rate for SGD')
parser.add_argument('--momentum', type=float, default=0.9, help='Momentum for SGD')
args = parser.parse_args()
# ... other code
此外,train.py 脚本已经过改编,以将优化器更新为使用用户定义的参数:
optimizer = optim.SGD(
net.parameters(),
lr=args.learning_rate, # get learning rate from command-line argument
momentum=args.momentum, # get momentum from command-line argument
)
将数据上传到 Azure
若要在 Azure 机器学习中运行此脚本,需要使训练数据在 Azure 中可用。 Azure 机器学习工作区附带默认的数据存储。 这是一个 Azure Blob 存储帐户,你可以在其中存储训练数据。
注意
Azure 机器学习允许连接其他基于云的数据存储,用来存储你的数据。 有关详细信息,请参阅数据存储文档。
在 get-started 文件夹中创建新的 Python 控制脚本(请务必在 get-started 而不是 /src 文件夹中创建) 。 将该脚本命名为 upload-data.py,并将以下代码复制到该文件中:
# upload-data.py from azureml.core import Workspace from azureml.core import Dataset from azureml.data.datapath import DataPath ws = Workspace.from_config() datastore = ws.get_default_datastore() Dataset.File.upload_directory(src_dir='data', target=DataPath(datastore, "datasets/cifar10") )target_path值指定 CIFAR10 数据将要上传到的数据存储的路径。提示
在使用 Azure 机器学习上传数据时,可以使用 Azure 存储资源管理器来上传临时文件。 如果需要 ETL 工具,可以使用 Azure 数据工厂将数据引入 Azure。
选择“保存并在终端中运行脚本”来运行 upload-data.py 脚本。
应该会看到以下标准输出:
Uploading ./data\cifar-10-batches-py\data_batch_2 Uploaded ./data\cifar-10-batches-py\data_batch_2, 4 files out of an estimated total of 9 . . Uploading ./data\cifar-10-batches-py\data_batch_5 Uploaded ./data\cifar-10-batches-py\data_batch_5, 9 files out of an estimated total of 9 Uploaded 9 files
创建控制脚本
如之前所做的那样,在 get-started 文件夹中新建名为 run-pytorch-data.py 的 Python 控制脚本:
# run-pytorch-data.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
from azureml.core import Dataset
if __name__ == "__main__":
ws = Workspace.from_config()
datastore = ws.get_default_datastore()
dataset = Dataset.File.from_files(path=(datastore, 'datasets/cifar10'))
experiment = Experiment(workspace=ws, name='day1-experiment-data')
config = ScriptRunConfig(
source_directory='./src',
script='train.py',
compute_target='cpu-cluster',
arguments=[
'--data_path', dataset.as_named_input('input').as_mount(),
'--learning_rate', 0.003,
'--momentum', 0.92],
)
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print("Submitted to compute cluster. Click link below")
print("")
print(aml_url)
提示
如果在创建计算群集时使用了其他名称,请确保也调整代码 compute_target='cpu-cluster' 中的名称。
了解代码更改
该控制脚本类似于此系列第 3 部分中的控制脚本,包含以下新行:
dataset = Dataset.File.from_files( ... )
数据集用于引用上传到 Azure Blob 存储的数据。 数据集是基于数据的抽象层,旨在提高可靠性和可信任性。
config = ScriptRunConfig(...)
ScriptRunConfig 已修改,包含将传递到 train.py 中的参数列表。 dataset.as_named_input('input').as_mount() 参数表示指定的目录将会被装载到计算目标。
将该运行提交到 Azure 机器学习
选择“保存并在终端中运行脚本”以运行 run-pytorch-data.py 脚本。 此运行将使用你上传的数据在计算群集上训练模型。
此代码将会在 Azure 机器学习工作室中输出一个指向试验的 URL。 如果访问该链接,就可以看到代码在运行。
注意
你可能看到以“加载 azureml_run_type_providers.... 时出错”开头的警告。可以忽略这些警告。 使用这些警告底部的链接查看输出。
检查日志文件
在工作室中,转到实验作业(通过选择先前的 URL 输出),然后选择“输出 + 日志”。 选择 std_log.txt 文件。 向下滚动日志文件,直到看到以下输出:
Processing 'input'.
Processing dataset FileDataset
{
"source": [
"('workspaceblobstore', 'datasets/cifar10')"
],
"definition": [
"GetDatastoreFiles"
],
"registration": {
"id": "XXXXX",
"name": null,
"version": null,
"workspace": "Workspace.create(name='XXXX', subscription_id='XXXX', resource_group='X')"
}
}
Mounting input to /tmp/tmp9kituvp3.
Mounted input to /tmp/tmp9kituvp3 as folder.
Exit __enter__ of DatasetContextManager
Entering Job History Context Manager.
Current directory: /mnt/batch/tasks/shared/LS_root/jobs/dsvm-aml/azureml/tutorial-session-3_1600171983_763c5381/mounts/workspaceblobstore/azureml/tutorial-session-3_1600171983_763c5381
Preparing to call script [ train.py ] with arguments: ['--data_path', '$input', '--learning_rate', '0.003', '--momentum', '0.92']
After variable expansion, calling script [ train.py ] with arguments: ['--data_path', '/tmp/tmp9kituvp3', '--learning_rate', '0.003', '--momentum', '0.92']
Script type = None
===== DATA =====
DATA PATH: /tmp/tmp9kituvp3
LIST FILES IN DATA PATH...
