Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍搜索结果组合以及如何调整全文搜索结果以适应你的方案。 搜索结果在查询响应中返回。 响应的形状由查询本身中的参数决定。 这些参数包括:
- 在索引中找到的匹配项数 (
count) - 响应中返回的匹配项数(默认为 50 个,可通过
top配置)或按每页(skip和top) - 每个结果的搜索分数,用于排名 (
@search.score) - 搜索结果中包含的字段 (
select) - 排序逻辑 (
orderby) - 在结果中突出显示关键词,并在正文中对整个或部分关键词进行匹配。
- 语义排序器中的可选元素(在顶部的
answers,每个匹配项的captions)
搜索结果可以包含顶级字段,但大多数响应都包含数组中的匹配文档。
用于定义查询响应的客户端和 API
可以使用以下客户端配置查询响应:
- Azure 门户中的Search Explorer,通过 JSON 视图来指定任何受支持的参数。
- 文档 - POST (REST API)
- SearchClient.Search 方法(适用于 .NET 的 Azure SDK)
- SearchClient.Search 方法(适用于 Python 的 Azure SDK)
- SearchClient.Search 方法(适用于 JavaScript 的 Azure)
- SearchClient.Search 方法(适用于 Java 的 Azure)
结果的构成
结果大多以表格呈现,由所有 retrievable 字段组成,或只限于 select 参数中指定的字段。 行是匹配的文档,通常按相关性顺序排名,除非查询逻辑排除了相关性排名。
可以选择在搜索结果中包含哪些字段。 尽管搜索文档可能包含大量字段,但通常只需少量的几个字段就能表示结果中的每个文档。 在查询请求中,追加 select=<field list> 以指定应在响应中显示哪些 retrievable 字段。
选择能够在文档之间提供对比和区分的字段,并提供足够的信息以吸引用户点击响应。 在电子商务网站上,这些字段可能是产品名称、说明、品牌、颜色、尺寸、价格和评级。 对于 hotels-sample 索引,它可能是以下示例中的“select”字段:
POST /indexes/hotels-sample/docs/search?api-version=2026-04-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
应对意外结果的建议
有时,查询输出与预期结果不符。 例如,你可能发现某些结果似乎是重复的,或者某个本应靠前显示的结果却出现在结果列表中的较后位置。 如果查询结果不符合预期,可以尝试对查询进行以下修改,然后查看结果是否有所改善:
将
searchMode=any(默认)更改为searchMode=all,以便要求符合所有条件的匹配,而不是符合任意条件的匹配。 在查询包含布尔运算符时更应如此。使用不同的词法分析器或自定义分析器进行试验,看它是否改变了查询结果。 默认分析器会分解包含连字符的单词并将单词缩减为词根形式,这通常可提高查询响应的稳定性。 但是,如果需要保留连字符,或者字符串中包含特殊字符,则你可能需要配置自定义分析器,以确保索引包含正确格式的标记。 有关详细信息,请参阅部分字词搜索和包含特殊字符(连接符、通配符、正则表达式、模式)的模式。
匹配项计数
count 参数返回索引中与查询匹配的文档数。 若要返回计数,请将 count=true 添加到查询请求。 搜索服务没有规定最大值。 根据您的查询和文档内容,计数可能会达到索引中所有文档的数量。
当索引稳定时,计数是准确的。 如果系统正在主动添加、更新或删除文档,则计数将为近似值,不会对任何未完全编制索引的文档进行计数。
计数结果不会受到搜索服务上的日常维护或其他工作负载的影响。 但是,如果有多个分区和单个副本,则在分区重启时,可能会遇到文档计数的短期波动(几分钟)。
提示
