Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
图像通常包含与搜索方案相关的有用信息。 Azure AI 搜索不会实时查询图像内容,但你可以在编制索引期间提取有关图像的信息,并使该内容可搜索。 若要在搜索索引中表示图像内容,可以使用以下方法:
将图像矢量化 ,以将视觉内容表示为可搜索矢量。
使用图像分析技能分析图像来生成图像的文本表示形式,例如蒲公英用于一张蒲公英的照片,或黄色。 还可以提取图像的元数据,例如其大小。
使用 OCR 从照片或图片中提取文本,例如停止符号中的“ 停止 ”一词。
还可以创建自定义 技能 来调用要提供的任何外部图像处理。
本文重点介绍图像分析和 OCR、用于外部处理的自定义技能、与嵌入式图像的处理,以及在原始图像上叠加可视化效果。 如果语言化或矢量化是首选方法,请参阅 多模式搜索 。
若要在技能组中处理图像内容,需要:
- 包含图像的源文件
- 为图像操作配置的搜索索引器
- 技能组,其中包含调用 OCR 或图像分析的内置或自定义技能的
- 一个搜索索引,其中包含用于接收分析的文本输出的字段,以及索引器中用于建立关联的输出字段映射
可以选择定义投影,以将经过图像分析的输出接受到知识存储中以用于数据挖掘方案。
设置源文件
图像处理是索引器驱动的,这意味着原始输入必须在支持的数据源中。
- 图像分析支持 JPEG、PNG、GIF 和 BMP
- OCR 支持 JPEG、PNG、BMP 和 TIF
图像可以是独立的二进制文件,也可以嵌入文档中(如 PDF、RTF 或 Microsoft 应用程序文件)。 可从给定文档中提取最多 1000 个图像。 如果在文档中有超过 1000 个图像,则提取前 1000 个,然后生成警告。
Azure Blob 存储是 Azure AI 搜索中最常用于图像处理的存储。 有三个主要任务与从 Blob 容器检索图像相关:
启用对容器中内容的访问权限。 如果使用包含密钥的完全访问连接字符串,密钥将授予你对内容的访问权限。 或者,可以使用托管标识进行身份验证,也可以作为受信任的服务进行连接。
创建“azureblob”类型的数据源,以便连接到用于存储文件的 Blob 容器。
查看服务层限制,确保源数据在索引器和扩充的最大大小和数量限制之下。
为图像处理配置索引器
设置源文件后,通过在索引器配置中设置 imageAction 参数来实现图像规范化。 图像规范化有助于使图像更统一,以进行下游处理。 图像规范化包括以下操作:
- 将大图像重设为最大高度和宽度,使其大小一致。
- 对于指定方向元数据的图像,可以调整图像旋转,使其适合垂直加载。
请注意,启用 imageAction(将此参数设置为非 none)将根据 Azure AI 搜索定价对图像提取收取额外费用。
元数据调整被捕获在为每个图像创建的复杂类型中。 不能选择退出图像规范化要求。 循环访问图像的技能(如 OCR 和图像分析)需要规范化图像。
创建或更新索引器以设置配置属性:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }将
dataToExtract设置为contentAndMetadata(必需)。验证
parsingMode是否设置为默认值(必需)。此参数确定在索引中创建的搜索文档的粒度。 默认模式设置为一对一对应,使一个 blob 生成一个搜索文档。 如果文档很大或者技能需要较小的文本区块,则你可以添加“文本拆分”技能,用于将文档划分为分页以进行处理。 但对于搜索场景,如果增强包括图像处理,则每个文档需要一个 Blob。
设置
imageAction以启用扩充树中的normalized_images节点(必需):使用
generateNormalizedImages会在文档破解过程中生成规范化图像的数组。generateNormalizedImagePerPage(仅适用于 PDF)可生成规范化图像数组,其中 PDF 中的每个页面都呈现到一个输出图像。 对于非 PDF 文件,此参数的行为与设置“generateNormalizedImages”相同。 但是,设置“generateNormalizedImagePerPage”可能会降低索引操作的性能(这是设计使然,尤其是对于大型文档),因为必须生成多个图像。
(可选)调整生成的规范化图像的宽度或高度:
normalizedImageMaxWidth(以像素为单位)。 默认值为 2000。 最大值为 10000。normalizedImageMaxHeight(以像素为单位)。 默认值为 2000。 最大值为 10000。
将规范化图像的最大宽度和高度默认设置为 2000 像素是考虑到 OCR 技术所能够支持的最大大小以及图像分析技术。 OCR 技能支持非英语语言的最大宽度和高度为 4200,支持英语语言的最大宽度和高度为 10000。 如果增加最大限制,则根据技能组定义和文档语言,对较大的图像进行处理可能会失败。
