Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Microsoft Spark 实用工具 (MSSparkUtils) 是内置的包,可帮助你轻松执行常见任务。 可以使用 MSSparkUtils 来处理文件系统、获取环境变量、将笔记本链在一起以及处理机密。 MSSparkUtils 在 PySpark (Python)、Scala、.NET Spark (C#) 和 R (Preview) 笔记本以及 Synapse 管道中可用。
先决条件
配置对 Azure Data Lake Storage Gen2 的访问
Synapse 笔记本使用 Microsoft Entra 直通来访问 ADLS Gen2 帐户。 你需要成为“存储 Blob 数据参与者”才能访问 ADLS Gen2 帐户(或文件夹)。
Synapse 管道使用工作区的托管服务标识 (MSI) 访问存储帐户。 若要在管道活动中使用 MSSparkUtils,你的工作区标识需要为“存储 Blob 数据参与者”才能访问 ADLS Gen2 帐户(或文件夹)。
请按照以下步骤操作,确保 Microsoft Entra ID 和工作区 MSI 可以访问 ADLS Gen2 帐户:
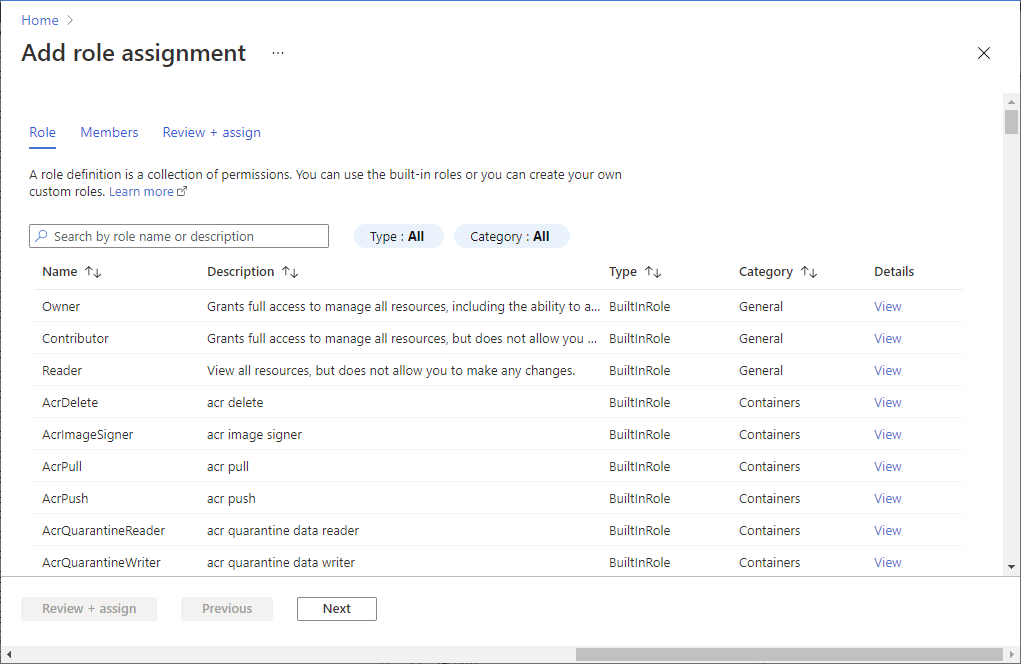
打开 Azure 门户和要访问的存储帐户。 可以导航到要访问的特定容器。
从左侧面板中选择“访问控制(IAM)”。
选择“添加”“添加角色分配”,打开“添加角色分配”页面 。
分配以下角色。 有关详细步骤,请参阅使用 Azure 门户分配 Azure 角色。
设置 值 角色 存储 Blob 数据参与者 将访问权限分配到 USER 和 MANAGEDIDENTITY 成员 你的 Microsoft Entra 帐户和工作区标识 注意
托管标识名称也是工作区名称。
选择“保存”。
可以通过以下 URL 使用 Synapse Spark 访问 ADLS Gen2 上的数据:
abfss://<container_name>@<storage_account_name>.dfs.core.chinacloudapi.cn/<path>
配置对 Azure Blob 存储的访问
Synapse 使用共享访问签名 (SAS) 访问 Azure Blob 存储。 为了避免在代码中公开 SAS 密钥,建议在 Synapse 工作区中为要访问的 Azure Blob 存储帐户创建一个新的链接服务。
按照以下步骤为 Azure Blob 存储帐户添加新的链接服务:
- 打开 Azure Synapse Studio。
- 从左侧面板中选择“管理”,然后选择“外部连接”下的“链接服务” 。
- 在右侧的“新建链接服务”面板中搜索“Azure Blob 存储” 。
- 选择“继续”。
- 选择要访问的 Azure Blob 存储帐户,并配置链接服务名称。 建议使用“帐户密钥”作为“身份验证方法” 。
- 选择“测试连接”以验证设置是否正确。
- 首先选择“创建”,然后单击“全部发布”以保存所做更改 。
可以通过以下 URL 使用 Synapse Spark 访问 Azure Blob 存储上的数据:
wasb[s]://<container_name>@<storage_account_name>.blob.core.chinacloudapi.cn/<path>
下面是代码示例:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.chinacloudapi.cn/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.chinacloudapi.cn' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.chinacloudapi.cn/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.chinacloudapi.cn",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.chinacloudapi.cn", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.chinacloudapi.cn/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.chinacloudapi.cn/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.chinacloudapi.cn',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
配置对 Azure Key Vault 的访问
可以添加 Azure Key Vault 作为链接服务来管理 Synapse 中的凭据。 按照以下步骤将 Azure Key Vault 添加为 Synapse 链接服务:
从左侧面板中选择“管理”,然后选择“外部连接”下的“链接服务” 。
在右侧的“新建链接服务”面板中搜索“Azure Key Vault” 。
选择要访问的 Azure Key Vault 帐户,并配置链接服务名称。
选择“测试连接”以验证设置是否正确。
首先选择“创建”,然后单击“全部发布”以保存所做更改 。
Synapse 笔记本使用 Microsoft Entra 直通来访问 Azure Key Vault。 Synapse 管道使用工作区标识 (MSI) 来访问 Azure Key Vault。 为了确保你的代码在笔记本和 Synapse 管道中都能正常工作,我们建议你向 Microsoft Entra 帐户和工作区标识授予机密访问权限。
请按照以下步骤向工作区标识授予机密访问权限:
- 打开 Azure 门户和要访问的 Azure Key Vault。
- 在左侧面板中选择“访问策略”。
- 选择“添加访问策略”:
- 选择“密钥、机密和证书管理”作为配置模板。
- 在选择主体中选择你的 Microsoft Entra 帐户和工作区标识(与工作区名称相同),或确保它已分配。
- 依次选择“选择”和“添加” 。
- 选择“保存”按钮以提交更改。
文件系统实用工具
mssparkutils.fs 提供用于处理各种文件系统的实用工具,包括 Azure Data Lake Storage Gen2 (ADLS Gen2) 和 Azure Blob 存储。 请确保正确配置对 Azure Data Lake Storage Gen2 和 Azure Blob 存储的访问。
运行以下命令以概要了解可用的方法:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
结果:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
列出文件
列出目录的内容。
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
查看文件属性
返回文件属性,其中包括文件名、文件路径、文件大小、文件修改时间,以及它是目录还是文件。
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
创建新目录
创建给定目录(如果不存在)和任何必要的父目录。
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
复制文件
复制文件或目录。 支持跨文件系统复制。
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
高性能复制文件
此方法会提供更快的方式来复制或移动文件,尤其是面对大量数据时。
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
预览文件内容
以 UTF-8 编码的字符串形式返回给定文件的第一个“maxBytes”之前的字节。
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
移动文件
移动文件或目录。 支持跨文件系统移动。
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
写入文件
将以 UTF-8 编码的给定字符串写入文件。
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
将内容追加到文件
将以 UTF-8 编码的给定字符串追加到文件中。
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
注意
- 由于缺乏原子性保证,
mssparkutils.fs.append()和mssparkutils.fs.put()不支持并发写入同一文件。 - 在