若要检查索引操作,可以通过在空搜索 count=true 查询中添加 search=* 来确认索引是否包含预期数量的文档。 结果是您索引中的文档总数。
在测试查询语法时,通过 count=true 可以快速判断修改返回的结果是更多还是更少,这可能是有用的反馈。
响应中的结果数
Azure AI 搜索使用服务器端分页来防止查询一次检索太多文档。 确定响应中结果数的查询参数是 top 和 skip。
top 指页面中的搜索结果数。
skip 是 top 的间隔,它告诉搜索引擎在获取下一个集之前要跳过的结果数。
默认页大小为 50,最大页大小为 1000。 如果指定的值大于 1,000,并且在索引中找到的结果超过 1,000 个,则只返回前 1,000 个结果。 如果匹配项数超过页面大小,则响应将包含检索下一页结果的信息。 例如:
"@odata.nextLink": "https://contoso-search-chinaeast2.search.azure.cn/indexes/hotels-sample/docs/search?api-version=2025-09-01"
排名靠前的匹配项由搜索分数决定,假设查询是全文搜索或语义。 否则,最佳匹配项在完全匹配查询中以任意顺序显示(其中 @search.score=1.0 表示任意排名)。
设置为 top 以替代默认值 50。 在较新的预览 API 中,如果使用混合查询,则可以指定 maxTextRecallSize 以返回最多 10,000 个文档。
要控制结果集中返回的所有文档的分页,可以同时使用 top 和 skip。 此查询返回第一组 15 个匹配文档,以及匹配项总计数。
POST https://contoso-search-chinaeast2.search.azure.cn/indexes/hotels-sample/docs/search?api-version=2025-09-01
{
"search": "room with a view",
"count": true,
"top": 15,
"skip": 0
}
此查询返回第二组,跳过前 15 个以获取接下来 15 个(16 到 30):
POST https://contoso-search-chinaeast2.search.azure.cn/indexes/hotels-sample/docs/search?api-version=2025-09-01
{
"search": "room with a view",
"count": true,
"top": 15,
"skip": 15
}
如果基础索引会发生变化,则无法保证分页查询的结果稳定。 分页会更改每个页面的 skip 值,但每个查询都是独立运行的,并针对查询时索引中的当前数据视图进行操作。换言之,不会有如通用数据库中常见的结果缓存或快照。
以下是一个示例,展示了您可能如何获取重复项。 假设某个索引包含四个文档:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
现在假设你希望每次返回按评级排序的两个结果。 你将执行此查询来获取第一页结果:$top=2&$skip=0&$orderby=rating desc,将生成以下结果:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
在服务上,假设在两次查询调用之间将第五个文档添加到索引中:{ "id": "5", "rating": 4 }。 片刻之后,你执行查询来提取第二页:$top=2&$skip=2&$orderby=rating desc,将获得以下结果:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
请注意,文档 2 被获取了两次。 这是因为,新文档 5 的评级值较大,因此它排在文档 2 的前面,并出现在第一页中。 尽管这种行为可能让人意外,但它却是搜索引擎的典型行为。
分页浏览大量结果
分页的替代方法是使用排序顺序和范围筛选器作为 skip 的变通方法。