(可选)如果工作负荷面向特定文件类型,则设置文件类型条件。 Blob 索引器配置包括文件包含和排除设置。 可以筛选出不需要的文件。
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
关于标准化图像
将 imageAction 设置为除“none”以外的值后,新的 字段包含一个图像数组normalized_images。 每个图像是具有以下成员的复杂类型:
| 图像成员 | 说明 |
|---|---|
| 数据 | JPEG 格式的图像经过规范化后得到的 BASE64 编码字符串。 |
| 宽度 | 规范化图像的宽度(以像素为单位)。 |
| 高度 | 规范化图像的高度(以像素为单位)。 |
| 原始宽度 | 图像在规范化之前的原始宽度。 |
| 原始高度 | 图像在规范化之前的原始高度。 |
| 相对于原始位置的旋转 | 在创建规范化图像过程中进行的逆时针旋转(以度为单位)。 值的范围为 0 度到 360 度。 此步骤从图像读取由照相机或扫描仪生成的元数据。 通常为 90 度的倍数。 |
| 内容偏移量 | 字符在内容字段中的偏移量,即从中提取图像的位置。 此字段仅适用于包含嵌入图像的文件。 从 PDF 文档中提取的图像的 contentOffset 始终位于从文档中提取的页面上的文本末尾。 这意味着图像会在该页面上的所有文本之后出现,而不管图像在页面的初始位置。 |
| 页码 | 如果图像是从 PDF 提取或呈现的,则此字段包含从中提取或呈现图像的 PDF 中的页码(从 1 开始)。 如果图像不是来自 PDF,则此字段为 0。 |
| boundingPolygon | 如果图像是从 PDF 中提取或呈现的,则此字段包含将图像括在页面上的边界多边形的坐标。 多边形表示为一个嵌套的点数组,其中每个点都有标准化为页面维度的 x 和 y 坐标。 这仅适用于使用 imageAction: generateNormalizedImages 提取的图像。 |
normalized_images 的示例值:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2,
"boundingPolygon": "[[{\"x\":0.0,\"y\":0.0},{\"x\":500.0,\"y\":0.0},{\"x\":0.0,\"y\":300.0},{\"x\":500.0,\"y\":300.0}]]"
}
]
边界多边形数据表示为一个字符串,其中包含双重嵌套的 JSON 编码多边形数组。 每个多边形都是一个点数组,其中每个点都有 x 和 y 坐标。 坐标相对于 PDF 页面,其原点 (0, 0) 位于左上角。
目前,使用 imageAction: generateNormalizedImages 提取出的图像始终只会生成一个多边形,但仍保留双重嵌套结构,以便与支持多个多边形的技能保持一致,例如 Azure 内容理解技能。
定义用于图像处理的技能组
此部分通过提供对技能输入、输出和模式的背景来补充技能参考文章,因为它们与图像处理相关。
创建或更新技能组以添加技能。
从 Azure 门户添加 OCR 和图像分析模板,或从 技能参考 文档复制定义。 请将它们插入到技能集定义的技能数组中。
如有必要,请在技能集中 包括 Azure AI 服务资源密钥 。 Azure AI 搜索会调用可计费的 Azure AI 服务资源,以进行 OCR 和图像分析,这适用于超出每个索引器每天 20 个的免费限制的事务。 除非使用无键连接(预览版),否则 Azure AI 服务资源必须与搜索服务位于同一区域。
如果原始图像嵌入在 PDF 或应用程序文件(如 PPTX 或 DOCX)中,若要图像输出和文本输出在一起,需要添加文本合并技能。 本文将进一步讨论如何使用嵌入图像。
创建技能组的基本框架并配置 Azure AI 服务后,可以专注于每个单独的图像技能,定义输入和源上下文,并将输出映射到索引或知识存储中的字段。
注意
有关将图像处理与下游自然语言处理相结合的示例技能组,请参阅 REST 教程:使用 REST 和 AI 从 Azure Blob 生成可搜索内容。 它演示如何将技能映像输出馈送到实体识别和关键短语提取中。
图像处理的输入
如前所述,图像在文档破解期间进行提取,然后作为预备步骤进行规范化。 规范化图像是任何图像处理功能的输入数据,始终通过以下两种方式之一在扩展文档树中进行表示:
/document/normalized_images/*适用于整体被处理的文档。/document/normalized_images/*/pages适用于按区块(页)进行处理的文档。
无论是同时使用 OCR 和图像分析,输入几乎具有相同的结构。
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
将输出映射到搜索字段
在技能组中,图像分析和 OCR 技能输出始终为文本。 输出文本表示为内部扩充文档树中的节点,每个节点必须映射到搜索索引中的字段或知识存储中的投影,才能使内容在应用中可用。
