Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
使用 Azure 机器学习设计器训练用于预测汽车价格的线性回归模型。 本教程是由两个部分构成的系列教程的第一部分。
本教程使用 Azure 机器学习设计器,有关详细信息,请参阅什么是 Azure 机器学习设计器?
注意
设计器支持两种类型的组件:经典预生成组件 (v1) 和自定义组件 (v2)。 这两种类型的组件不兼容。
经典预生成组件主要为数据处理和传统的机器学习任务(如回归和分类)提供预生成组件。 此类型的组件将继续受支持,但不会增加任何新组件。
自定义组件允许以组件的形式包装自己的代码。 它支持跨工作区共享组件,并跨 Studio、CLI v2 和 SDK v2 接口进行无缝创作。
对于新项目,强烈建议使用自定义组件,它与 AzureML V2 兼容,并且会不断接收新更新。
本文适用于经典预生成组件,与 CLI v2 和 SDK v2 不兼容。
本教程的第一部分介绍如何执行以下操作:
- 创建新管道。
- 导入数据。
- 准备数据。
- 训练机器学习模型。
- 评估机器学习模型。
在本教程的第二部分中,请将模型部署为实时推理终结点,以根据你发送给它的技术规格来预测任何汽车的价格。
注意
我们提供了本教程的已完成版本作为示例管道。
若要找到该示例,请转到工作区中的设计器。 在“新建管道部分,选择”示例 1 - 回归: 汽车价格预测(基本)”。
重要
如果看不到本文档中提到的图形元素(例如工作室或设计器中的按钮),则你可能没有适当级别的工作区权限。 请与 Azure 订阅管理员联系,验证是否已向你授予正确级别的访问权限。 有关详细信息,请参阅管理用户和角色。
创建新管道
Azure 机器学习管道可将多个机器学习和数据处理步骤组织成单个资源。 管道可让你在不同的项目和用户之间组织、管理与重用复杂的机器学习工作流。
若要创建 Azure 机器学习管道,需要一个 Azure 机器学习工作区。 本部分介绍如何创建这两个资源。
创建新的工作区
需要一个 Azure 机器学习工作区来使用设计器。 工作区是 Azure 机器学习的顶级资源,提供一个中心位置用于处理 Azure 机器学习中创建的所有项目。 有关创建工作区的说明,请参阅创建工作区资源。
注意
如果工作区使用虚拟网络,则必须执行其他配置步骤才能使用设计器。 有关详细信息,请参阅在 Azure 虚拟网络中使用 Azure 机器学习工作室
创建管道
注意
设计器支持两种类型的组件:经典预生成组件和自定义组件。 这两种类型的组件不兼容。
经典预生成组件主要为数据处理和传统的机器学习任务(如回归和分类)提供预生成组件。 此类型的组件将继续受支持,但不会增加任何新组件。
自定义组件允许你以组件的形式提供自己的代码。 它支持跨工作区共享,以及跨 Studio、CLI 和 SDK 接口进行无缝创作。
本文适用于经典预生成组件。
登录到 studio.ml.azure.cn,选择要使用的工作区。
选择“设计器”->“经典预生成”