['cifar-10-batches-py', 'cifar-10-python.tar.gz']
注意:
- Azure 机器学习已自动为你将 Blob 存储装载到计算群集。
- 控制脚本中使用的
dataset.as_named_input('input').as_mount()将解析为装入点。
清理资源
如果你现在打算继续学习另一个教程,或者开始自己的训练作业,请跳到后续步骤。
停止计算实例
如果不打算现在使用它,请停止计算实例:
- 在工作室的左侧,选择“计算”。
- 在顶部选项卡中,选择“计算实例”
- 在列表中选择该计算实例。
- 在顶部工具栏中,选择“停止”。
删除所有资源
重要
已创建的资源可用作其他 Azure 机器学习教程和操作方法文章的先决条件。
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
在 Azure 门户中,选择最左侧的“资源组” 。
从列表中选择你创建的资源组。
选择“删除资源组”。
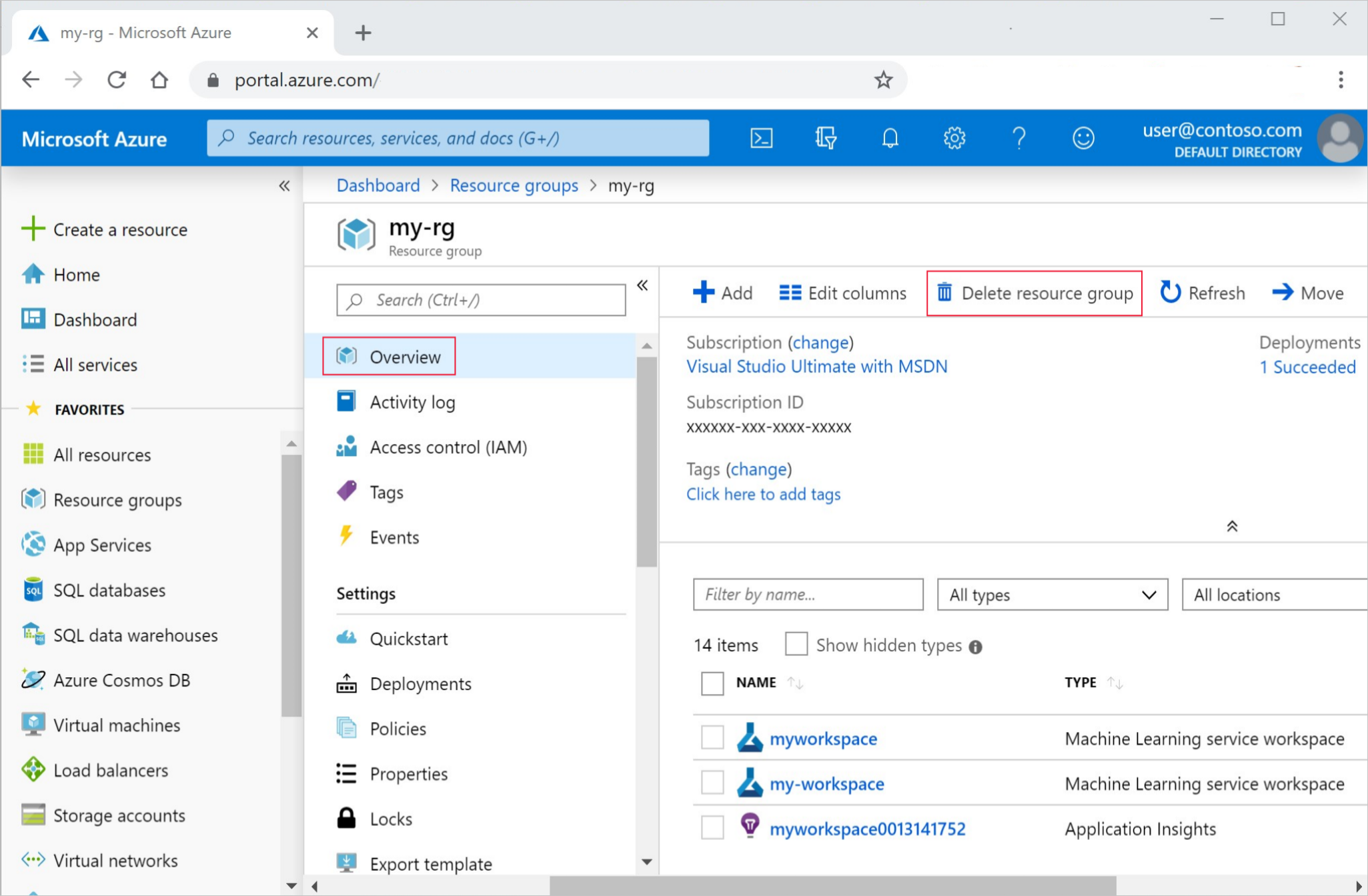
输入资源组名称。 然后选择“删除”。
还可保留资源组,但请删除单个工作区。 显示工作区属性,然后选择“删除”。
后续步骤
在本教程中,我们了解了如何通过使用 Datastore 将数据上传到 Azure。 数据存储充当工作区的云存储,为你提供了一个持久且灵活的数据保存位置。
你已了解如何修改训练脚本,以通过命令行接受数据路径。 通过使用 Dataset,能够将目录装载到远程作业。
有了模型后,接下来请学习: