Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本教程介绍如何使用 Foundry Tools 在 Azure Synapse Analytics 中丰富数据。 你将使用 Foundry Tools 中的 Azure 语言 的 text analytics 功能来执行情绪分析。
Azure Synapse中的用户可以选择包含文本列的表来扩充情绪。 这些情绪可以是积极、消极、混杂或中立的。 系统还将返回概率。
本教程涉及:
- 获取 Spark 表数据集的步骤,该数据集中包含用于进行情感分析的文本列。
- 使用 Azure Synapse 的向导体验,通过 Text Analytics 丰富语言数据。
如果没有Azure订阅,开始前创建试用帐户。
先决条件
- Azure Synapse Analytics 工作区,配置为默认存储的一个 Azure Data Lake Storage Gen2 存储帐户。 你需要成为你所使用的 Data Lake Storage Gen2 文件系统的 Storage Blob 数据参与者。
- Azure Synapse Analytics 工作区中的 Spark 池。 有关详细信息,请参阅
在 Azure Synapse 。 - 本教程中所述的预配置步骤:在 Azure Synapse 中配置 Foundry 工具。
登录到Azure portal
登录到 Azure portal。
创建 Spark 表
本教程需要一个 Spark 表。
下载包含text analytics数据集的 FabrikamComments.csv 文件。
在 Synapse Analytics 中,打开Data 和 Linked 下的存储帐户。
将文件上传到Data Lake Storage Gen2中的Azure Synapse storage帐户。
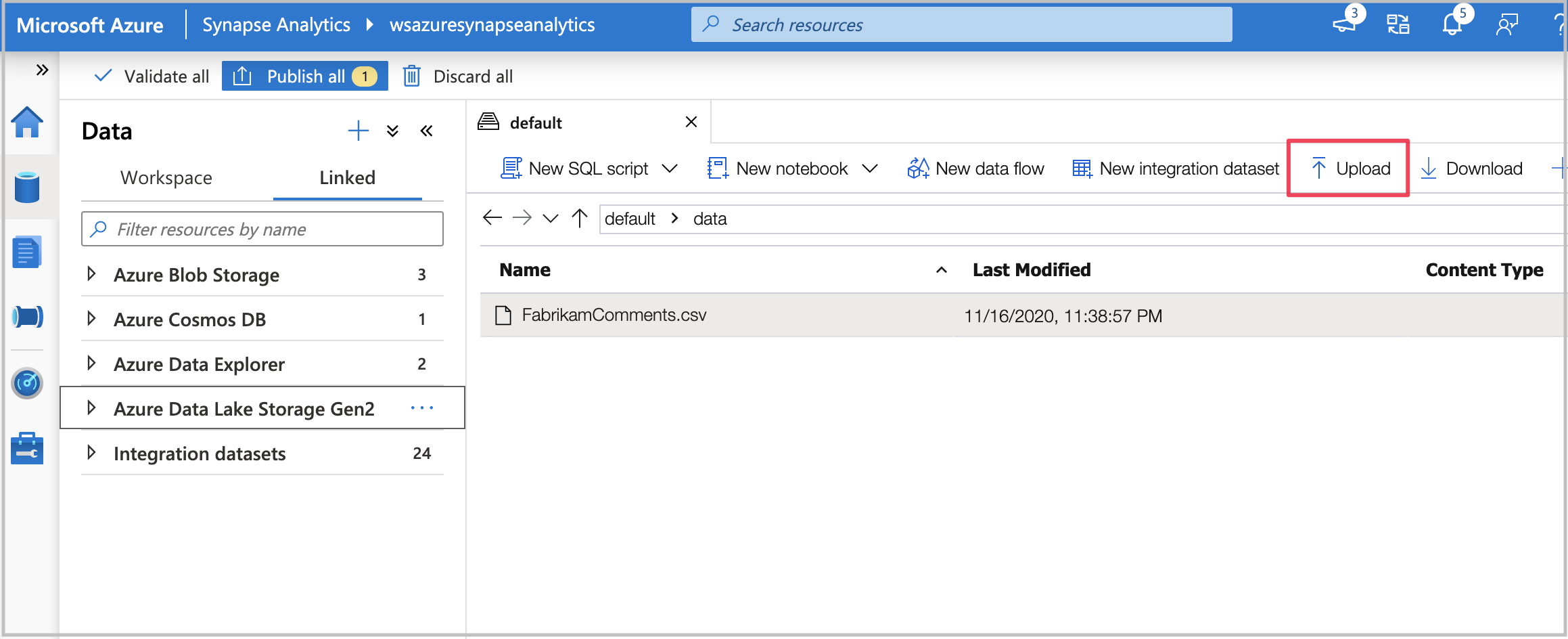