mssparkutils.fs.append循环中使用forAPI 写入同一文件时,我们建议在重复写入之间添加大约 0.5s~1s 的sleep语句。 这是因为mssparkutils.fs.appendAPI 的内部flush操作是异步的,因此短延迟有助于确保数据完整性。
删除文件或目录
删除文件或目录。
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
笔记本实用工具
不支持。
可以使用 MSSparkUtils 笔记本实用工具运行笔记本或使用值退出笔记本。 运行以下命令以概要了解可用的方法:
mssparkutils.notebook.help()
获取结果:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
注意
笔记本实用工具不适用于 Apache Spark 作业定义 (SJD)。
引用笔记本
引用笔记本并返回其退出值。 可以在笔记本中以交互方式或在管道中运行嵌套函数调用。 所引用的笔记本将在其调用此函数的 Spark 池上运行。
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
例如:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
运行完成后,你将看到名为“查看笔记本运行:笔记本名称”的快照链接,显示在单元格输出中,可以单击该链接以查看此特定运行的快照。

并行引用运行多个笔记本
mssparkutils.notebook.runMultiple() 方法让你可以并行运行多个笔记本,或使用预定义的拓扑结构。 该 API 在 Spark 会话中使用多线程实现机制,这意味着计算资源由引用笔记本运行共享。
通过 mssparkutils.notebook.runMultiple(),您可以:
同时执行多个笔记本,而无需等待每个笔记本完成。
使用简单的 JSON 格式为笔记本指定依赖项和执行顺序。
优化 Spark 计算资源的使用并降低 Synapse 项目的成本。
在输出中查看每个笔记本运行记录的快照,并方便地调试/监视笔记本任务。
获取每个执行活动的退出值,并在下游任务中使用它们。
还可以尝试运行 mssparkutils.notebook.help("runMultiple") 来查找示例和详细用法。
下面是使用此方法并行运行一组笔记本的简单示例:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
根笔记本中的执行结果如下所示:

下面是使用 mssparkutils.notebook.runMultiple() 运行具有拓扑结构的笔记本的示例。 使用此方法通过代码体验轻松编排笔记本。
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
注意
- 该方法仅在适用于 Apache Spark 3.3 的 Azure Synapse 运行时和适用于 Apache Spark 3.4 的 Azure Synapse 运行时中支持。
- 多个笔记本运行的并行度受限于 Spark 会话的总可用计算资源。
退出笔记本
使用值退出笔记本。 可以在笔记本中以交互方式或在管道中运行嵌套函数调用。
在笔记本中以交互方式调用 exit() 函数时,Azure Synapse 将引发异常、跳过运行子序列单元格并使 Spark 会话保持活动状态。
协调在 Synapse 管道中调用
exit()函数的笔记本时,Azure Synapse 将返回退出值、完成管道运行并停止 Spark 会话。在所引用的笔记本中调用
exit()函数时,Azure Synapse 将在其中停止进一步的执行,并继续运行调用run()函数的笔记本中的下一个单元格。 例如:Notebook1 有三个单元格,调用第二个单元格中的exit()函数。 Notebook2 有五个单元格,调用第三个单元格中的run(notebook1)函数。 运行 Notebook2 时,如果命中exit()函数,Notebook1 将在第二个单元格停止。 Notebook2 将继续运行其第四和第五个单元格。
mssparkutils.notebook.exit("value string")
例如:
Sample1 笔记本在 folder/ 下查找以下两个单元格 :
- 单元格 1 定义 input 参数,默认值设为 10。
- 单元格 2 退出笔记本,input 作为退出值。
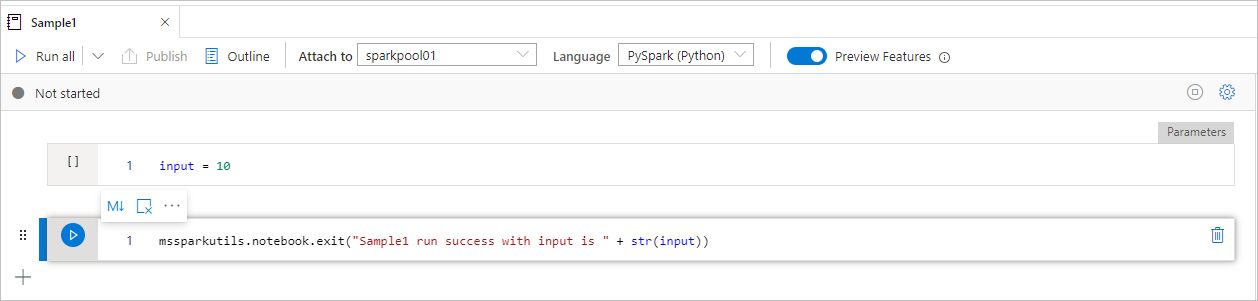
可以使用默认值在另一笔记本中运行 Sample1:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
结果:
Sample1 run success with input is 10
可以在另一笔记本中运行 Sample1,并将 input 值设为 20 :
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
结果:
Sample1 run success with input is 20
可以使用 MSSparkUtils 笔记本实用工具运行笔记本或使用值退出笔记本。 运行以下命令以概要了解可用的方法:
mssparkutils.notebook.help()
获取结果:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
引用笔记本
引用笔记本并返回其退出值。 可以在笔记本中以交互方式或在管道中运行嵌套函数调用。 所引用的笔记本将在其调用此函数的 Spark 池上运行。
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
例如:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
运行完成后,你将看到名为“查看笔记本运行:笔记本名称”的快照链接,显示在单元格输出中,可以单击该链接以查看此特定运行的快照。
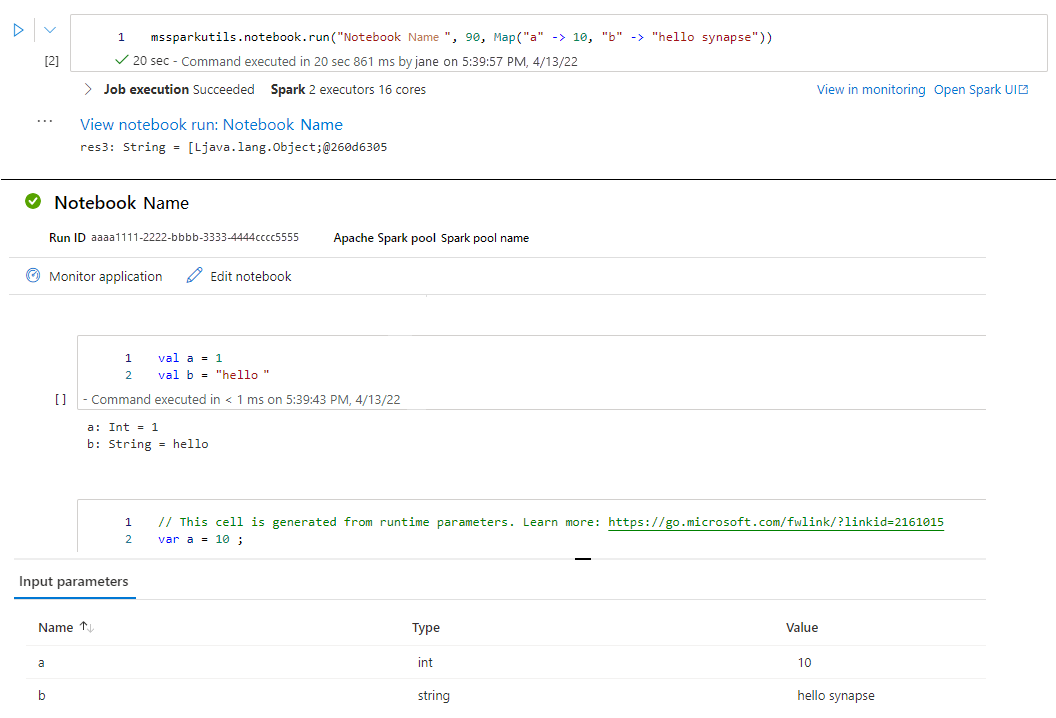
退出笔记本
使用值退出笔记本。 可以在笔记本中以交互方式或在管道中运行嵌套函数调用。
在笔记本中以交互方式调用
exit()函数时,Azure Synapse 将引发异常、跳过运行子序列单元格并使 Spark 会话保持活动状态。协调在 Synapse 管道中调用
exit()函数的笔记本时,Azure Synapse 将返回退出值、完成管道运行并停止 Spark 会话。在所引用的笔记本中调用
exit()函数时,Azure Synapse 将在其中停止进一步的执行,并继续运行调用run()函数的笔记本中的下一个单元格。 例如:Notebook1 有三个单元格,调用第二个单元格中的exit()函数。 Notebook2 有五个单元格,调用第三个单元格中的run(notebook1)函数。 运行 Notebook2 时,如果命中exit()函数,Notebook1 将在第二个单元格停止。 Notebook2 将继续运行其第四和第五个单元格。
mssparkutils.notebook.exit("value string")
例如:
Sample1 笔记本在 mssparkutils/folder/ 下查找以下两个单元格 :
- 单元格 1 定义 input 参数,默认值设为 10。
- 单元格 2 退出笔记本,input 作为退出值。
可以使用默认值在另一笔记本中运行 Sample1:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
结果:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
可以在另一笔记本中运行 Sample1,并将 input 值设为 20 :
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
结果:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
可以使用 MSSparkUtils 笔记本实用工具运行笔记本或使用值退出笔记本。 运行以下命令以概要了解可用的方法:
mssparkutils.notebook.help()
获取结果:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
引用笔记本
引用笔记本并返回其退出值。 可以在笔记本中以交互方式或在管道中运行嵌套函数调用。 所引用的笔记本将在其调用此函数的 Spark 池上运行。
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
例如:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
运行完成后,你将看到名为“查看笔记本运行:笔记本名称”的快照链接,显示在单元格输出中,可以单击该链接以查看此特定运行的快照。