在此解决方法中,排序和筛选将应用于文档 ID 字段,或每个文档独有的其他字段。 唯一字段必须在搜索索引中具有 filterable 属性和 sortable 属性。
发出查询以返回已排序结果的完整页面。
POST /indexes/good-books/docs/search?api-version=2026-04-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }选择搜索查询返回的最后一个结果。 此处仅显示具有一个“ID”值的示例结果。
{ "id": "50" }在范围查询中使用“ID”值来提取下一页结果。 此“ID”字段应具有唯一值,否则分页可能包含重复结果。
POST /indexes/good-books/docs/search?api-version=2026-04-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }在查询返回零结果时,分页结束。
注意
仅当字段首次添加到索引时,才能启用“filterable”和“sortable”特性,不能在现有字段上启用它们。
对结果排序
在全文搜索查询中,结果可按以下依据排名:
- 搜索评分
- 语义重排器分数
-
sortable字段的排序顺序
还可以通过添加评分配置文件来强化在特定字段中找到的任何匹配项。
按搜索评分排序
对于全文搜索查询,结果使用 BM25 算法自动按搜索分数进行排名,根据字词频率、文档长度和平均文档长度计算。
“@search.score”范围要么没有限制,要么在旧版服务中是 0 到 1.00(直到但不包括 1.00)。
对于任一算法,“@search.score”都等于 1.00 表示未评分或未排序的结果集,其中 1.0 评分在所有结果中都是一致的。 如果查询形式是模糊搜索、通配符或正则表达式查询,或者是空搜索 (search=*),则会出现未评分的结果。 如果需要对未评分的结果进行排名,请考虑使用 orderby 表达式实现此目的。
按语义重排器排序
如果使用语义排序器,则“@search.rerankerScore”将确定结果的排序顺序。
“@search.rerankerScore”范围为 1 到 4.00,分数越高表示语义匹配越强。
使用 orderby 排序
如果一致的排序是一项应用程序要求,则可以在字段上定义 orderby 表达式。 只有在编制索引时设置为“可排序”的字段才可用于对结果排序。
orderby 中常用的字段包括评级、日期和位置。 按位置筛选需要筛选表达式调用 函数并指定字段名称geo.distance()。
数字字段(Edm.Double、Edm.Int32、Edm.Int64)按数字顺序排序(例如,1、2、10、11、20)。
字符串字段(Edm.String、Edm.ComplexType 子字段)按 ASCII 排序顺序排序
字符串字段中的数字内容按字母顺序排序 (1, 10, 11, 2, 20)。
大写字母开头的字符串在排序时会排在小写字母开头的字符串之前 (APPLE, Apple, BANANA, Banana, apple, banana)。 要更改此行为,可以分配文本规范化程序以在排序之前对文本进行预处理。 对某一字段使用小写分词器对排序行为没有影响,因为 Azure AI 搜索对字段的非分析副本进行排序。
以变音符号开头的字符串在排序时排列在最后 (Äpfel, Öffnen, Üben)
使用评分配置文件提升相关性
提高排序一致性的另一种方法是使用自定义评分配置文件。 使用评分配置文件可以让你更好地控制搜索结果中各项的排名,并能够提升在特定字段中找到的匹配项。 这一附加的评分逻辑有助于覆盖副本之间的细微差异,因为每个文档的搜索评分会在更大程度上拉开差距。 我们建议对此方法使用排名算法。
突出显示
命中高亮显示是指在结果中将匹配词语以文本格式(例如粗体或黄色高亮)进行标记,使用户能够轻松识别匹配项。 突出显示适合用于较长的内容字段(如“说明”字段),因为在这些字段中,匹配内容不是立即就能看到。
