什么是灾难恢复?
灾难是单一的重大事件,其影响和持续时间超出了应用程序通过其设计中的高可用性部分进行缓解的能力。 灾难恢复 (DR) 是指从高影响事件(例如自然灾害或失败部署)中恢复,这会导致停机和数据丢失。 不管灾难的原因是什么,最好的补救措施就是一个定义全面且经过测试的 DR 计划,以及一个主动支持 DR 的应用程序设计。
恢复目标
完整的 DR 计划必须为应用程序实现的每个进程指定以下关键业务要求:
恢复点目标 (RPO) 是可接受数据丢失的最长持续时间。 RPO 以时间为单位来度量,而不是以数量为单位,例如“30 分钟的数据”或“4 小时的数据”。RPO 是关于限制和恢复数据丢失,而不是数据盗窃。
恢复时间目标 (RTO) 是可接受停机的最长持续时间,其中“停机”根据规范来定义。 例如,如果发生灾难时可接受的停机持续时间为 8 小时,则 RTO 为 8 小时。
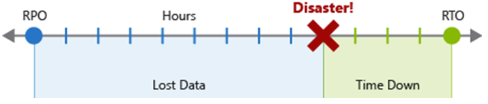
应用实施的每个主要进程或工作负载都应通过检查灾害场景风险和潜在恢复策略来具有单独的 RPO 和 RTO 值。 指定 RPO 和 RTO 的过程可有效地为应用程序创建 DR 要求,因为存在独特的业务问题(成本、影响、数据丢失等)。
设计灾难恢复
灾难恢复不是自动功能,但必须经过设计、构建和测试。 若要支持可靠的 DR 策略,必须从头开始生成一个考虑到 DR 的应用程序。 Azure 提供服务、功能和指南,帮助你在创建应用时支持灾难恢复。
数据恢复
发生灾难期间,主要有两种还原数据的方法:备份和复制。
备份可将数据还原到特定时间点。 借助备份功能,可以提供简单、安全且经济高效的解决方案来备份数据,并从 Azure 云恢复数据。 使用 Azure 备份创建长期只读数据快照,以备在恢复时使用。
数据复制以最大限度减少数据丢失为目的,在多个数据存储副本中创建实时或近乎实时的实时数据副本。 复制目标是使副本以尽可能低的延迟保持同步,同时保持应用程序的响应能力。 由于功能和性能方面的要求,大多数全功能数据库系统和其他数据存储产品与服务都包括某种类型的复制作为紧密集成式功能。 其中一个示例是异地冗余存储 (GRS)。
不同的复制设计针对数据一致性、性能和成本指定了不同的优先级。
主动复制需要同时对多个副本执行更新,这可以保证一致性,代价是吞吐量会降低。
被动复制在后台执行同步,这消除了复制给应用程序的性能带来的约束,但增大了 RPO。
主动-主动或多主数据库复制可同时使用多个副本,从而实现负载均衡,代价是数据一致性变得复杂。
主动-被动复制仅在故障转移期间保留副本供实时使用。
注意
大多数功能齐全的数据库系统和其他数据存储产品和服务因其功能和性能需求,都会包含某种形式的复制(例如异地冗余存储 (GRS))。
构建具有韧性的应用程序
此外,灾难场景通常会导致停机,不管原因是网络连接问题、数据中心服务中断,还是虚拟机 (VM) 或软件部署受损。 大多数情况下,应用程序恢复涉及故障转移到单独的工作部署。 因此,当发生大规模灾难时,可能需要在另一个 Azure 区域中恢复进程。 其他注意事项可能包括:恢复位置、复制的环境数量以及如何维护这些环境。
根据应用程序设计,可以使用多种不同的策略和 Azure 功能(例如 Azure Site Recovery)提高应用程序对灾难后进程恢复的支持。
特定于服务的灾难恢复功能
在 Azure 平台即服务 (PaaS) 产品/服务(例如 Azure 应用服务)上运行的大多数服务都提供支持 DR 的功能和指南。 在某些情况下,可以使用特定于服务的功能来支持快速恢复。 例如,Azure SQL Server 支持使用异地复制在另一个区域中快速还原服务。 Azure 应用服务提供备份和还原功能,文档中介绍了如何使用 Azure 流量管理器来支持将流量路由到次要区域。