通过右键单击文件并选择“新建笔记本”“创建 Spark 表”,从 .csv 文件创建 Spark 表>。
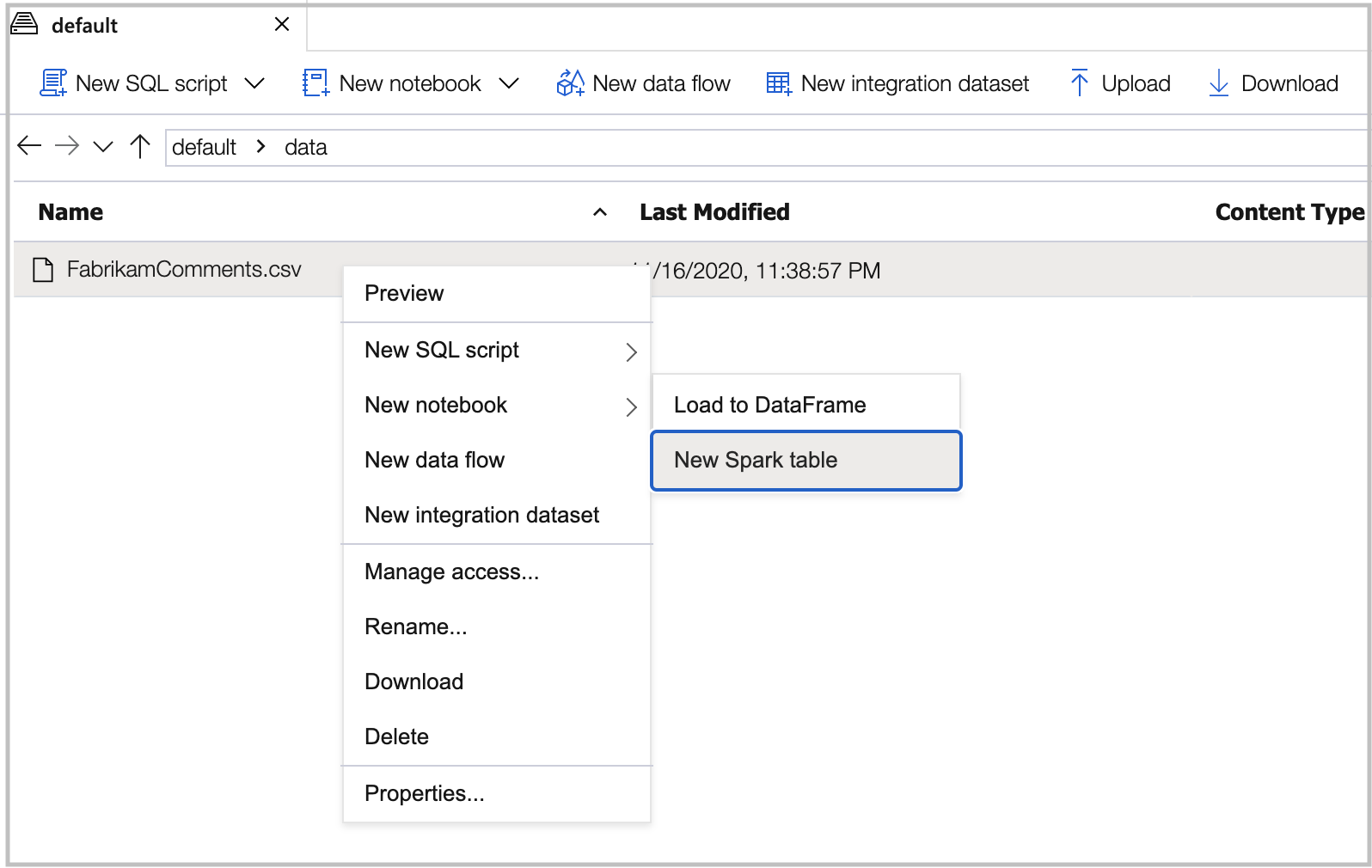
设置
header=True并命名代码单元格中的表。 然后在 Spark 池上运行笔记本。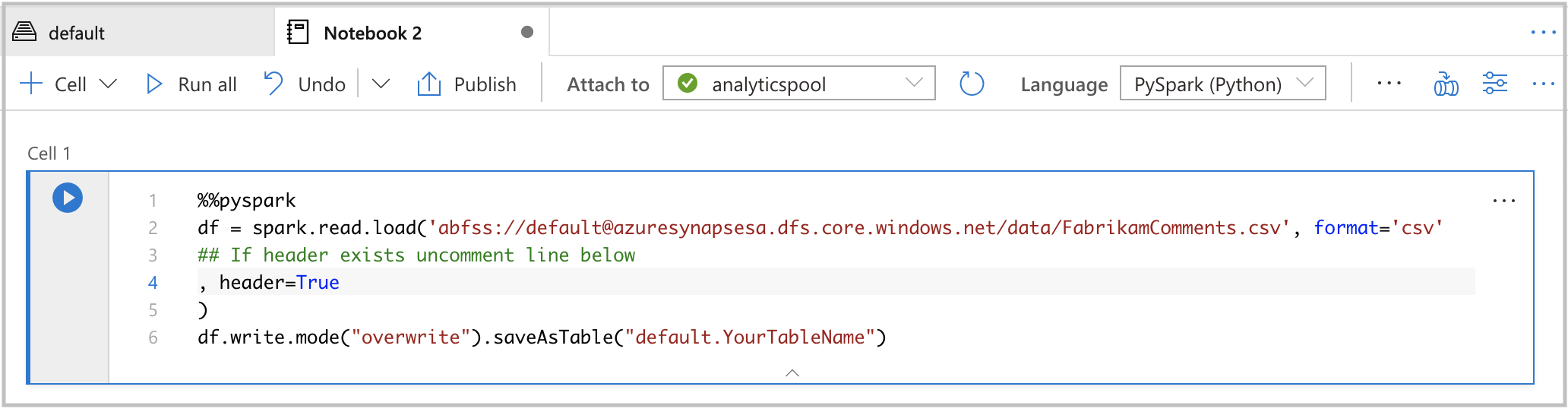
%%pyspark df = spark.read.load('abfss://default@azuresynapsesa.dfs.core.chinacloudapi.cn/data/FabrikamComments.csv', format='csv' ## If a header exists, uncomment the line below , header=True ) df.write.mode("overwrite").saveAsTable("default.YourTableName")
打开 Foundry 工具向导
在数据页的“工作区”选项卡中,在默认湖表下,右键单击在上一步骤中创建的 Spark 表。
选择Machine Learning>使用模型进行预测以打开向导。
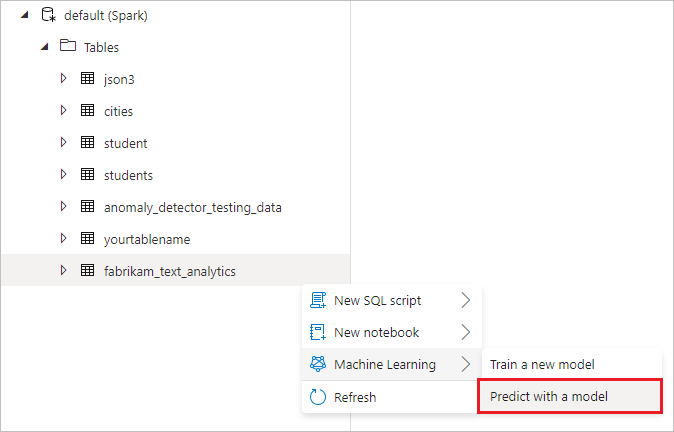
此时会显示配置面板,你需要选择一个预训练模型。 选择“情绪分析”。
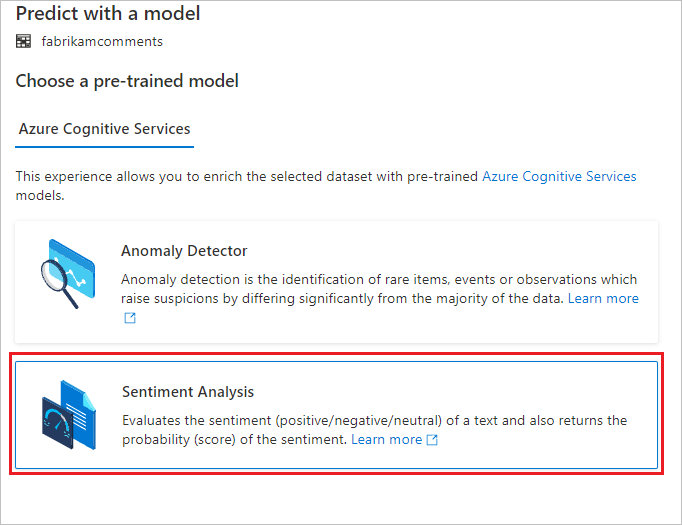
配置情绪分析
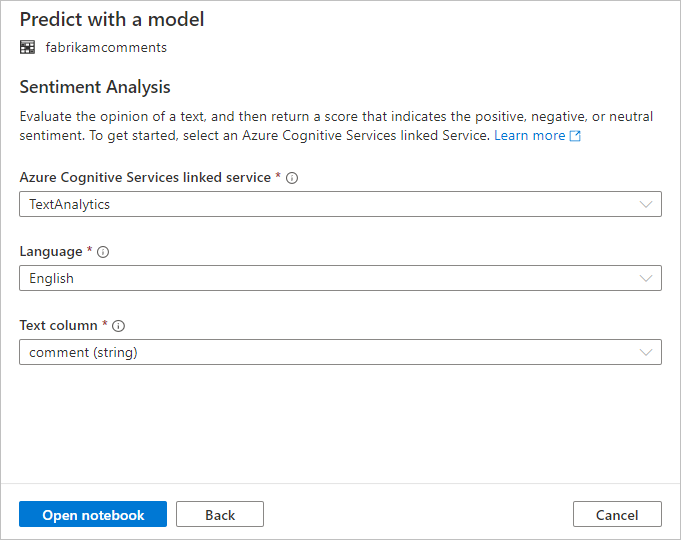
接下来,配置情绪分析。 请选择以下详细信息:
- Azure 认知服务链接服务:作为先决条件步骤的一部分,你创建了一个链接到 Microsoft Foundry 工具的链接服务。 请在这里选择该服务。
- 语言:选择“英语”作为要对其进行情绪分析的文本的语言。
- 文本列:选择“注释(字符串)”作为数据集中你要对其进行分析以确定情绪的文本列。