请注意,突出显示将应用于单个术语。 整个字段内容没有高亮显示的功能。 如果想要突出显示某个短语,则必须在带引号的查询字符串中提供匹配术语(或短语)。 本部分将进一步介绍此方法。
查询请求上提供了命中词突出显示说明。 在引擎中触发查询扩展的查询(例如模糊搜索和通配符搜索)对结果高亮显示的支持有限。
命中项突出显示的要求
- 字段必须是
Edm.String或Collection(Edm.String) - 字段必须在
searchable指定属性
在请求中指定突出显示
若要返回突出显示的字词,请在查询请求中包含 highlight 参数。 该参数设置为逗号分隔的字段列表。
默认情况下,格式标记为 <em>,但你可以使用 highlightPreTag 和 highlightPostTag 参数来替代标记。 客户端代码将处理响应(例如,应用粗体字体或黄色背景)。
POST /indexes/good-books/docs/search?api-version=2026-04-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
默认情况下,Azure AI 搜索最多为每个字段返回五处突出显示。 你可以通过追加一个短划线并后接一个整数来调整此数字。 例如,"highlight": "description-10" 会在 description 字段中返回匹配内容中最多 10 个突出显示的字词。
突出显示的结果
当将突出显示添加到查询中时,响应中会为每个结果包含一个“@search.highlights”,以便您的应用程序代码可以定位该结构。 为“highlight”指定的字段列表包含在响应中。
在关键字搜索中,将单独扫描每个字词。 对“divine secrets”的查询将返回包含其中任一字词的任何文档的匹配项。
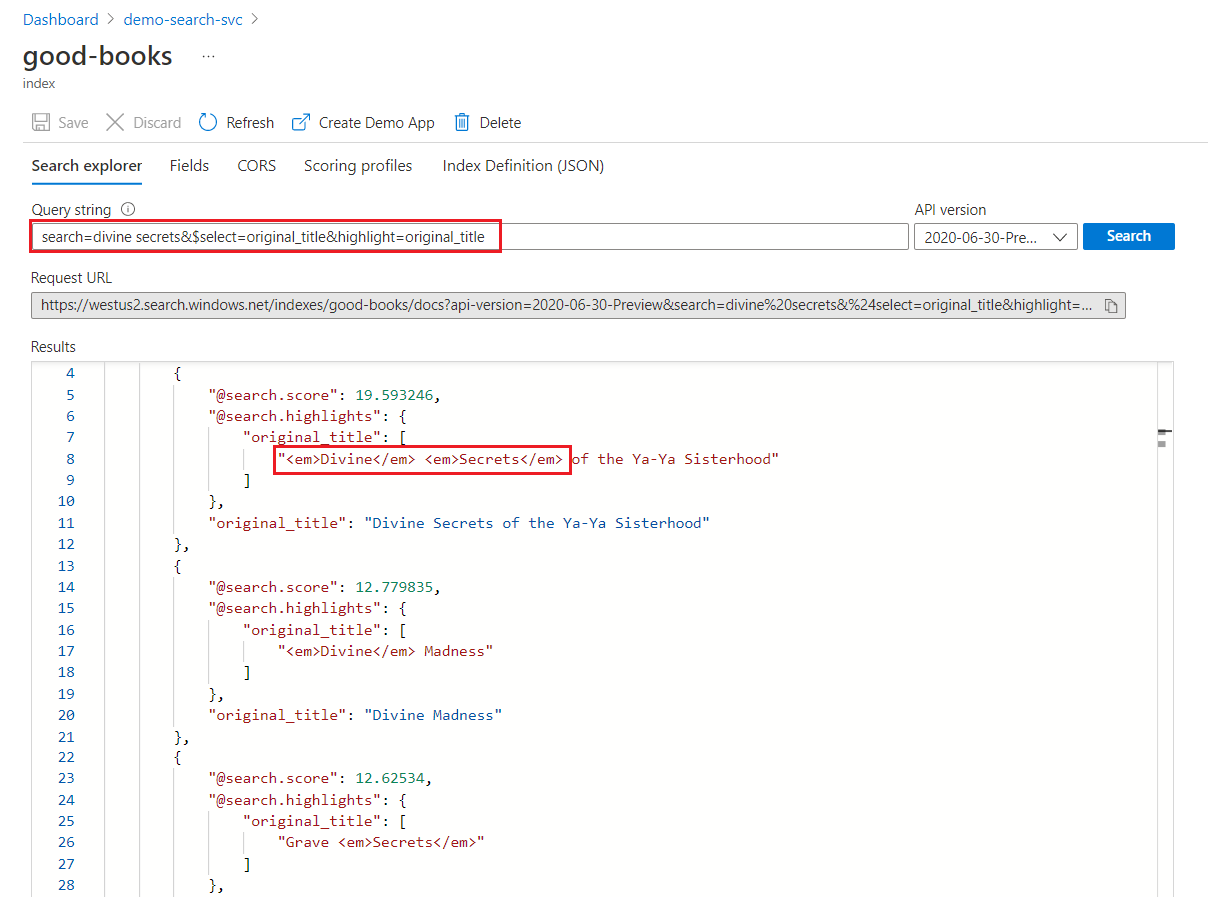
关键字搜索突出显示
在突出显示的字段中,格式设置将应用于完整字词。 例如,在匹配“The Divine Secrets of the Ya-Ya Sisterhood”时,尽管这些词是连续的,但格式还是逐个应用于每个词。
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
短语搜索高亮显示
完整字词格式设置甚至会应用于短语搜索,其中的多个字词用双引号括住。 以下示例与前面的查询相同,只不过“divine secrets”是以引号括住的短语形式提交的(某些 REST 客户端要求使用反斜杠 \" 来转义内部引号):
POST /indexes/good-books/docs/search?api-version=2026-04-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
由于条件现在具有这两个字词,因此在搜索索引中只找到一个匹配项。 对上一个查询的响应如下所示:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
旧版服务上的短语突出显示
在 2020 年 7 月 15 日之前创建的搜索服务为短语查询实现不同的突出显示体验。
以下示例假设查询字符串包含以引号括住的短语“super bowl”。 在 2020 年 7 月之前,短语中的任何术语都会被突出显示:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
对于在 2020 年 7 月之后创建的搜索服务,只会在“@search.highlights”中返回与完整短语查询匹配的短语:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
后续步骤
若要快速为客户端生成搜索页面,请考虑以下选项:
创建演示应用,在 Azure 门户中,创建包含搜索栏、分面导航和缩略图区域的 HTML 页面(如果有图像)。
向 Web 应用添加搜索提供了有关将 React JavaScript 库用于用户体验的 C# 教程和代码示例。 该应用是使用 Azure Static Web Apps 部署的,它实现了分页。