Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
如果你有关键应用程序和业务流程依赖于 Azure 资源,则需要监视这些资源的可用性和性能。
本文介绍 Azure 虚拟 WAN 生成的监视数据。 虚拟 WAN 使用 Azure Monitor。 如果你不熟悉所有 Azure 服务普遍使用的 Azure Monitor 功能,请参阅使用 Azure Monitor 监视 Azure 资源。
先决条件
你已部署并配置了虚拟 WAN。 有关部署虚拟 WAN 的帮助:
分析指标
Azure Monitor 中的指标是数字值,用于描述系统某些方面在特定时间的情况。 指标每分钟收集一次,可用于警报,因为可对其频繁采样。 可以使用相对简单的逻辑快速激发警报。
有关为虚拟 WAN 收集的平台指标列表,请参阅监视虚拟 WAN 数据参考指标。
查看虚拟 WAN 的指标
以下步骤可帮助你查找和查看指标:
在门户中,导航到虚拟中心。
选择“VPN (站点到站点)”以查找站点到站点网关,选择“ExpressRoute”以查找 ExpressRoute 网关,或选择“用户 VPN (点到站点)”以查找点到站点网关。
选择“指标”。
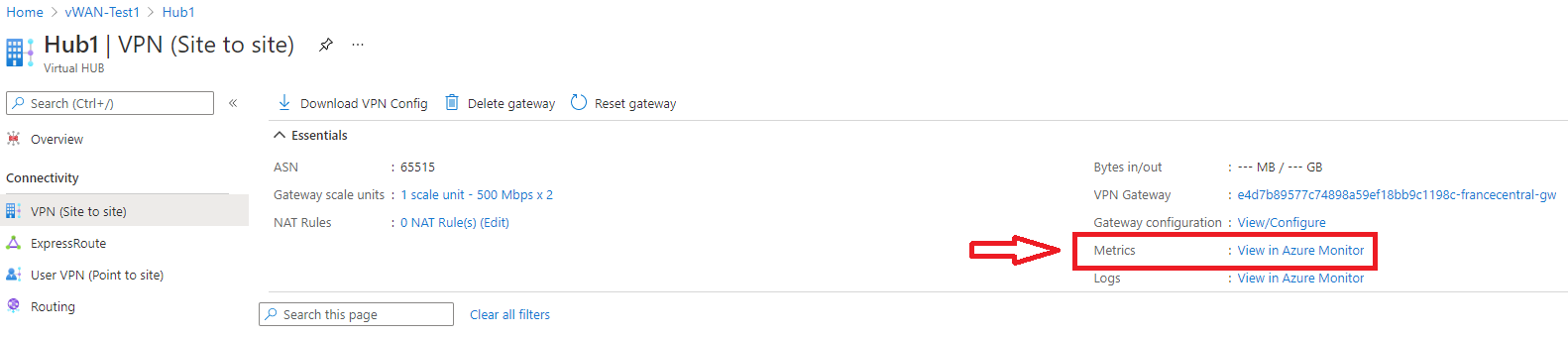
在“指标”页上,你可以查看感兴趣的指标。
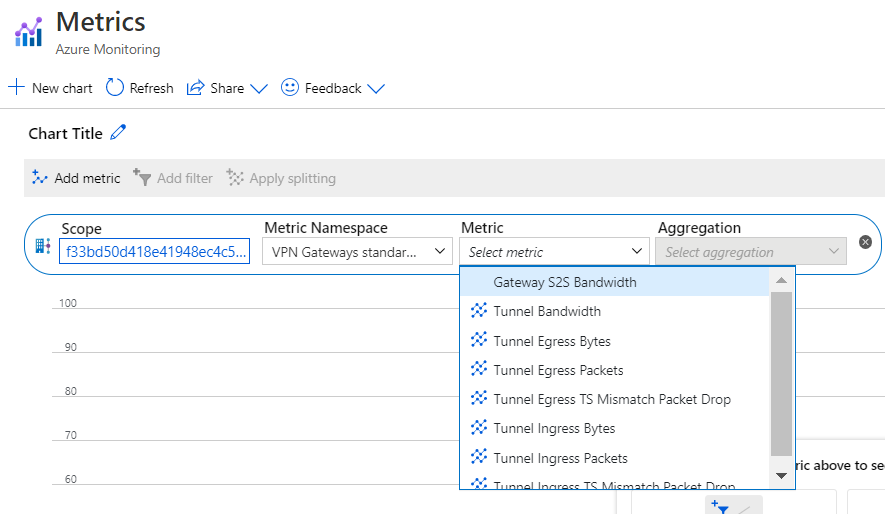
若要查看虚拟中心路由器的指标,可以从虚拟中心“概述”页中选择“指标”。


PowerShell 步骤
可以使用 PowerShell 查看虚拟 WAN 的指标。 若要进行查询,请使用以下示例 PowerShell 命令。
$MetricInformation = Get-AzMetric -ResourceId "/subscriptions/<SubscriptionID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Network/VirtualHubs/<VirtualHubName>" -MetricName "VirtualHubDataProcessed" -TimeGrain 00:05:00 -StartTime 2022-2-20T01:00:00Z -EndTime 2022-2-20T01:30:00Z -AggregationType Sum
$MetricInformation.Data
- 资源 ID。 可在 Azure 门户找到虚拟中心的资源 ID。 导航到 vWAN 中的“虚拟中心”页,然后选择“基本信息”下的“JSON 视图”。
-
指标名称。 指要查询的指标的名称,在本例中称为
VirtualHubDataProcessed。 此指标显示虚拟中心路由器在中心的选定时间段处理的所有数据。 - 时间粒度。 指想要查看聚合的频率。 在当前命令中,每 5 分钟会看到一个选定的聚合单元。 可以选择 - 5 分钟/15 分钟/30 分钟/1 小时/6 小时/12 小时和 1 天。
- 开始时间和结束时间。 这时间是基于 UTC 的。 请确保在输入这些参数时输入 UTC 值。 如果未使用这些参数,则默认显示过去一小时的数据。
- 总和聚合类型。 此总和聚合类型显示所选时间段内遍历虚拟中心路由器的字节总数。 例如,如果时间粒度设置为 5 分钟,则每个数据点将对应于 5 分钟时间间隔内发送的字节数。 若要将此值转换为 Gbps,可以将此数字除以 37500000000。 根据虚拟中心的容量,中心路由器可支持 3 Gbps 至 50 Gbps。 此时“最大值”和“最小值”聚合类型没有意义。
分析日志
Azure Monitor 日志中的数据以表形式存储,每个表具有自己独有的属性集。 在创建诊断设置并将其路由到一个或多个位置之前,不会收集和存储资源日志。
有关虚拟 WAN 中支持的日志的列表,请参阅监视虚拟 WAN 数据参考日志。 Azure Monitor 中的所有资源日志都具有后跟服务特定字段的相同字段。 Azure Monitor 资源日志架构概述了常见架构。
创建用于查看日志的诊断设置
以下步骤可帮助你创建、编辑和查看诊断设置:
在门户中,导航到虚拟 WAN 资源,然后在“连接”组中选择“中心”。