完成后,选择“打开笔记本”。 这将使用 PySpark 代码生成笔记本,该代码使用 Foundry 工具执行情绪分析。
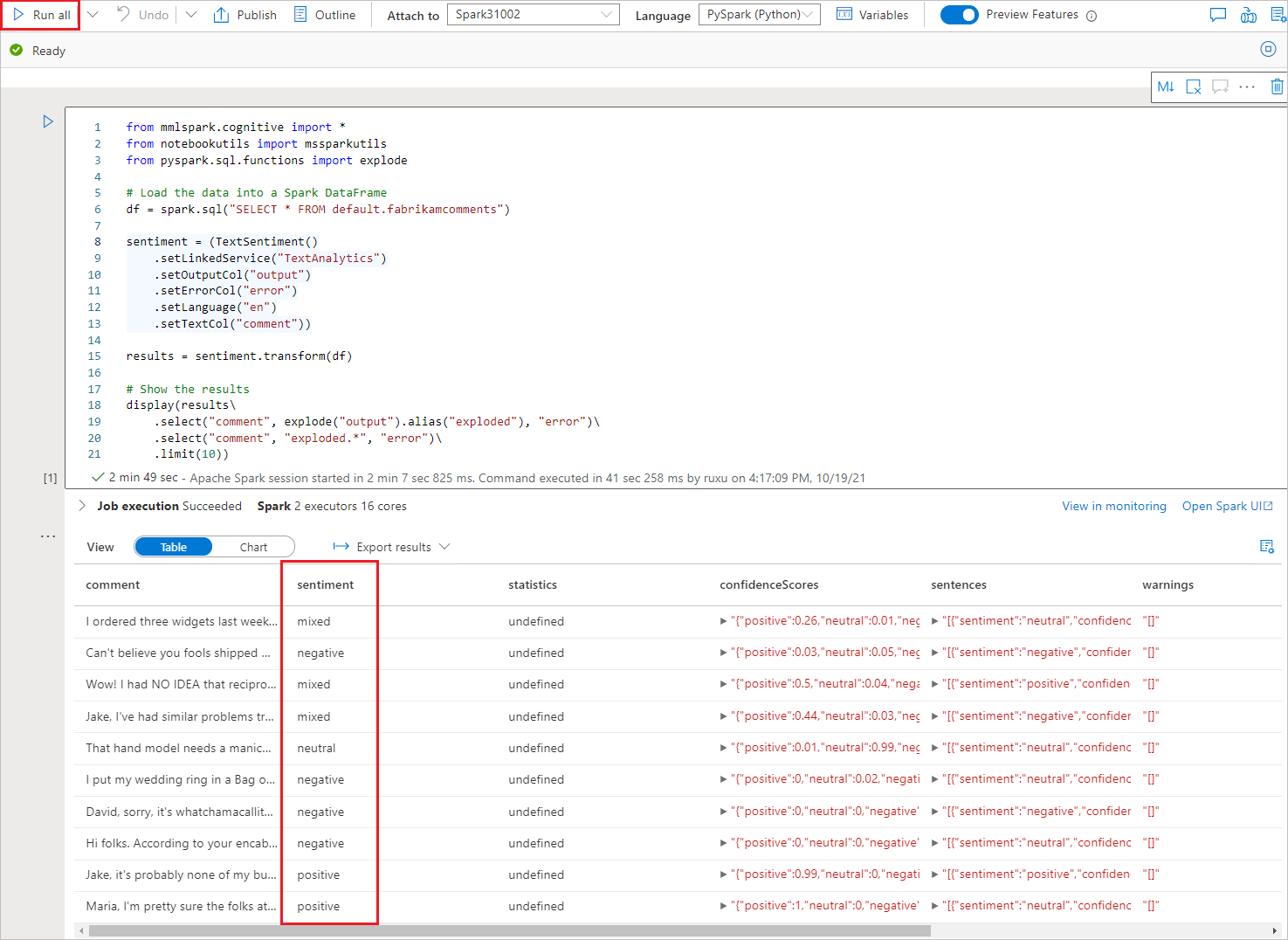
运行笔记本
刚刚打开的笔记本使用 SynapseML 库连接到 Foundry Tools。 你提供的 Foundry 工具链接服务允许你从此体验中安全地引用 Foundry 工具,而无需透露任何机密。
现在,可以运行所有单元,以使用情绪扩充数据。 选择“全部运行”。
情绪返回结果为“积极”、“消极”、“中立”或“混杂” 。 你还将获得每种情绪的概率。 详细了解 Foundry Tools 中的情绪分析。
相关内容
- 教程:使用 Foundry 工具进行异常情况检测
- Tutorial:Azure Synapse 专用 SQL 池中机器学习模型评分
- Azure Synapse Analytics 中的 Machine Learning 功能