Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
多租户应用程序是向无法查看或共享任何其他租户数据的任意数量的租户提供相同的服务和功能。 本文讨论使用 Azure AI 搜索生成的多租户应用程序的租户隔离策略。
Azure AI 搜索概念
作为一种搜索即服务解决方案, Azure AI 搜索 允许开发人员向应用程序添加丰富的搜索体验,而无需管理任何基础结构或成为信息检索方面的专家。 数据将上传到服务,然后存储在云中。 然后,可以使用对 Azure AI 搜索 API 的简单请求来修改和搜索数据。
搜索服务、索引、字段和文档
在讨论设计模式之前,请务必了解一些基本概念。
使用 Azure AI 搜索时,需要订阅搜索服务。 将数据上传到 Azure AI 搜索时,数据存储在搜索服务中的 索引 中。 单个服务中可以有多个索引。 若要使用熟悉的数据库概念,可以将搜索服务比化为数据库,而服务中的索引可以比化为数据库中的表。
搜索服务中的每个索引都有自己的架构,由许多可自定义 字段定义。 数据以单个 文档的形式添加到 Azure AI 搜索索引。 必须将每个文档上传到特定索引,并且必须适合该索引的架构。 使用 Azure AI 搜索搜索数据时,针对特定索引发出全文搜索查询。 若要将这些概念与数据库的概念进行比较,可以将字段比作表中的列,文档可以比作行。
可伸缩性
标准 定价层 中的任何 Azure AI 搜索服务都可以在两个维度中缩放:存储和可用性。
- 可以添加分区以增加搜索服务的存储。
- 可以将副本添加到服务,以提高搜索服务可以处理的请求吞吐量。
添加和删除分区和副本将允许搜索服务的容量随应用程序所需的数据和流量一起增长。 为了使搜索服务实现读取 SLA,它需要两个副本。 为了使服务实现读写 SLA,它需要三个副本。
Azure AI 搜索中的服务和索引限制
Azure AI 搜索中有几个不同的 定价层 ,每个层都有不同的 限制和配额。 其中一些限制在服务级别,一些限制在索引级别,一些限制在分区级别。
S3 高密度
在 Azure AI 搜索的 S3 定价层中,可以选择专为多租户方案设计的高密度(HD)模式。 在许多情况下,有必要在单个服务下支持大量较小的租户,以实现简单性和成本效益的优势。
S3 HD 允许将许多小型索引整合到单个搜索服务的管理下,通过用分区方式的索引横向扩展能力交换来实现更多索引在单个服务中的托管能力。
S3 服务旨在托管固定数量的索引(最大 200),并允许每个索引在向服务中添加新分区时水平缩放大小。 将分区添加到 S3 HD 服务会增加服务可以承载的最大索引数。 单个 S3HD 索引的理想最大大小约为 50 - 80 GB,尽管系统施加的每个索引没有硬大小限制。
多租户应用程序的注意事项
多租户应用程序必须在租户之间有效地分配资源,同时在各种租户之间保留某种级别的隐私。 为此类应用程序设计体系结构时,有几个注意事项:
