Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
本文提供了用于配置和管理 Azure SQL 数据库超大规模命名副本的示例。
创建名为 Hyperscale 的副本
以下示例方案指导你使用 Azure 门户、T-SQL、PowerShell 或 Azure CLI 为数据库 WideWorldImporters_NamedReplica 创建命名副本 WideWorldImporters。
以下示例在 Azure 门户中创建一个命名为 Hyperscale 的新副本。
转到 Azure SQL hub。
在资源菜单中,展开 Azure SQL 数据库 并选择 SQL 数据库。
在 “SQL 数据库 ”页上,选择要为其创建命名副本的现有“超大规模”数据库。
在资源菜单中的 “数据管理”下,选择“ 副本”,然后选择“ 创建副本”。
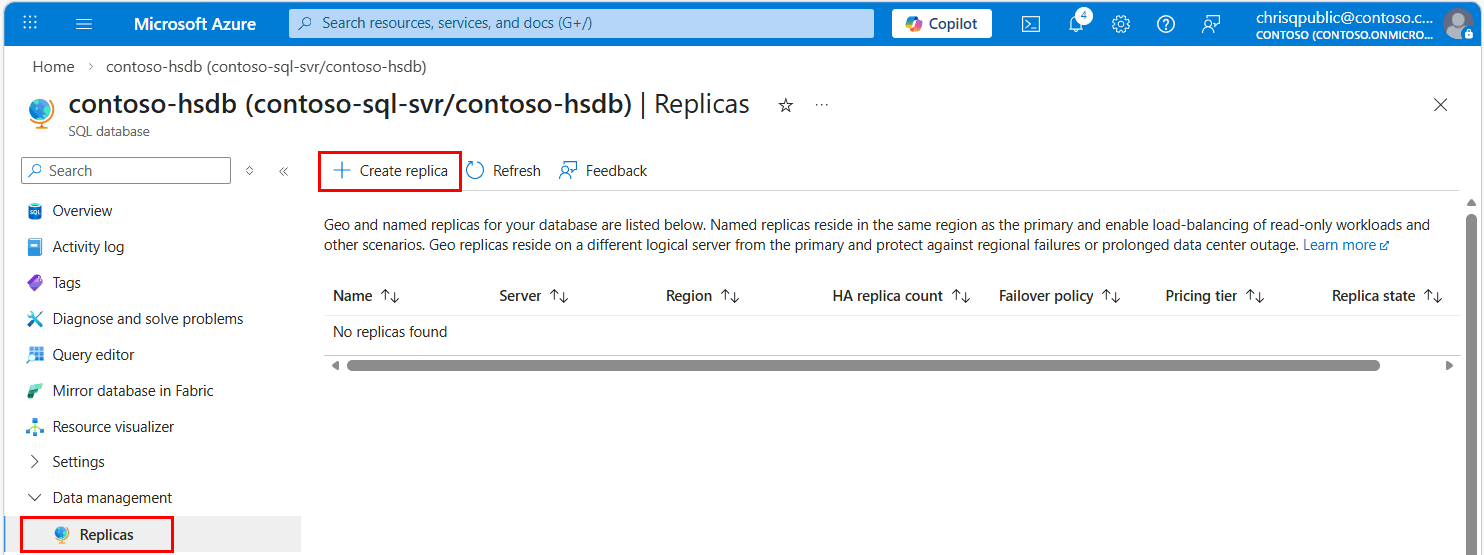
在副本配置下选择命名副本。 选择现有的服务器,或为命名副本创建新服务器。 输入命名副本数据库名称,并在必要时配置“计算 + 存储”选项。
(可选)配置区域冗余超大规模命名副本。 有关详细信息,请参阅 Azure SQL 数据库超大规模命名副本中的区域冗余。
- 在“配置数据库”页面中,选择“是”作为“是否要使此数据库区域成为冗余?”