在技能组中,查看每个技能的
outputs部分,以确定哪些节点存在于扩充文档中:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }创建或更新搜索索引以添加字段来接受技能输出。
在以下字段集合示例中,content 是 blob 内容。 “Metadata_storage_name”包含文件的名称(将
retrievable设置为“是”)。 “Metadata_storage_path”是 blob 的唯一路径,是默认文档键。 Merged_content 是文本合并工具的输出,尤其在嵌入图像时很有用。“Text”和“layoutText”是 OCR 技能输出,必须是字符串集合才能捕获整个文档的所有 OCR 生成的输出。
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],更新索引器以将技能组输出(扩充树中的节点)映射到索引字段。
扩充文档是内部文档。 若要在扩充文档树中外部化节点,设置一个输出字段映射,指定哪个索引字段接收节点内容。 应用通过索引字段访问增强数据。 以下示例显示搜索索引中映射到“text”字段的扩充文档中的“text”节点(OCR 输出)。
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]运行索引器以调用源文档检索、图像处理和索引。
验证结果
对索引运行查询以检查图像处理的结果。 使用搜索资源管理器作为搜索客户端或发送 HTTP 请求的任何工具。 下面的查询选择包含图像处理输出的字段。
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR 识别图像文件中的文本。 这意味着,如果源文档为纯文本或纯图像,则 OCR 字段(“text”和“layoutText”)为空。 同样,对于严格为文本的源文档,图像分析字段(“imageCaption”和“imageTags”)为空。 如果图像处理输入为空,索引器执行发出警告。 当节点在扩充文档中未填充时,预计会出现此类警告。 请记住,如果要独立使用内容类型,则通过 blob 索引可包含或排除文件类型。 可以使用这些设置来减少索引器运行期间的噪音。
用于检查结果的备用查询可能包含“content”和“merged_content”字段。 请注意,这些字段包含任何 Blob 文件的内容,即使未执行图像处理也是如此。
关于技能输出
技能输出包括 text (OCR)、layoutText (OCR)、merged_content、captions(图像分析)、tags(图像分析):
text存储 OCR 生成的输出。 此节点应映射到Collection(Edm.String)类型的字段。 对于包含多个图像的文档,每个搜索文档都有一个text字段,其中包含以逗号分隔的字符串。 下图显示了三个文档的 OCR 输出。 第一个是包含不带图像的文件的文档。 第二个文档(图像文件)包含一个单词“Microsoft”。 第三个是包含多个图像的文档,其中一些图像没有任何文本 ("",)。"value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Azure AI services and Azure Search" ] } ]layoutText存储 OCR 生成的有关页面上文本位置的信息,该位置以规范化图像的边框和坐标来描述。 此节点应映射到Collection(Edm.String)类型的字段。 每个搜索文档中有一个layoutText字段,其中包含以逗号分隔的字符串。merged_content存储文本合并技能的输出,它应该是一个Edm.String类型的大型字段,其中包含源文档中的原始文本,并以嵌入的text代替图像。 如果文件是纯文本,则 OCR 和图像分析不执行任何操作,并且merged_content与content(包含 blob 内容的 blob 属性)相同。imageCaption捕获图像的描述,包括单个标签和较长的文本说明。imageTags将有关图像的标记作为关键词集合进行存储,源文档中的所有图像共享一个集合。
以下屏幕截图显示了包含文本和嵌入图像的 PDF。 文档破解检测到三个嵌入的图像:海鸥群,地图,鹰。 示例中的其他文本 (包括标题、标题和正文文本) 提取为文本,并从图像处理中排除。
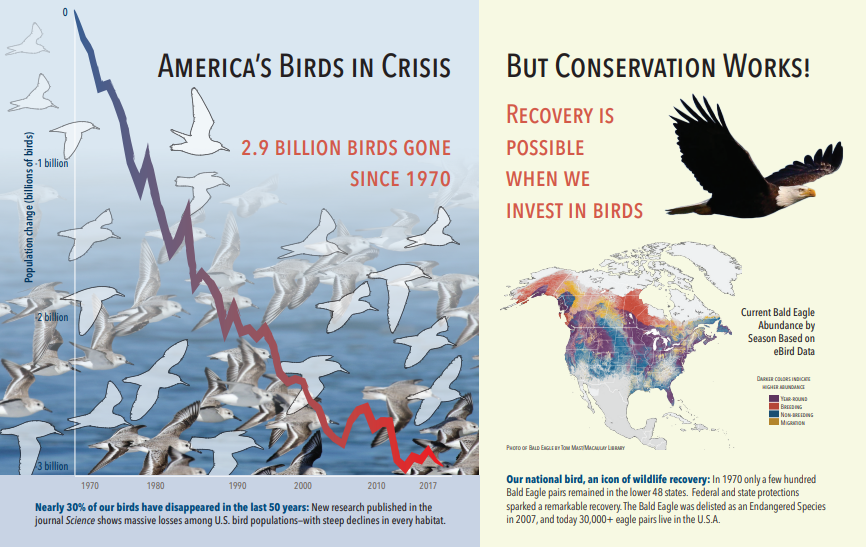
以下 JSON 中演示了图像分析输出(搜索结果)。 使用技能定义可以指定感兴趣的视觉特征。 在此示例中,生成了标记和说明,但有更多输出可供选择。
imageCaption输出是描述数组,每个图像一个,由tags表示,由描述图像的单个单词和更长的短语组成。 请注意,包含“一群海鸥在水里游泳”或“一只鸟的特写”的标签。imageTags输出是单一标记数组,其中的标记按创建顺序列出。 请注意,标记重复。 未进行聚合或分组。