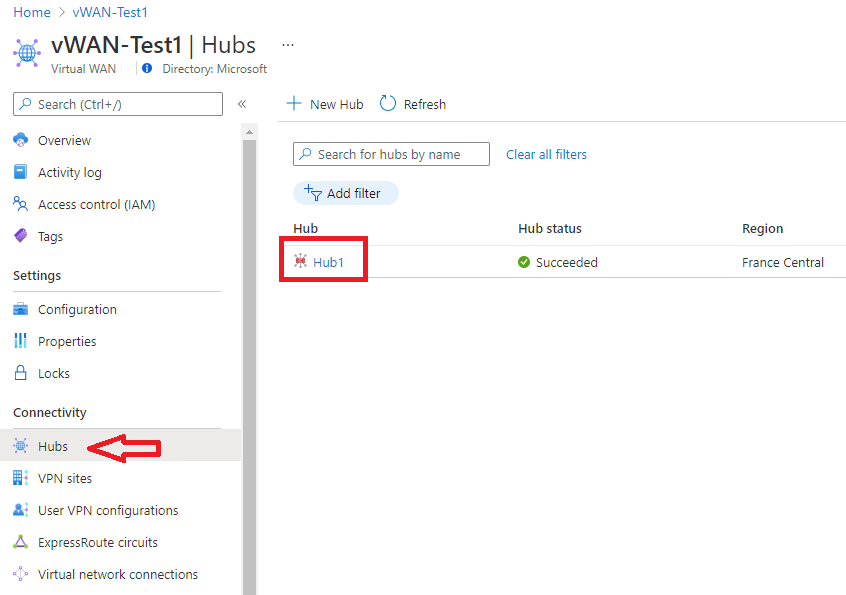
在左侧的“连接性”组下,选择要检查其诊断的网关:
在页面右侧,选择“监视网关”,然后单击“日志”。
在此页中,可以创建新的诊断设置(“+ 添加诊断设置”)或编辑现有诊断设置(“编辑设置”)。 可以选择将诊断日志发送到 Log Analytics(如以下示例所示)、流式传输到事件中心、发送到第 3 方解决方案或存档到存储帐户。
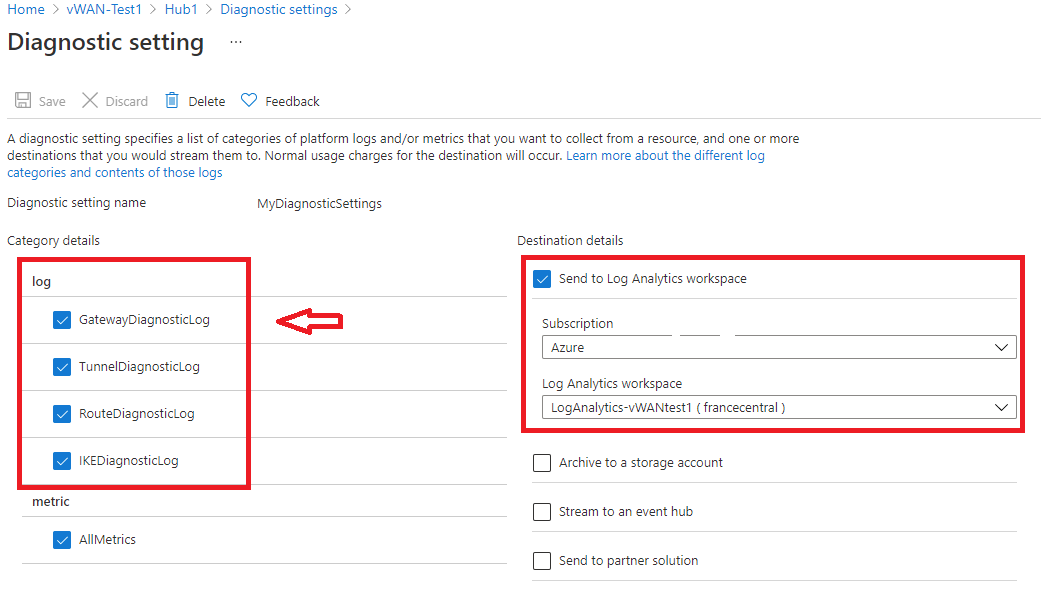
单击“保存”后,应该会在几个小时内开始看到日志出现在此 Log Analytics 工作区中。
若要监视安全中心(使用 Azure 防火墙),则必须通过访问“诊断设置”选项卡完成诊断和日志记录配置:
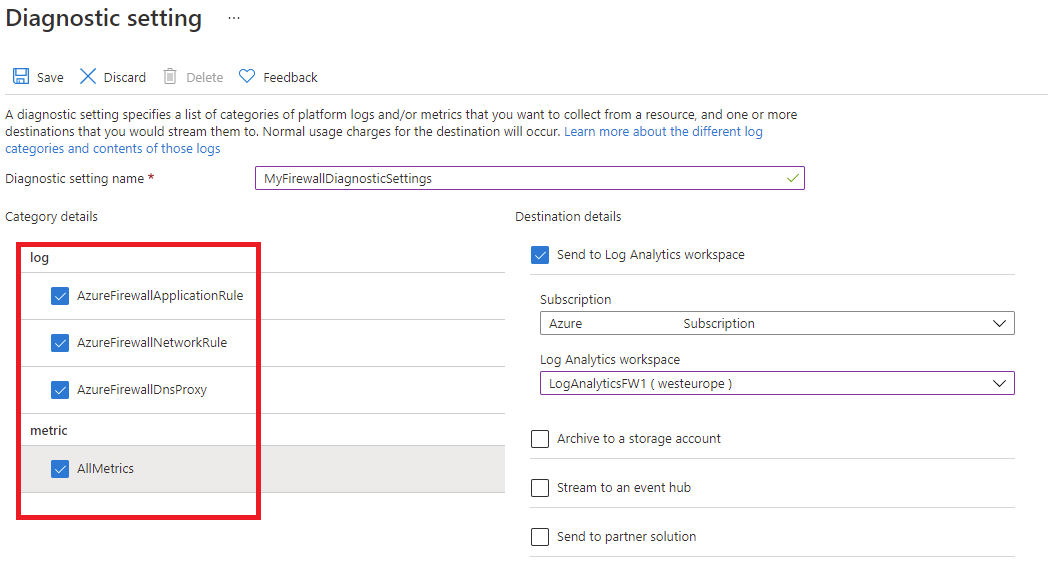



重要
启用这些设置需要额外的 Azure 服务(存储帐户、事件中心或 Log Analytics),这可能会增加成本。 若要估算成本,请访问 Azure 定价计算器。
警报
在监视数据中发现重要情况时,Azure Monitor 警报会主动通知你。 有了警报,你就可以在客户注意到你的系统中的问题之前确定和解决它们。 可以在指标、日志和活动日志上设置警报。 不同类型的警报各有优缺点。
虚拟 WAN 见解
Azure 中的某些服务在 Azure 门户中有一个特殊且醒目的预生成仪表板,提供监视你的服务的入手点。 这些特殊仪表板称为“见解”。
虚拟 WAN 使用 Azure Monitor 见解使用户和操作员能够查看通过自动发现的拓扑映射显示的虚拟 WAN 的状态。 资源状态在映射上的覆盖为你提供了虚拟 WAN 整体运行状况的快照视图。 可以通过对虚拟 WAN 门户资源配置页的一键式访问,在映射上导航资源。 有关详细信息,请查看虚拟 WAN 的 Azure Monitor 网络见解。
相关内容
- 有关为虚拟 WAN 创建的指标、日志和其他重要值的参考信息,请参阅 Azure 虚拟 WAN 监视数据参考。
- 有关监视 Azure 资源的一般详细信息,请参阅使用 Azure Monitor 监视 Azure 资源。