- 将至少一个高可用性次要副本添加到你的配置。
- 选择“应用”。
选择“查看 + 创建”查看信息,然后选择“创建”。
命名副本部署过程开始。
部署完成后,命名的副本会显示其状态。
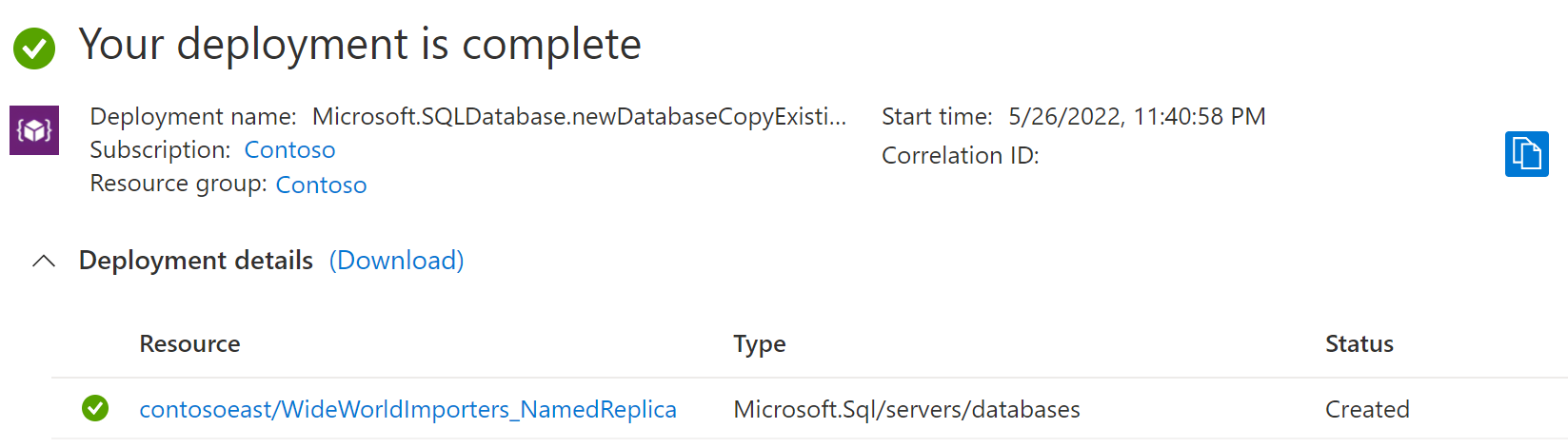
返回主数据库页,然后选择“副本”。 你的命名副本会在命名副本下列出。
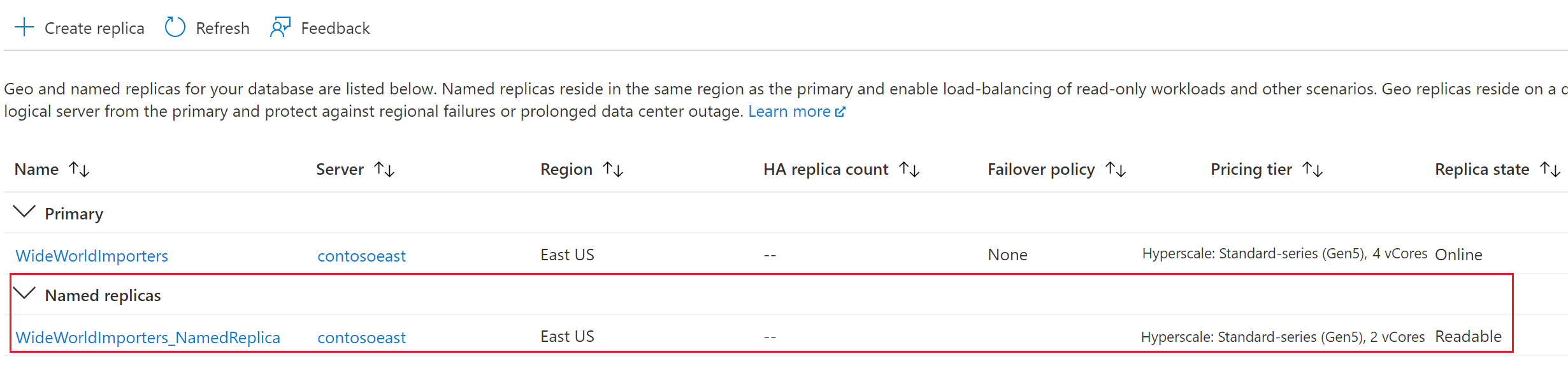





由于不涉及移动数据,因此在大多数情况下,大约只需一分钟就能创建一个命名副本。 创建命名副本后,可以通过 Azure 门户或任何命令行工具(例如 AZ CLI 或 PowerShell)查看它。 命名副本可用作普通只读数据库。
连接到超大规模命名副本
若要连接到某个超大规模命名副本,必须使用该命名副本的连接字符串,引用其服务器和数据库名称。 由于命名副本始终是只读的,因此无需指定选项 ApplicationIntent=ReadOnly。
与 HA 副本一样,即使主要副本、HA 副本和命名副本共享同一组页面服务器上的相同数据,每个命名副本上的数据缓存也仍会与主要副本保持同步。 同步由事务日志服务维护,该服务将日志记录从主副本转发到命名副本。 因此,根据命名副本所处理的工作负载,应用程序日志记录的速度可能各不相同,因而不同的命名副本相对于主要副本而言可能会出现不同的数据延迟。
修改 Hyperscale 命名的复制对象
在创建命名副本时,可以通过 ALTER DATABASE 命令或任何其他受支持的方式(门户、AZ CLI、PowerShell)定义该命名副本的服务级别目标。 如果在创建命名副本后需要更改其服务级别目标,则可以对命名副本本身使用 ALTER DATABASE ... MODIFY 命令。