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
场景:PDF 中的嵌入图像
要处理的图像嵌入到其他文件(如 PDF 或 DOCX)中时,扩充管道仅提取图像,然后将其传递到 OCR 或图像分析进行处理。 图像提取在文档解析阶段进行,图像分离后,将继续保持独立状态,除非显式将处理后的结果合并回源文本。
文本合并用于将图像处理输出重新放入文档中。 尽管文本合并不是硬性要求,但经常会调用它,以便可将图像输出(OCR 文本、OCR layoutText、图像标记、图像标题)重新引入到文档中。 根据技能水平,图像输出会将嵌入的二进制图像在原地替换为等效的文本形式。 图像分析输出可以在图像中的指定位置合并。 OCR 输出始终显示在每页的末尾。
以下工作流概述了图像提取、分析、合并的过程,以及如何扩展管道以将图像处理后的输出推送到实体识别或文本翻译等其他基于文本的技能中。
连接到数据源后,索引器将加载并破解源文档,提取图像和文本,并将每种内容类型排队以进行处理。 将创建一个仅包含根节点(文档)的扩展文档。
队列中的图像被规范化,并作为document/normalized_images节点嵌入到增强的文档中。
图像扩充使用
"/document/normalized_images"作为输入来执行。图像输出将传递到扩充文档树中,每个输出作为单独的节点。 输出因能力而异(OCR 的文本和 OCR 表格文本,图像分析的标记和标题)。
如你希望搜索文档同时包含文本和图像来源文本,建议运行文本合并,将这些图像的文本表示形式与从文件中提取的原始文本合并。 文本区块合并为一个大型字符串,其中文本首先插入字符串中,然后是 OCR 文本输出或图像标记和标题。
文本合并结果现在是权威文本,供进行文本处理的任何下游技能进行分析。 例如,如果你的专业技能包含 OCR 和实体识别,则实体识别的输入应是
"document/merged_text"(文本合并技能输出的 targetName)。执行所有技能后,丰富的文档即已完成。 在最后一步中,索引器引用输出字段映射,以将扩充的内容发送到搜索索引中的各个字段。
以下示例技能组创建一个 merged_text 字段,其中包含文档的原始文本,并以嵌入的经过 OCR 处理的文本代替嵌入的图像。 该技能组还包含使用 merged_text 作为输入的实体识别技能。
请求正文语法
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
有了 merged_text 字段以后,可将其映射为索引器定义中的可搜索字段。 文件的所有内容(包括图像的文本)将均可搜索。
场景:可视化边界框
另一个常见场景是将搜索结果布局信息可视化。 例如,您可能需要在搜索结果中突出显示图像中找到的一段文本的位置。
由于 OCR 步骤对规范化图像执行,因此布局坐标位于规范化图像空间中,但如果需要显示原始图像,则将布局中的坐标点转换为原始图像坐标系统。
以下算法演示了模式:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
场景:自定义图像技能
还可以将图像传入自定义技能,以及从自定义技能返回图像。 技能组对要传入到自定义技能的图像进行 base64 编码。 若要在自定义技能内使用图像,请将 "/document/normalized_images/*/data" 设置为自定义技能的输入。 在自定义技能代码中,先对字符串进行 base64 解码,然后再将其转换为图像。 若要将图像返回到技能组,请先对图像进行 base64 编码,然后再将图像返回到技能组。
图像作为具有以下属性的对象返回。
{
"$type": "file",
"data": "base64String"
}
Azure 搜索 Python 示例存储库包含一个使用 Python 实现的完整示例,该示例包含一个可扩充图像的自定义技能。
将图像传递到自定义技能
对于需要自定义技能来处理图像的情况,可以将图像传递到自定义技能,并使其返回文本或图像。 以下技能组来自一个示例。
以下技能组接受(在文档破解时获取的)规范化图像,并输出图像的切片。
示例技能集
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
自定义技能示例
自定义技能本身在技能组的外部。 在本例中,Python 代码首先遍历自定义技能格式的一批请求记录,然后将 base64 编码的字符串转换为图像。
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
同样,若要返回图像,请在具有$type属性,其值为file的JSON对象中返回一个base64编码字符串。
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}