退出笔记本
使用值退出笔记本。 可以在笔记本中以交互方式或在管道中运行嵌套函数调用。
在笔记本中以交互方式调用
exit()函数时,Azure Synapse 将引发异常、跳过运行子序列单元格并使 Spark 会话保持活动状态。协调在 Synapse 管道中调用
exit()函数的笔记本时,Azure Synapse 将返回退出值、完成管道运行并停止 Spark 会话。在所引用的笔记本中调用
exit()函数时,Azure Synapse 将在其中停止进一步的执行,并继续运行调用run()函数的笔记本中的下一个单元格。 例如:Notebook1 有三个单元格,调用第二个单元格中的exit()函数。 Notebook2 有五个单元格,调用第三个单元格中的run(notebook1)函数。 运行 Notebook2 时,如果命中exit()函数,Notebook1 将在第二个单元格停止。 Notebook2 将继续运行其第四和第五个单元格。
mssparkutils.notebook.exit("value string")
例如:
Sample1 笔记本在 folder/ 下查找以下两个单元格 :
- 单元格 1 定义 input 参数,默认值设为 10。
- 单元格 2 退出笔记本,input 作为退出值。
可以使用默认值在另一笔记本中运行 Sample1:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
结果:
Sample1 run success with input is 10
可以在另一笔记本中运行 Sample1,并将 input 值设为 20 :
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
结果:
Sample1 run success with input is 20
凭据实用工具
可以使用 MSSparkUtils 凭据实用工具获取链接服务的访问令牌,并管理 Azure Key Vault 中的机密。
运行以下命令以概要了解可用的方法:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
获取结果:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
注意
目前 C# 不支持 getSecretWithLS(linkedService, secret)。
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
获取令牌
返回给定受众的 Microsoft Entra 令牌和名称(可选)。 下表列出了所有可用的受众类型:
| 受众类型 | 要在 API 调用中使用的字符串文本 |
|---|---|
| Azure 存储 | Storage |
| Azure Key Vault | Vault |
| Azure 管理 | AzureManagement |
| Azure SQL Data Warehouse(专用和无服务器) | DW |
| Azure Synapse | Synapse |
| Azure 数据工厂 | ADF |
| Azure Database for MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
验证令牌
如果令牌尚未过期,则返回 true。
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
获取链接服务的连接字符串或凭据
返回链接服务的连接字符串或凭据。
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
使用工作区标识获取机密
使用工作区标识返回给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。 请确保正确配置对 Azure Key Vault 的访问。
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
使用用户凭据获取机密
使用用户凭据返回给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
使用工作区标识放置机密
使用工作区标识放置给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。 请确保正确配置对 Azure Key Vault 的访问。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