在以下示例中,WideWorldImporters_NamedReplica 是 WideWorldImporters 数据库的命名副本。
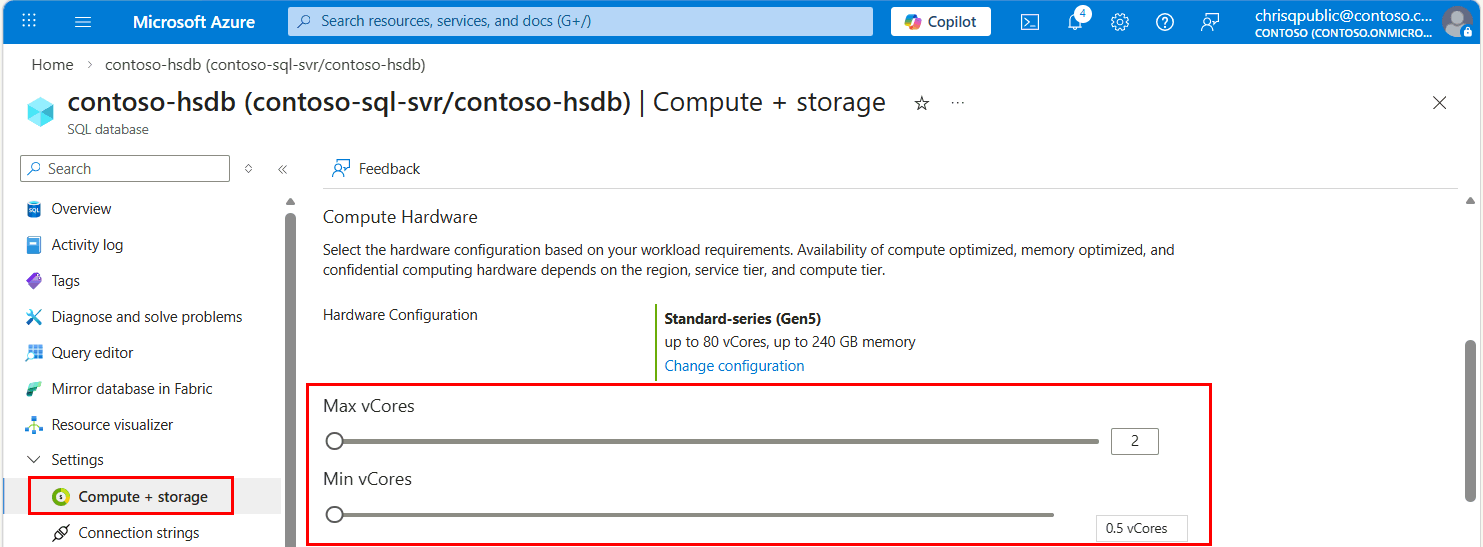
打开已命名的副本数据库页面。
在资源菜单中的 “设置”下,选择“ 计算 + 存储”。
根据需要更新 vCore 设置。

删除指定的超大规模副本
要删除超大规模命名副本,可像删除普通数据库那样删除。
打开命名副本数据库页,然后选择“Delete”选项。

重要
删除用于创建命名副本的主要副本时,这些命名副本也会一并删除。
优化命名副本配置
建议使用与主副本相同的计算规模(vCores)配置命名副本。 如果主副本遇到大量写入工作负荷,则计算大小较低的命名副本可能无法跟上,从而导致复制滞后。 为了保持可恢复性 SLA,可以暂时减少主数据库的事务日志速率,以允许其辅助数据库赶上。
如果选择创建计算大小(vCores)与主数据库不同的命名副本,应随着时间的推移监视主数据库上的日志 IO 速率。 这有助于估计命名副本维持复制负载所需的最小计算大小。 有关详细信息,请考虑以下对象:
- sys.dm_hs_database_log_rate() 动态管理功能(DMF)提供了其他详细信息,以帮助了解日志速率降低(如果有)。 它可以指示哪些特定的次要副本在应用日志记录方面落后,以及未应用的事务日志总大小。
- 若要检索历史日志 IO 数据,请使用 sys.resource_stats 视图。
- 对于具有更高粒度的最新日志 IO 数据,可更好地反映短期峰值,请使用 sys.dm_db_resource_stats。
有关详细信息,请参阅 Azure SQL 数据库超大规模性能诊断。