选择“使用经典预生成组件创建新管道”。
单击自动生成的管道草稿名称旁边的铅笔图标,将其重命名为“汽车价格预测”。 名称不需唯一。

设置默认计算目标
管道在计算目标上工作,该目标是附加到工作区的计算资源。 创建计算目标后,就可以在以后的作业中重用它。
重要
不支持附加计算,请改用计算实例或群集。
可为整个管道设置默认计算目标,告知每个组件要默认使用同一个计算目标。 但是,可以基于每个模块指定计算目标。
选择画布右侧的
 “设置”以打开“设置”窗格。
“设置”以打开“设置”窗格。选择“创建 Azure 机器学习计算实例”。
如果已有可用的计算目标,可以从“选择 Azure 机器学习计算实例”下拉列表中选择它以运行此管道。
或者选择“无服务器”以使用无服务器计算(预览版)。
输入计算资源的名称。
选择“创建”。
注意
创建计算资源大约需要五分钟。 创建资源之后,可以重用它,并对将来的作业跳过此等待时间。
计算资源在空闲时会自动缩放为 0 个节点以节省成本。 在延迟之后再次使用它时,可能会经历大约五分钟的等待时间,同时它会重新扩展。
导入数据
此设计器中包含多个示例数据集供你进行试验。 本教程使用“汽车价格数据(原始)”。
管道画布左侧是数据集和组件的控制板。 选择“组件”->“示例数据”。
选择数据集“汽车价格数据(原始)”,然后将其拖到画布上。

可视化数据
可将数据可视化以了解要使用的数据集。
右键单击“汽车价格数据(原始)”并选择“预览数据”。
选择数据窗口中的不同列,查看有关每个列的信息。
每行代表一辆汽车,与每辆汽车关联的变量显示为列。 此数据集中有 205 行和 26 列。
准备数据
数据集通常需要在分析之前经过某种预处理。 在检查数据集时,你可能已经注意到某些值缺失。 必须清除这些缺失值,使模型能够正确分析数据。
删除列
训练模型时,必须对缺失的数据执行某些操作。 在此数据集中,normalized-losses 列缺失许多值,因此需要从模型中完全排除该列。
在画布左侧的数据集和组件面板中,单击“组件”并搜索“选择数据集中的列”组件。
将“在数据集中选择列”组件拖到画布上。 将该组件拖至数据集组件下方。
将“汽车价格数据(原始)”数据集连接到“在数据集中选择列”组件 。 从数据集的输出端口(画布上数据集底部的小圆圈)拖到“在数据集中选择列”的输入端口(组件顶部的小圆圈)。
提示
将一个组件的输出端口连接到另一个组件的输入端口时,可通过管道创建数据流。

选择“在数据集中选择列”组件。
单击画布右侧的“设置”下的箭头图标,以打开组件详细信息窗格。 或者,可以双击“选择数据集中的列”组件以打开详细信息窗格。
选择窗格右侧的“编辑列”。
展开“包含”旁边的“列名”下拉列表,然后选择“所有列”。
选择 + 以添加新规则。
在下拉菜单中,选择“排除”和“列名”。
在文本框中输入“normalized-losses”。
在右下角,选择“保存”以关闭列选择器。

在“选择数据集中的列”组件详细信息窗格中,展开“节点信息”。
选择“注释”文本框并输入“排除归一化损失”。
注释将显示在图形中,以帮助你组织管道。
清理缺失数据
删除“normalized-losses”列后,数据集仍缺失值。 可以使用“清理缺失数据”组件来删除剩余的缺失数据。
提示
在设计器中使用大多数组件时,都必须从输入数据中清除缺失值。
在画布左侧的数据集和组件面板中,单击“组件”并搜索“清理缺失数据”组件。
将“清理缺失数据”组件拖到管道画布上。 将它连接到“在数据集中选择列”组件。
选择“清理缺失数据”组件。
单击画布右侧的“设置”下的箭头图标,以打开组件详细信息窗格。 或者,可以双击“清理缺失数据”组件以打开详细信息窗格。
选择窗格右侧的“编辑列”。
在出现的“要清理的列”窗口中,展开“包括”旁边的下拉菜单。 选择“所有列”
选择“保存”
在“清理缺失数据”组件详细信息窗格中的“清理模式”下,选择“删除整行”。
在“清理缺失数据”组件详细信息窗格中,展开“节点信息”。
选择“注释”文本框并输入“删除缺失值行”。
管道现在应如下所示:

训练机器学习模型
现已准备好用于处理数据的组件,接下来可以设置训练组件。
由于你要预测价格(一个数字),因此可以使用回归算法。 本示例将使用线性回归模型。
拆分数据
拆分数据是机器学习中的一项常见任务。 你需要将数据拆分成两个独立的数据集。 一个数据集训练模型,另一个数据集测试模型的表现。
在画布左侧的数据集和组件面板中,单击“组件”并搜索“拆分数据”组件。
将“拆分数据”组件拖到管道画布上。
将“清理缺失数据”组件的左侧端口连接到“拆分数据”组件 。
重要
请确保“清理缺失数据”的左侧输出端口连接到“拆分数据”。 左侧端口包含清理的数据。 右侧端口包含丢弃的数据。
选择“拆分数据”组件。
单击画布右侧的“设置”下的箭头图标,以打开组件详细信息窗格。 或者,可以双击“拆分数据”组件以打开详细信息窗格。
在“拆分数据”详细信息窗格中,将“第一个输出数据集中的行的比例”设置为 0.7。
此选项使用 70% 的数据来训练模型,保留 30% 的数据用于测试。 可通过左侧输出端口访问 70% 的数据集。 可通过右侧输出端口访问剩余的数据。
在“拆分数据”详细信息窗格中,展开“节点信息”。
选择“注释”文本框,并且输入“将数据集拆分为训练集(0.7)和测试集(0.3)”。
定型模型
在模型中提供包含价格的数据集以对其进行训练。 算法将构造一个模型,用于解释训练数据提供的特征与价格之间的关系。
在画布左侧的数据集和组件面板中,单击“组件”并搜索“线性回归”组件。
将“线性回归”组件拖到管道画布上。
在画布左侧的数据集和组件面板中,单击“组件”并搜索“训练模型”组件。
将“训练模型”组件拖到管道画布上。
将“线性回归”组件的输出连接到“训练模型”组件的左侧输入 。
将“拆分数据”组件的训练数据输出(左侧端口)连接到“训练模型”组件的右侧输入 。
重要
请确保“拆分数据”的左侧输出端口连接到“训练模型”。 左侧端口包含训练集。 右侧端口包含测试集。

选择“训练模型”组件。
单击画布右侧的“设置”下的箭头图标,以打开组件详细信息窗格。 或者,可以双击“训练模型”组件以打开详细信息窗格。
选择窗格右侧的“编辑列”。
在出现的“标签列”窗口中展开下拉菜单,然后选择“列名”。
在文本框中,输入“价格”以指定模型要预测的值。
重要
请确保确切地输入列名称。 不要将 price 的首字母大写。
管道应如下所示:

添加“评分模型”组件
使用 70% 的数据训练模型后,可以使用该模型为另外 30% 的数据评分,确定模型的运行情况。
在画布左侧的数据集和组件面板中,单击“组件”并搜索“评分模型”组件。
将“评分模型”组件拖到管道画布上。
将“训练模型”组件的输出连接到“评分模型”的左侧输入端口 。 将“拆分数据”组件的测试数据输出(右侧端口)连接到“评分模型”的右侧输入端口 。
添加“评估模型”组件
使用“评估模型”组件来评估模型为测试数据集评分的准确度。
在画布左侧的数据集和组件面板中,单击“组件”并搜索“评估模型”组件。
将“评估模型”组件拖到管道画布上。
将“评分模型”组件的输出连接到“评估模型”的左侧输入 。
最终的管道应如下所示:

提交管道
完成管道的所有设置后,可以提交管道作业来训练机器学习模型。 可以随时提交有效的管道作业(可用于查看在开发期间对管道所做的更改)。
在画布顶部选择“提交”。
在“设置管道作业”对话框中,选择“新建”。
注意
试验将相似的管道作业分组在一起。 如果多次运行管道,则可以为连续作业选择相同的试验。
对于“新试验名称”,输入“Tutorial-CarPrices” 。
选择“提交”。
你将在画布的左窗格中看到提交列表,页面右上角将弹出一条通知。 可以选择“作业详细信息”链接,转到作业详细信息页进行调试。

如果这是第一个作业,则管道可能需要长达 20 分钟的时间才能完成运行。 默认计算设置中的最小节点大小为 0,这意味着设计器必须在空闲后分配资源。 重复的管道作业花费的时间会更少,因为计算资源已分配。 此外,设计器还对每个组件使用缓存的结果,以便进一步提高效率。
查看评分标签
在作业详细信息页中,可以检查管道作业状态、结果和日志。

作业完成后,可以查看管道作业的结果。 首先查看回归模型生成的预测。
右键单击“评分模型”组件,选择“预览数据”>“评分数据集”以查看其输出。
在此处可以看到从测试数据预测的价格和实际价格。
评估模型
使用“评估模型”来确定已训练的模型处理测试数据集时的表现。
- 右键单击“评估模型”组件,选择“预览数据”>“评估结果”以查看其输出。
针对模型显示了以下统计信息:
- 平均绝对误差(MAE) :绝对误差的平均值。 误差是指预测值与实际值之间的差。
- 均方根误差(RMSE) :对测试数据集所做预测的平均误差的平方根。
- 相对绝对误差:相对于实际值与所有实际值平均值之间的绝对差异的绝对误差平均值。
- 相对平方误差:相对于实际值与所有实际值平均值之间的平方差异的平方误差平均值。
- 决定系数:也称为 R 平方值,这是一个统计指标,表示模型的数据拟合度。
每个误差统计值越小越好。 值越小,表示预测越接近实际值。 对于决定系数,其值越接近 1 (1.0),预测就越精确。
清理资源
若要继续学习本教程的第 2 部分部署模型,请跳过本部分。
重要
可以使用你创建的、用作其他 Azure 机器学习教程和操作指南文章的先决条件的资源。
删除所有内容
如果你不打算使用所创建的任何内容,请删除整个资源组,以免产生任何费用。
在 Azure 门户的窗口左侧选择“资源组”。
