Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
了解使用 Azure Batch JavaScript SDK 生成 Batch 客户端的基础知识。 我们将循序渐进地了解一个批处理应用程序的方案,然后使用 JavaScript 设置该方案。
先决条件
本文假设你有 JavaScript 的实践知识并熟悉 Linux, 它还假设你拥有一个具有创建 Batch 和存储服务的访问权限的Azure帐户设置。
建议先阅读 Azure Batch Technical Overview,然后再阅读本文所述的步骤。
了解方案
此处,我们编写了一个以 Python 编写的简单脚本,该脚本从 Azure Blob 存储容器下载所有 csv 文件,并将其转换为 JSON。 若要并行处理多个存储帐户容器,我们可以将脚本部署为Azure Batch作业。
Azure Batch体系结构
下图描述了如何使用 Azure Batch 和客户端缩放Python脚本。
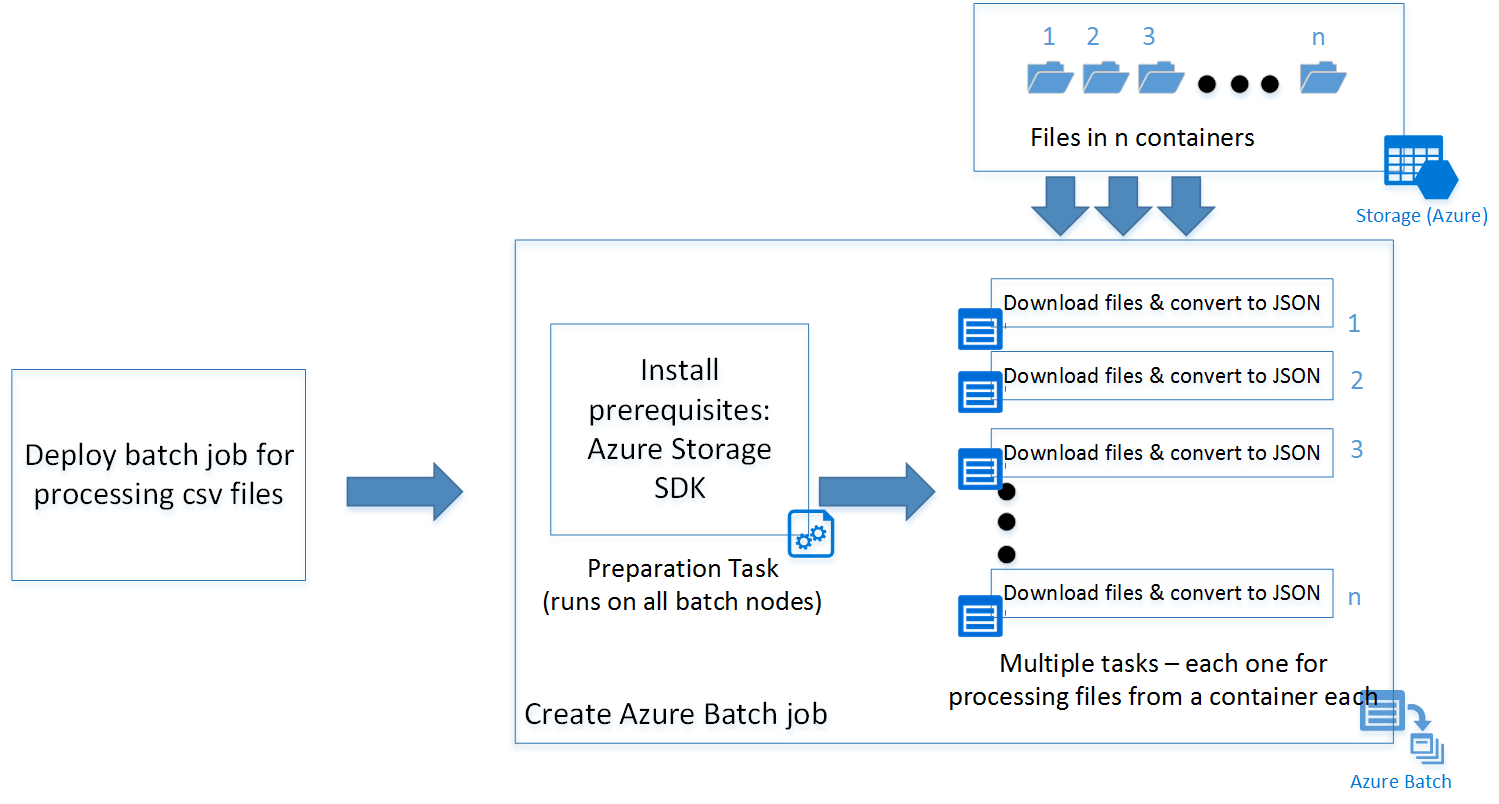
JavaScript 示例使用一个准备任务(稍后将详细介绍),并根据存储帐户中的容器数使用其他一组任务来部署批处理作业。 可以从GitHub存储库下载脚本。
生成应用程序
现在,让我们按照过程逐步生成 JavaScript 客户端:
步骤 1:安装 Azure Batch SDK
可以使用 npm install 命令安装 Azure Batch SDK for JavaScript。 还需要 @azure/identity 包才能使用 Microsoft Entra ID 进行身份验证。
npm install @azure/batch @azure/identity
此命令将安装最新版本的 Azure Batch JavaScript SDK 以及Azure标识库。
小窍门
在Azure函数应用中,可以在Azure函数的“设置”选项卡中转到“Kudu 控制台”,运行 npm 安装命令。 在本例中,安装适用于 JavaScript 的 Azure Batch SDK。
步骤 2:创建Azure Batch帐户
可以从 Azure 门户或命令行(PowerShell /Azure CLI)创建它。
下面是通过Azure CLI创建一个命令。
创建一个资源组。如果你已经有一个需要在其中创建 Batch 帐户的资源组,则请跳过此步骤:
az group create -n "<resource-group-name>" -l "<location>"
接下来,创建Azure Batch帐户。
az batch account create -l "<location>" -g "<resource-group-name>" -n "<batch-account-name>"
此示例不使用帐户访问密钥,而是使用 DefaultAzureCredential 通过Microsoft Entra ID进行身份验证。 确保在 Batch 帐户上为运行代码的标识(开发人员登录、托管标识或服务主体)分配了适当的Azure RBAC 角色,例如 Azure Batch 数据参与者或Azure Batch数据读取者。 有关详细信息,请参阅 使用 Microsoft Entra ID 验证 Batch 服务解决方案。
在本地运行时,DefaultAzureCredential可以从Azure CLI(az login)、Azure PowerShell、Visual Studio Code或环境变量中选取凭据。 在Azure托管的环境(如Azure Functions或Azure VM)中,可以使用托管标识。
步骤 3:创建Azure Batch服务客户端
以下代码片段导入 @azure/batch 和 @azure/identity 模块,然后使用 BatchClient 创建一个 DefaultAzureCredential。
// Initializing Azure Batch variables
import { DefaultAzureCredential } from "@azure/identity";
import { BatchClient } from "@azure/batch";
// Replace value below with your Batch account URL
const batchEndpoint = '<batch-account-url>';
const credentials = new DefaultAzureCredential();
const batchClient = new BatchClient(batchEndpoint, credentials);
可以在Azure门户的“概述”选项卡中找到Azure Batch URI。 它的格式为:
https://accountname.location.batch.chinacloudapi.cn
