Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文提供有关在 Synapse SQL 池架构中设计复制表的建议。 使用这些建议通过减少数据移动和查询复杂性来提高查询性能。
先决条件
本文假设你熟悉 SQL 池中的数据分布和数据移动概念。 有关详细信息,请参阅 体系结构 文章。
在设计表的过程中,尽可能多地了解数据以及数据查询方式。 例如,请考虑以下问题:
- 表有多大?
- 表的刷新频率是多少?
- SQL 池中是否包含事实数据表和维度表?
什么是复制表?
复制的表具有每个计算节点上可访问的表的完整副本。 复制表无需在联接或聚合之前在计算节点之间传输数据。 由于表有多个副本,因此当表大小小于 2 GB 压缩时,复制的表效果最佳。 2 GB 不是硬限制。 如果数据是静态的且不会更改,则可以复制更大的表。
下图显示了可在每个计算节点上访问的复制表。 在 SQL 池中,复制的表将被完全复制到每个计算节点上的分布式数据库。

复制的表比较适合星型架构中的维度表。 维度表通常联接到事实数据表,这些表的分布方式与维度表不同。 通常情况下,维度的大小让存储并维护多个副本变得可行。 维度存储缓慢变化的描述性数据,例如客户名称和地址以及产品详细信息。 数据性质缓慢变化导致对复制表的维护需求减少。
请考虑在以下情况下使用复制的表:
- 磁盘上的表大小小于 2 GB,无论有多少行。 若要查找表的大小,可以使用 DBCC PDW_SHOWSPACEUSED 命令:
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate')。 - 表用于不采用复制的表时将要求移动数据的联接中。 当将未在同一列上分布的表(例如哈希分布表)联接到轮询表时,需要执行数据移动以完成查询。 如果其中一个表较小,请考虑复制该表。 大多数情况下,我们建议使用复制的表而非循环表。 若要查看查询计划中的数据移动操作,请使用 sys.dm_pdw_request_steps。 BroadcastMoveOperation 是典型的数据移动操作,可通过使用复制的表来消除。
复制的表在以下情况下可能不会产生最佳查询性能:
- 对表进行频繁的插入、更新和删除操作。 这些数据操作语言 (DML) 操作要求重新生成复制表。 频繁地重新生成会导致性能降低。
- SQL 池会频繁缩放。 缩放 SQL 池会更改计算节点数,这会重新生成复制表。
- 表具有大量列,但数据操作通常仅访问少量的列。 在这种情况下,与复制整个表相比,将表分发,然后对经常访问的列创建索引可能更为高效。 当查询需要进行数据移动时,SQL 池仅移动所请求列中的数据。
小窍门
有关索引和复制表的更多指南,请参阅 Azure Synapse Analytics 中的专用 SQL 池(以前称为 SQL DW)的速查表。
将复制的表与简单的查询谓词一起使用
在选择分发或复制表之前,请考虑计划针对表运行的查询类型。 只要可能,
- 对于具有简单查询谓词(例如等于或不等于)的查询,请使用复制的表。
- 对具有复杂查询谓词(如 LIKE 或 NOT LIKE)的查询使用分布式表。
当工作分布在所有计算节点中时,CPU 密集型查询的性能最佳。 例如,对表的每一行运行计算的查询对分布式表的性能优于复制表。 由于复制表在每个计算节点上完全存储,因此针对复制表的 CPU 密集型查询针对每个计算节点上的整个表运行。 额外的计算可能会降低查询性能。
例如,此查询具有复杂的谓词。 当数据位于分布式表中而不是复制表时,它运行速度更快。 在本例中,数据可以轮流分配。
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
将现有的循环表转换为复制的表
如果已经具有循环表,如果它们满足本文中列出的条件,建议将其转换为复制的表。 与循环表相比,复制的表可以提高性能,因为它们不要求移动数据。 循环表始终要求为联接移动数据。
此示例使用 CTAS 将 DimSalesTerritory 表更改为复制的表。 无论 DimSalesTerritory 是哈希分布式表还是循环表,此示例都是可行的。
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
循环表与复制的表的查询性能对比示例
复制的表不需要联接的任何数据移动,因为整个表已存在于每个计算节点上。 如果维度表是轮循分布的,则联接会将维度表完整复制到每个计算节点。 若要移动数据,查询计划包含一个名为 BroadcastMoveOperation 的操作。 这种类型的数据移动操作会降低查询性能,但可以通过使用复制表来消除这种影响。 若要查看查询计划步骤,请使用 sys.dm_pdw_request_steps 系统目录视图。
例如,在针对 AdventureWorks 架构的以下查询中,FactInternetSales 表是哈希分布式的。
DimDate和DimSalesTerritory表是较小的维度表。 此查询返回 2004 财年北美的总销售额:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
我们已将 DimDate 和 DimSalesTerritory 重新创建为循环表。 因此,查询显示了以下查询计划,该计划具有多个广播移动操作:
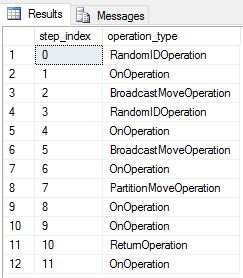
我们将 DimDate 和 DimSalesTerritory 重新创建为复制的表,然后再次运行了查询。 得到的查询计划短了很多,而且没有任何广播移动。
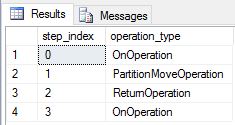
修改复制表的性能注意事项
SQL 池通过维护表的主版本来实现复制表。 它将主版本复制到每个计算节点上的第一个分发数据库。 发生更改时,先更新主版本,然后重新生成每个计算节点上的表。 复制表的重新生成包括将表复制到每个计算节点,然后生成索引。 例如,DW2000c 上的复制表有五个数据副本。 每个计算节点上有一个主副本和一个完整副本。 所有数据都存储在分发数据库中。 SQL 池使用此模型来支持更快的数据修改语句和灵活的缩放操作。
在发生以下情况后,异步重新生成由对复制表的第一次查询触发:
- 加载或修改数据
- Synapse SQL 实例缩放到了其他级别
- 表定义已更新
发生下列情况后,不需要重新生成:
- 暂停操作
- 恢复操作
修改数据后,重新生成不会立即发生。 重新生成将在查询首次从表中选择数据时触发。 触发重新生成的查询将立即从表的主版本读取,同时将数据异步复制到每个计算节点。 在数据复制完成之前,后续查询将继续使用表的主版本。 如果针对强制重新生成复制的表发生任何活动,数据复制将失效,下一个 select 语句将触发再次复制数据。
保守地使用索引
标准索引做法适用于复制的表。 SQL 池在重新生成过程中重新生成每个复制的表索引。 仅当性能提升超过重新生成索引的成本时,才使用索引。
批处理数据加载
将数据加载到复制表中时,通过批量加载尽量减少重新构建。 在运行 select 语句之前执行所有批处理加载。
例如,此加载模式从四个源加载数据,并执行四次重建。
- 从源 1 进行加载。
- Select 语句触发重新生成 1。
- 从源 2 进行加载。
- Select 语句触发重新生成 2。
- 从源 3 进行加载。
- Select 语句触发重新生成 3。
- 从源 4 进行加载。
- Select 语句触发重新生成 4。
例如,此加载模式从四个源加载数据,但只调用一个重新生成。
- 从源 1 进行加载。
- 从源 2 进行加载。
- 从源 3 进行加载。
- 从源 4 进行加载。
- Select 语句触发重新生成。
在批处理加载后重新生成复制的表
若要确保查询执行时间一致,请考虑在批处理加载后强制生成复制表。 否则,第一个查询仍将使用数据传输来完成查询。
“生成复制表缓存”操作最多可同时执行两个操作。 例如,如果尝试为五个表重新生成缓存,系统将利用 staticrc20(无法修改)同时生成两个表。 因此,建议避免使用超过 2 GB 的大型复制表,因为这可能会降低跨节点的缓存重新生成速度并增加总时间。
此查询使用 sys.pdw_replicated_table_cache_state DMV 列出已修改但未重新生成的复制表。
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
若要触发重新生成,请在前面的输出中的每个表上运行以下语句。
SELECT TOP 1 * FROM [ReplicatedTable]
注释
如果计划重新生成未缓存复制表的统计信息,请确保在触发缓存之前更新统计信息。 更新统计信息会使缓存失效,因此序列非常重要。
示例:从 UPDATE STATISTICS 开始,然后触发缓存的重新生成。 在以下示例中,正确的示例更新统计信息,然后触发缓存的重新生成。
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
若要监视重新生成过程,可以使用 sys.dm_pdw_exec_requests,其中 command 将以“BuildReplicatedTableCache”开头。 例如:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
小窍门
表大小查询 可用于验证哪些表具有复制的分发策略,并且其大小大于 2 GB。
后续步骤
若要创建复制的表,请使用以下语句之一:
有关分布式表的概述,请参阅 分布式表。