Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
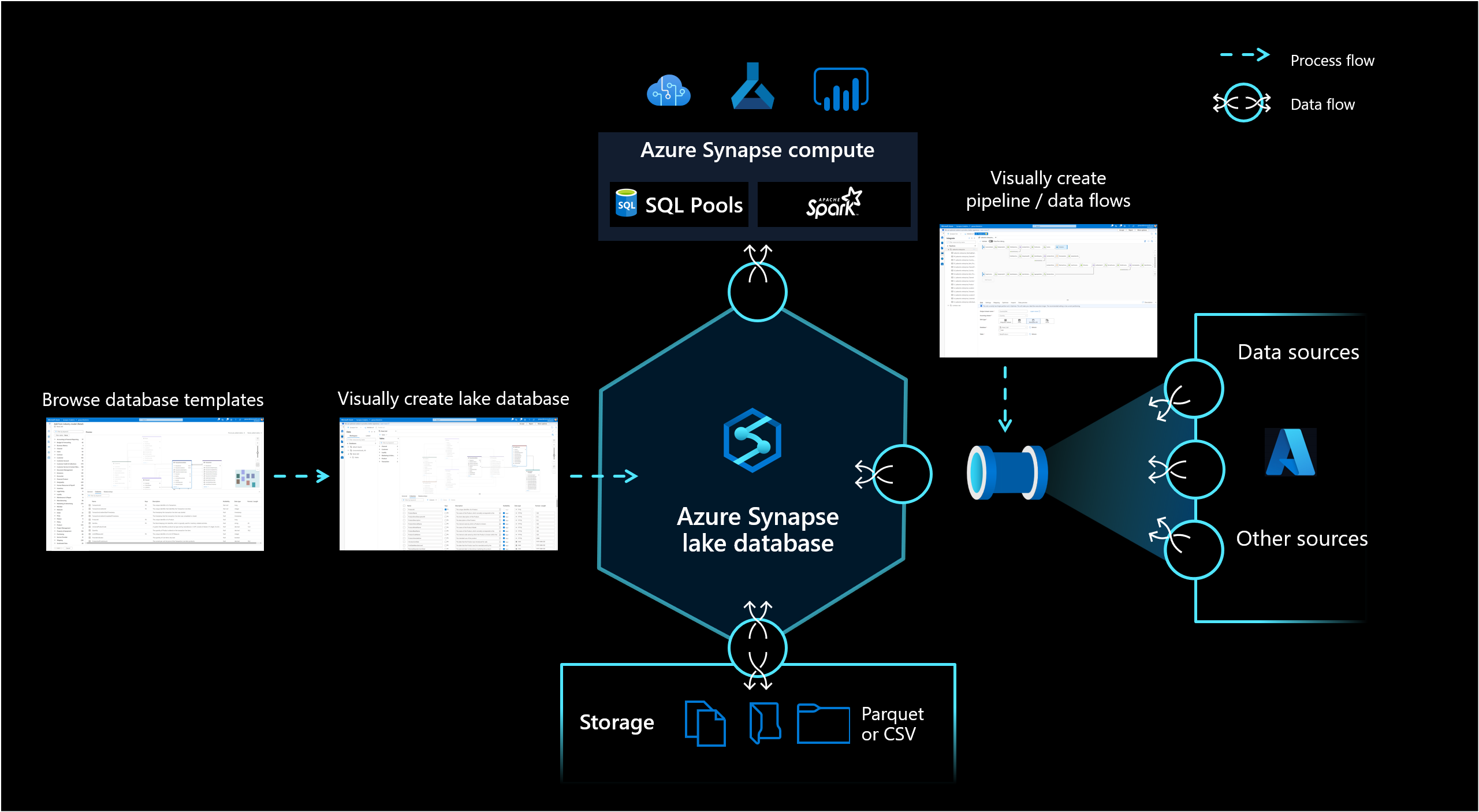
Azure Synapse Analytics 中的湖数据库使客户能够将数据库设计、有关存储的数据的元数据信息,以及描述数据的存储方式和存储位置的可能性结合起来。 湖数据库解决了当前数据湖的难题,即很难理解数据的结构。
数据库设计器
借助 Synapse Studio 中新的数据库设计器,你将可以为你的湖数据库创建数据模型,并向其中添加更多信息。 可以对每个实体和属性进行描述,以提供有关模型的更多信息,这些信息不仅包含实体还包含关系。 特别是,无法建立模型关系对于数据湖的交互是一项挑战。 现在,我们使用集成的设计器解决了这一难题,该设计器提供了在数据库中已有但在湖上没有的可能性。 此外,还可以向模型添加说明和可能的演示值,使将来与之交互的人员能够根据需要获得信息,以更好地了解数据。
注意
湖数据库中元数据的最大大小为 10 GB。 尝试发布或更新大小超过 10 GB 的模型将失败。 若要解决此问题,请通过移除表和列来减小模型大小。 请考虑将大型模型拆分为多个湖数据库,以避免此限制。
数据存储
湖数据库在 Azure 存储帐户上使用数据湖来存储数据库的数据。 数据可以存储为 Parquet、Delta 或 CSV 格式,不同的设置可用于优化存储。 每个湖数据库都使用链接服务来定义根数据文件夹的位置。 对于每个实体,默认情况下,在数据湖上的此数据库文件夹中创建单独的文件夹。 默认情况下,湖数据库中的所有表都使用相同的格式,但如果有要求,每个实体的数据格式和位置都可以更改。
注意
发布湖数据库不会创建在 Spark 或 SQL 中查询数据所需的任何底层结构或架构。 发布后,使用管道将数据加载到湖数据库中以开始对其进行查询。
目前,Synapse Studio 不支持对湖数据库的 Delta 格式支持。
存储和 Synapse 之间的湖数据库对象同步是单向的。 请务必使用 Synapse Studio 中的数据库设计器对湖数据库对象执行任何创建或架构修改操作。 如果改为从 Spark 或直接在存储中进行此类更改,则湖数据库的定义将变得不同步。如果发生这种情况,数据库设计器中可能会显示旧的湖数据库定义。 需要在数据库设计器中复制和发布此类更改,才能使湖数据库恢复同步。
数据库计算
湖数据库在 Synapse SQL 无服务器 SQL 池和 Apache Spark 中公开,为用户提供将存储与计算分离的功能。 与湖数据库关联的元数据使得不同的计算引擎不仅可以轻松地提供集成体验,还可以使用数据湖上原本不支持的额外信息(例如,关系)。