请参阅屏幕截图:
步骤 4:创建Azure Batch池
Azure Batch池由多个 VM(也称为 Batch 节点)组成。 Azure Batch服务在这些节点上部署任务并对其进行管理。 可以为池定义以下配置参数。
- 虚拟机映像类型
- 虚拟机节点大小
- 虚拟机节点数目
小窍门
虚拟机节点的大小和数目主要取决于需要并行运行的任务数以及任务本身。 建议通过测试来确定理想的数目和大小。
以下代码片段创建配置参数对象。
// Creating Image reference configuration for Ubuntu Linux VM
const imgRef = {
publisher: "Canonical",
offer: "UbuntuServer",
sku: "20.04-LTS",
version: "latest"
}
// Creating the VM configuration object with the SKUID
const vmConfig = {
imageReference: imgRef,
nodeAgentSkuId: "batch.node.ubuntu 20.04"
};
// Number of VMs to create in a pool
const numVms = 4;
// Setting the VM size
const vmSize = "STANDARD_D1_V2";
小窍门
有关可用于Azure Batch及其 SKU ID 的 Linux VM 映像列表,请参阅虚拟机映像列表。
定义池配置后,即可创建 Azure Batch 池。 Batch 池命令创建 Azure 虚拟机节点,并将其准备好以接收和执行任务。 每个池都应有一个可在后续步骤中引用的唯一 ID。
以下代码片段创建Azure Batch池。
// Create a unique Azure Batch pool ID
const now = new Date();
const poolId = `processcsv_${now.getFullYear()}${now.getMonth()}${now.getDay()}${now.getHours()}${now.getSeconds()}`;
const poolConfig = {
id: poolId,
displayName: "Processing csv files",
vmSize: vmSize,
virtualMachineConfiguration: vmConfig,
targetDedicatedNodes: numVms,
enableAutoScale: false
};
// Creating the Pool
try {
await batchClient.createPool(poolConfig);
} catch (error) {
console.log(error);
}
你可以检查所创建池的状态,确保状态为“活动”,然后再继续操作,将作业提交到该池。
try {
const cloudPool = await batchClient.getPool(poolId);
if (cloudPool.state === "active") {
console.log("Pool is active");
}
} catch (error) {
if (error.statusCode === 404) {
console.log("Pool not found yet returned 404...");
} else {
console.log("Error occurred while retrieving pool data");
}
}
下面是由 pool.get 函数返回的结果对象示例。
{
id: 'processcsv_2022002321',
displayName: 'Processing csv files',
url: 'https://<batch-account-name>.chinanorth.batch.chinacloudapi.cn/pools/processcsv_2022002321',
eTag: '0x8D9D4088BC56FA1',
lastModified: 2022-01-10T07:12:21.943Z,
creationTime: 2022-01-10T07:12:21.943Z,
state: 'active',
stateTransitionTime: 2022-01-10T07:12:21.943Z,
allocationState: 'steady',
allocationStateTransitionTime: 2022-01-10T07:13:35.103Z,
vmSize: 'standard_d1_v2',
virtualMachineConfiguration: {
imageReference: {