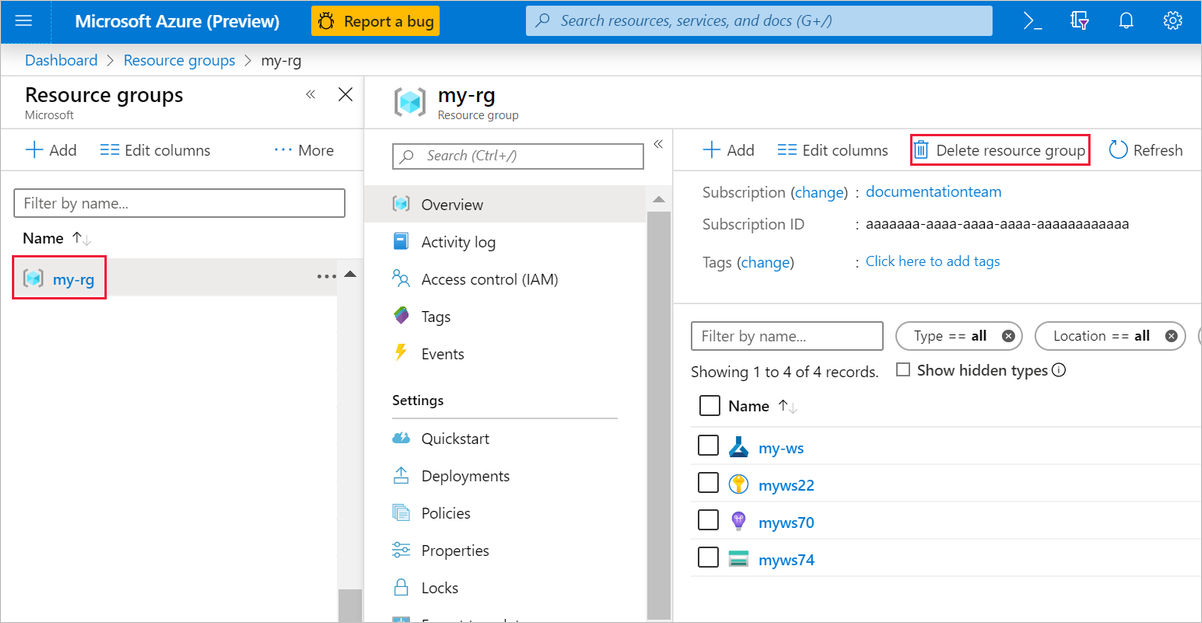
在列表中选择你创建的资源组。
选择“删除资源组”。
删除该资源组也会删除在设计器中创建的所有资源。
删除各项资产
在创建试验的设计器中删除各个资产,方法是将其选中,然后选择“删除”按钮。
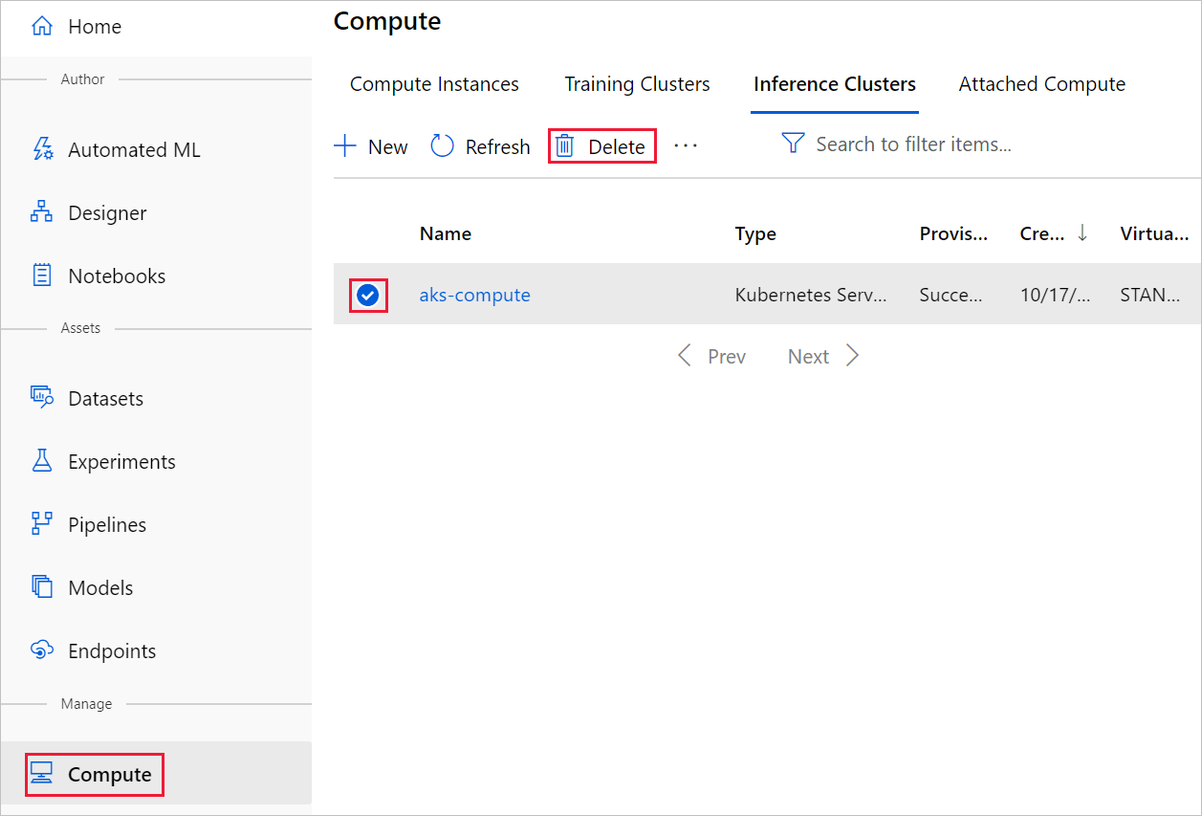
此处创建的计算目标在未使用时,会自动缩减到零个节点。 采取此操作可最大程度地减少费用。如果要删除计算目标,请执行以下步骤:
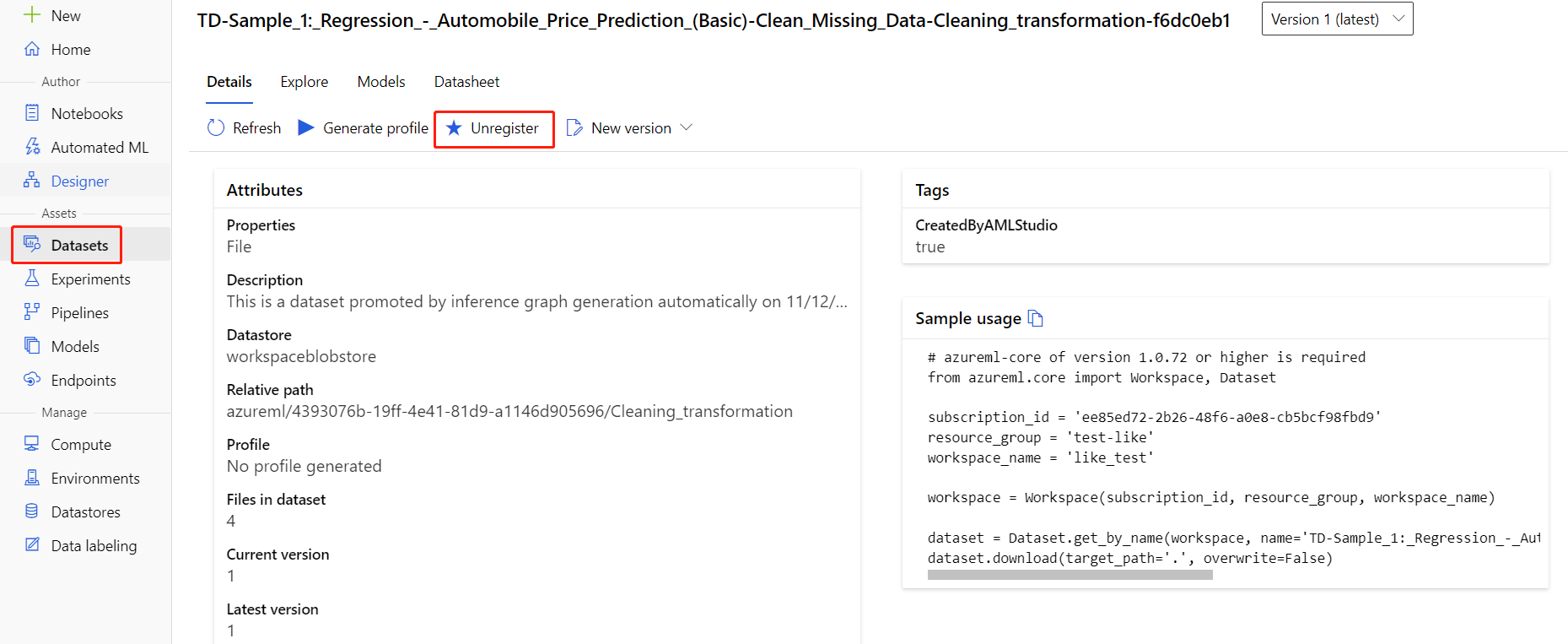
可以通过选择每个数据集并选择“注销”,从工作区中注销数据集。
若要删除数据集,请使用 Azure 门户或 Azure 存储资源管理器访问存储帐户,然后手动删除这些资产。
后续步骤
第二部分介绍如何将模型部署为实时终结点。