Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
在 Azure AI 搜索 中,vectorizer在查询执行期间将文本或图像转换为矢量,从而允许你针对矢量字段提交纯文本查询,而无需自行计算嵌入内容。
向量化器在搜索索引中定义,并通过向量描述文件分配给向量字段。 在查询时,向量器调用嵌入模型以从查询输入生成矢量。 有关详细信息,请参阅 在查询中使用集成向量化。
若要将向量器添加到索引,请在Azure门户中使用导入向导或索引设计器、Indexes - 创建或更新(REST API)或Azure SDK包。 本文使用 REST 进行说明。
小窍门
向量器处理查询时向量化。 若要在编制索引时同时向量化内容,请设置技能集和索引器,并使用嵌入技术。 有关详细信息,请参阅 在索引编制过程中使用集成矢量化。
先决条件
(可选)已启用诊断日志记录在搜索服务中以确认矢量查询的执行。
为您的矢量化器部署一个支持的嵌入模型。
更新和查询索引的权限。 本文使用建议的 无密钥身份验证。 将 Search Service Contributor 和 Search Index Data Reader 角色分配给用户帐户、登录Azure并获取访问令牌。 如果改用 API 密钥,请获取用于更新操作的管理密钥和用于搜索操作的查询密钥。
使用嵌入模型的权限。还可以使用 API 密钥。
我们建议在搜索服务中启用诊断日志记录,以确认矢量查询的执行。
支持的嵌入模型
Azure AI 搜索提供了多种类型的向量化器,每个向量器都与相应的技能配对。 技能在索引编制期间生成嵌入内容,而向量器在查询时生成嵌入内容。 必须对两者使用相同的嵌入模型,因此请选择指向同一模型部署的向量化技能对。
下表列出了向量器及其支持的模型和相关技能。
| 矢量化器 | 支持的模型 | 关联的技能 |
|---|---|---|
| Azure Vision | 多模式嵌入 4.0 API | Azure Vision 多模态嵌入 |
| 自定义 Web API | 任何嵌入模型(外部托管) | 自定义 Web API |
注释
只要使用一般可用的技能向量器对,向量化器通常就是可用的。 有关最新的可用性信息,请参阅上表中有关每个向量器和技能的文档。
使用向导定义向量器
Azure门户中的 Import 数据向导可以从Azure Blob 存储读取文件,创建包含分块字段和矢量化字段的索引,并添加向量器。 根据设计,向导生成的矢量化器被设置为用于为 Blob 内容编制索引的同一嵌入模型。
使用向导通过向量化器创建示例索引:
将文件上传到 Azure 存储中的容器。 我们使用了《地球夜景电子书》中的小型文本文件,在免费的搜索服务中测试这些说明。
运行 导入数据 向导。 选择数据源的 Blob 容器。
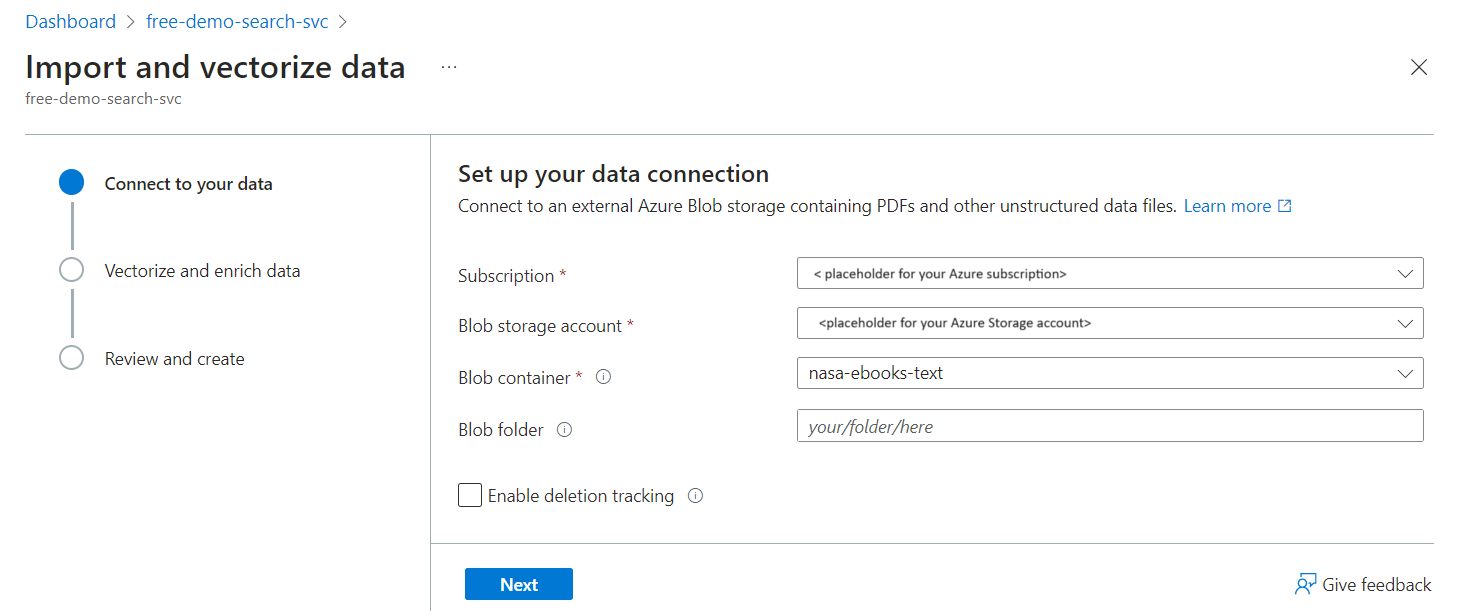
选择矢量化类型,如果适用,则选择模型部署。
向导完成并完成所有索引器处理后,应具有具有可搜索向量字段的索引。 该字段的 JSON 定义如下所示:
{ "name": "text_vector", "type": "Collection(Edm.Single)", "searchable": true, "filterable": false, "retrievable": true, "stored": true, "sortable": false, "facetable": false, "key": false, "dimensions": 1536, "vectorSearchProfile": "vector-nasa-ebook-text-profile", "synonymMaps": [] }还应具有向量特征、向量搜索算法和向量化器。 其 JSON 定义如下所示:
"algorithms": [ { "name": "vector-nasa-ebook-text-algorithm", "kind": "hnsw", "hnswParameters": { "metric": "cosine", "m": 4, "efConstruction": 400, "efSearch": 500 } } ], "profiles": [ { "name": "vector-nasa-ebook-text-profile", "algorithm": "vector-nasa-ebook-text-algorithm", "vectorizer": "vector-nasa-ebook-text-vectorizer" } ]

以编程方式定义向量器
如果不使用门户向导或想要将向量器添加到现有索引,则可以以编程方式定义向量器和向量配置文件。 矢量配置文件将向量器链接到一个或多个向量字段,并指定用于导航结构的矢量搜索算法。
若要在现有索引中定义向量化器和向量概况,请执行以下操作:
使用 Indexes - Get(REST API)检索索引定义。 将服务名称、索引名称和访问令牌替换为您自己的值。
### Get index definition GET https://my-search-service.search.azure.cn/indexes/my-index?api-version=2025-09-01 HTTP/1.1 Authorization: Bearer <your-access-token> // For API keys, replace this line with api-key: <your-admin-api-key>使用 索引 - 创建或更新 (REST API) 更新索引定义。 将完整索引定义粘贴到请求正文中。
### Update index definition PUT https://my-search-service.search.azure.cn/indexes/my-index?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json Authorization: Bearer <your-access-token> // For API keys, replace this line with api-key: <your-admin-api-key> // Paste your index definition here将节
algorithms添加到vectorSearch. 本部分定义用于导航结构的 矢量搜索算法 。"algorithms": [ { "name": "my_hnsw_algorithm", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } } ]将节
profiles添加到vectorSearch. 本部分引用前面步骤中定义的向量器和矢量搜索算法。"profiles": [ { "name": "my_vector_profile", "algorithm": "my_hnsw_algorithm", "vectorizer": "my_azure_open_ai_vectorizer" } ]在
fields数组中,通过指定vectorSearchProfile属性,将矢量档案分配给一个或多个矢量字段。"fields": [ ... // Trimmed for brevity { "name": "vector", "type": "Collection(Edm.Single)", "dimensions": 1536, "vectorSearchProfile": "my_vector_profile", "searchable": true, "retrievable": true }, { "name": "my_second_vector", "type": "Collection(Edm.Single)", "dimensions": 1536, "vectorSearchProfile": "my_vector_profile", "searchable": true, "retrievable": true } ]发送 PUT 请求以更新索引定义。 如果请求成功,应会收到
204 No Content响应。若要验证向量器和向量配置文件,请从第一步重新运行 GET 请求。 确认:
该
vectorSearch.vectorizers数组包含具有正确kind和连接参数的向量化器定义。该
vectorSearch.profiles数组包含按名称引用向量器的配置文件。该
vectorSearch.algorithms数组包括在您的配置文件中引用的矢量搜索算法。vectorSearchProfile数组中fields向量字段的属性与配置文件名称匹配。
测试矢量器
若要确认向量器的工作原理,请发送传递文本字符串而不是向量的 向量查询 。 以下示例将示例索引作为定位目标,来自使用向导定义向量器,并且可以通过调整字段名称和查询参数来测试您自己的索引。
使用 文档 - 搜索帖子 (REST API)发送请求。 将服务名称、索引名称和访问令牌替换为您自己的值。
### Test a vectorizer with a vector query
POST https://my-search-service.search.azure.cn/indexes/vector-nasa-ebook-txt/docs/search?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
Authorization: Bearer <your-access-token> // For API keys, replace this line with api-key: <your-query-api-key>
{
"count": true,
"select": "title, chunk",
"vectorQueries": [
{
"kind": "text",
"text": "what cloud formations exist in the troposphere",
"fields": "text_vector",
"k": 3,
"exhaustive": true
}
]
}
要点:
"kind": "text"告知搜索引擎输入是文本字符串,并使用与搜索字段关联的向量器。"text"是要向量化的普通语言字符串。"fields": "text_vector"是要查询的字段的名称。 如果使用向导生成的示例索引,则生成的矢量字段会命名为text_vector。"exhaustive": true绕过 HNSW 图形并对所有矢量执行暴力搜索。 此设置对于测试准确性很有用,但比默认近似搜索慢。 在生产查询中删除此参数以提高性能。查询未设置任何向量器属性。 搜索引擎从分配给字段的矢量配置文件中自动读取它们。
如果矢量化程序配置正确,响应将返回按相似性排名的匹配文档。 你应该得到三个结果(k:3),其中第一个是最相关的。
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.66195244,
"chunk": "Cloud Shadow\tGermany\nIn November 2012, the Earth Observing...",
"title": "page-25.txt"
},
... // Trimmed for brevity
]
}
故障排除
如果向量器未按预期工作,请从常见错误表开始,然后检查诊断日志以了解更多详细信息。
请注意,在查询时没有要设置的矢量器属性。 该查询根据索引中的向量配置文件字段分配读取向量化器属性。
检查日志
如果您为搜索服务启用了诊断日志记录,请运行以下 Kusto 查询,以确认在矢量字段上的查询执行。
OperationEvent
| where TIMESTAMP > ago(30m)
| where Name == "Query.Search" and AdditionalInfo["QueryMetadata"]["Vectors"] has "TextLength"
最佳做法
在生产环境中使用托管标识而不是 API 密钥。 托管标识更安全,避免密钥轮换开销。 有关详细信息,请参阅 配置使用托管标识进行连接的搜索服务。
将嵌入模型部署到与search service相同的区域中。 归置可降低延迟并提高服务之间的数据传输速度。 向量器可在Azure AI 搜索可用的所有区域中使用,但模型可用性因提供程序而异。
为了索引和查询,分别使用相同嵌入模型的单独部署。 专用部署允许为每个工作负荷单独分配 TPM 配额,并更轻松地识别流量源。