租户隔离: 应用程序开发人员需要采取适当的措施,以确保没有租户未经授权或不需要访问其他租户的数据。 在数据隐私之外,租户隔离策略还需要有效管理共享资源,并防止来自干扰邻居的影响。
云资源成本: 与任何其他应用程序一样,作为多租户应用程序的组件,软件解决方案必须保持成本竞争力。
易于操作: 开发多租户体系结构时,应用程序的操作和复杂性受到影响,这是一个重要的考虑因素。 Azure AI 搜索具有 99.9% SLA。
全球足迹: 多租户应用程序通常需要为分布在全球的租户提供服务。
可扩展性: 应用程序开发人员需要考虑如何在保持应用程序复杂性较低的同时,通过设计使应用程序能扩展以适应租户数量增加以及租户数据和工作负荷的大小变化。
Azure AI 搜索提供了一些边界,可用于隔离租户的数据和工作负荷。
使用 Azure 人工智能搜索构建多租户模型
对于多租户方案,应用程序开发人员使用一个或多个搜索服务,并在服务、索引或两者之间划分其租户。 建模多租户方案时,Azure AI 搜索有一些常见模式:
每个租户一个索引: 每个租户在与其他租户共享的搜索服务中都有自己的索引。
每个租户一个服务: 每个租户都有自己的专用 Azure AI 搜索服务,提供最高级别的数据和工作负荷分离。
两者的组合:较大的、更活跃的租户分配专用服务,而较小的租户则在共享服务中分配单个索引。
模型 1:每个租户一个索引
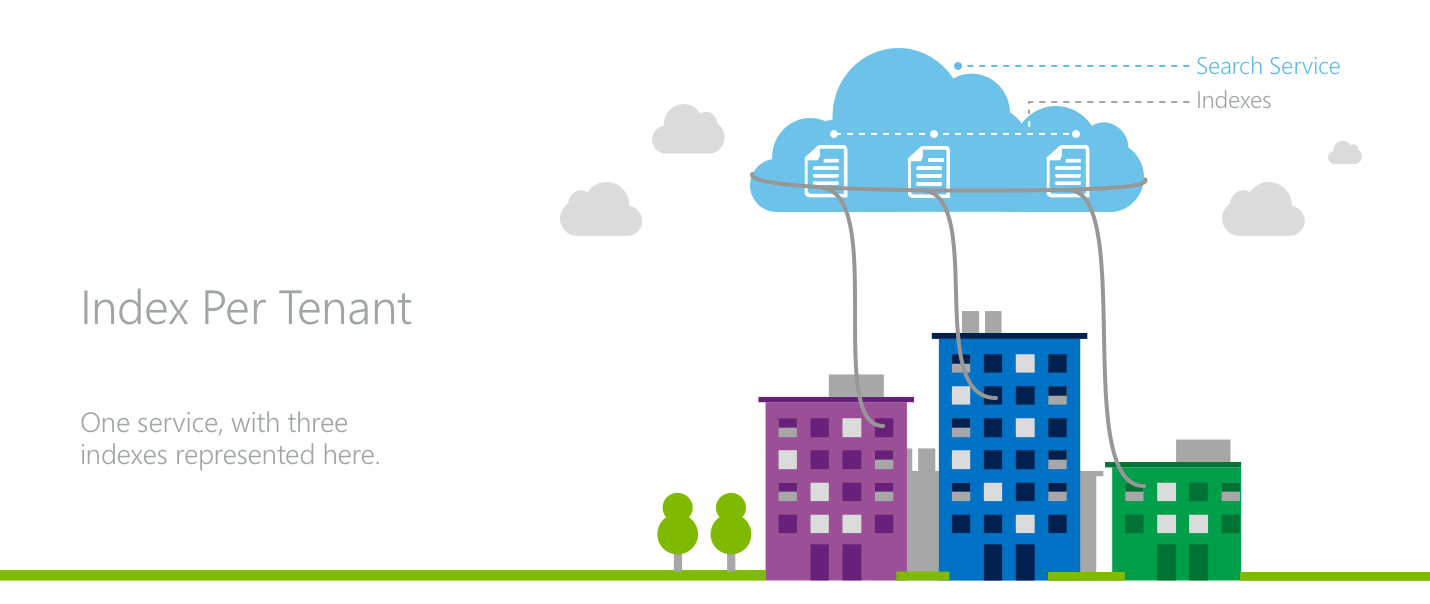
在每租户索引模型中,多个租户占用单个 Azure AI 搜索服务,其中每个租户都有自己的索引。
此方法之所以有效,是因为所有搜索请求和文档操作都在 Azure AI 搜索中以索引级别执行。 在应用层中,需要有意识地将不同租户的流量定向到合适的索引,同时在所有租户中管理服务层级的资源。
租户索引模型的一个关键属性是应用程序开发人员能够在应用程序的多个租户间合理超配搜索服务的容量。 如果租户的工作负荷分布不均衡,搜索服务可以在索引中合理分布租户的最佳组合,以容纳大量高度活跃且资源密集型的租户,同时运作那些不太活跃的租户组成的长尾群体。 折衷选择是模型无法处理每个租户同时高度活跃的情况。
按租户索引模型为可变成本模式提供了基础。在这种模式下,整个 Azure AI 搜索服务被预先采购,然后租户逐步加入。 这允许为试用和试用订阅指定未使用的容量。
对于具有全球影响力的应用程序,基于每个租户的索引模型可能不是最有效的。 如果应用程序的租户分布在全球,则每个区域都需要单独的服务,从而复制每个区域的成本。
Azure AI 搜索允许扩展单个索引和索引总数的增长。 如果选择适当的定价层,当服务中的单个索引在存储或流量方面增长过大时,可以将分区和副本添加到整个搜索服务。