使用工作区标识放置机密
使用工作区标识放置给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。 请确保正确配置对 Azure Key Vault 的访问。
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
使用工作区标识放置机密
使用工作区标识放置给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。 请确保正确配置对 Azure Key Vault 的访问。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
使用用户凭据放置机密
使用用户凭据放置给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
使用用户凭据放置机密
使用用户凭据放置给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
使用用户凭据放置机密
使用用户凭据放置给定 Azure Key Vault 名称、机密名称和链接服务名称的 Azure Key Vault 机密。
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
环境实用工具
运行以下命令以概要了解可用的方法:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
获取结果:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
获取用户名
返回当前用户名。
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
获取用户 ID
返回当前用户 ID。
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
获取作业 ID
返回作业 ID。
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
获取工作区名称
返回工作区名称。
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
获取池名称
返回 Spark 池名称。
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
获取群集 ID
返回当前群集 ID。
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
运行时上下文
Mssparkutils 运行时 utils 公开了 3 个运行时属性,可以使用 mssparkutils 运行时上下文来获取如下所列的属性:
- Notebookname - 当前笔记本的名称,将始终返回交互模式和管道模式的值。
- Pipelinejobid - 管道运行 ID,将在管道模式下返回值,在交互模式下返回空字符串。
- Activityrunid - 笔记本活动运行 ID,将在管道模式下返回值,在交互模式下返回空字符串。
当前运行时上下文同时支持 Python 和 Scala。
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
会话管理
停止交互式会话
有时,在代码中调用 API 来停止交互式会话比手动单击停止按钮更方便。 对于这种情况,我们提供了适用于 Scala 和 Python 的 API mssparkutils.session.stop() 来支持通过代码停止交互式会话。
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() API 将在后台以异步方式停止当前交互式会话,它会停止 Spark 会话并释放该会话占用的资源,使这些资源可供同一池中的其他会话使用。
注意
我们不建议在代码中调用语言内置的 API(例如 Scala 中的 sys.exit 或 Python 中的 sys.exit()),因为此类 API 只会终止解释器进程,使 Spark 会话仍保持活动状态且不会释放资源。
包依赖项
若要在本地开发笔记本或作业,并且需要为编译/IDE 提示引用相关包,则可使用以下包。