如果单个服务的索引总数增长过大,则必须预配另一个服务以适应新租户。 如果在添加新服务时必须在搜索服务之间移动索引,则必须将索引中的数据从一个索引手动复制到另一个索引,因为 Azure AI 搜索不允许移动索引。
模型 2:每个租户一个服务
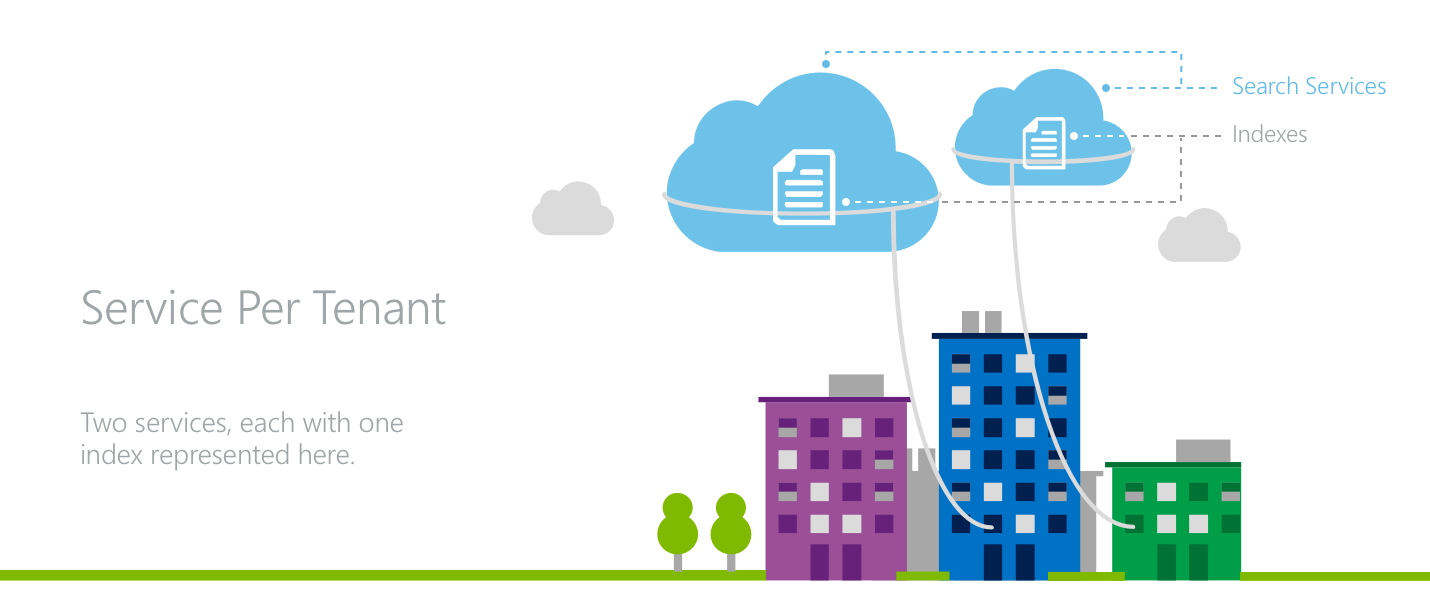
在服务分配给每个租户的体系结构中,每个租户都有自己的搜索服务。
在此模型中,应用程序可实现其租户的最大隔离级别。 每个服务都有用于处理搜索请求的专用存储和吞吐量。 每个租户都有 API 密钥的单独所有权。
对于应用程序而言,如果每个租户需要大量资源或工作负载在不同租户之间变化不大,“服务-每个租户”模型是一个有效的选择,因为资源不会在多个租户的工作负载之间共享。
租户服务模型还提供可预测的固定成本的好处。 在租户填充整个搜索服务之前,不会进行前期投资,但每个租户的成本高于每个租户的索引模型。
每个租户的服务模型是具有全球影响力的应用程序的有效选择。 使用地理分布的租户,可以轻松地为每个租户在其相应的区域提供服务。
当租户的需求超出服务能力时,扩展此模式会遇到挑战。 Azure AI 搜索目前不支持升级搜索服务的定价层,因此所有数据都必须手动复制到新服务。
模型 3:混合
多租户建模的另一种模式是结合每个租户的索引策略和每个租户的服务策略。
通过混合这两种模式,应用程序的最大租户可以占用独立服务,而不太活跃的较小租户群体可以在共享服务中占用索引。 此模型可确保最大的租户始终从服务获得高性能,同时帮助保护较小的租户免受任何干扰邻居的影响。
但是,实现此策略依赖于预见性来预测哪些租户需要专用服务,而不是共享服务中的索引。 应用程序复杂性随着管理这两个多租户模型的需求而增加。
实现更精细的粒度
在 Azure AI 搜索中为多租户方案建模的上述设计模式假设一个统一的范围,其中每个租户都是应用程序的完整实例。 但是,应用程序有时可以处理许多较小的范围。
如果每个租户的服务模型和每个租户的索引模型的范围不够具体,可以对索引进行重新建模,以实现更细化的粒度。
若要使单个索引对不同的客户端终结点的行为不同,可以将字段添加到索引中,该索引为每个可能的客户端指定一个特定值。 每次客户端调用 Azure AI 搜索来查询或修改索引时,客户端应用程序中的代码都会使用 Azure AI 搜索的 筛选器 功能为该字段指定适当的值。
此方法可用于实现单独的用户帐户、单独的权限级别甚至完全独立的应用程序的功能。
注释
使用上述方法配置单个索引来为多个租户提供服务会影响搜索结果的相关性。 搜索相关性分数是在索引级别范围(而不是租户级范围)计算的,因此所有租户的数据都合并到相关性分数的基础统计信息(如术语频率)中。
后续步骤
对于许多应用程序,Azure AI 搜索是一个极具吸引力的选择。 评估多租户应用程序的各种设计模式时,请考虑 各种定价层 和相应的 服务限制 ,以最好地定制 Azure AI 搜索以适应各种规模的应用程序工作负载和体系结构。