publisher: 'Canonical',
offer: 'UbuntuServer',
sku: '20.04-LTS',
version: 'latest'
},
nodeAgentSKUId: 'batch.node.ubuntu 20.04'
},
resizeTimeout: 'PT15M',
currentDedicatedNodes: 4,
currentLowPriorityNodes: 0,
targetDedicatedNodes: 4,
targetLowPriorityNodes: 0,
enableAutoScale: false,
enableInterNodeCommunication: false,
taskSlotsPerNode: 1,
taskSchedulingPolicy: { nodeFillType: 'Spread' }}
步骤 4:提交Azure Batch作业
Azure Batch 作业是由类似任务构成的逻辑单元。 在我们的方案中,它是“将 csv 处理为 JSON”。此处的每个任务都可以处理每个Azure 存储容器中存在的 csv 文件。
这些任务将并行运行,并跨多个节点部署,由Azure Batch服务协调。
小窍门
可以使用 taskSlotsPerNode 属性指定可在单个节点上并发运行的最大任务数。
准备任务
所创建的 VM 节点是空白 Ubuntu 节点。 通常需安装一组程序作为必备组件。 对于 Linux 节点,通常可在实际任务运行之前使用 shell 脚本安装必备组件。 不过,也可通过任何可编程的可执行文件来完成该操作。
此示例中的 shell 脚本安装 Python-pip 和 Azure 存储 Blob SDK for Python。
可以在Azure 存储帐户上上传脚本,并生成用于访问脚本的 SAS URI。 也可以使用 Azure 存储 JavaScript SDK 自动执行此过程。
小窍门
作业的准备任务仅在需要运行特定任务的 VM 节点上运行。 如果要在所有节点上安装必备组件,而不考虑其上运行的任务,则可以在添加池时使用 startTask 属性。 可以使用以下准备任务定义作为参考。
在提交 Azure Batch 作业时,会指定一个准备任务。 下面是一些可配置的准备任务参数:
- ID:准备任务的唯一标识符
- commandLine:用于执行任务可执行文件的命令行
-
resourceFiles:提供下载此任务运行所需的文件详细信息的对象数组。 下面是其选项
- httpUrl:要下载的文件的 URL
- filePath:下载并保存文件所需的本地路径
- fileMode:仅适用于 Linux 节点。fileMode 采用八进制格式,默认值为 0770
- waitForSuccess:如果设置为 true,则任务不会在准备任务失败时运行
- runElevated:如果需要提升的权限来运行任务,则将其设置为 true。
以下代码片段显示了准备任务脚本配置示例:
const jobPrepTaskConfig = {
id: "installprereq",
commandLine: "sudo sh startup_prereq.sh > startup.log",
resourceFiles: [{ httpUrl: 'Blob sh url', filePath: 'startup_prereq.sh' }],
waitForSuccess: true,
userIdentity: { autoUser: { elevationLevel: "admin", scope: "pool" } }
};
如果不需安装任何必备组件即可运行任务,则可跳过准备任务。 以下代码创建显示名称为“process csv files”的作业。
// Setting Batch Pool ID
const poolInfo = { poolId: poolId };
// Batch job configuration object
const jobId = "processcsvjob";
const jobConfig = {
id: jobId,
displayName: "process csv files",
jobPreparationTask: jobPrepTaskConfig,
poolInfo: poolInfo
};
// Adding Azure batch job to the pool
try {
await batchClient.createJob(jobConfig);
} catch (error) {
console.log("An error occurred while creating the job...");
console.log(error);
}
步骤 5:为作业提交 Azure Batch 任务
创建“process csv”作业以后,让我们创建该作业的任务。 假设我们有四个容器,则必须创建四个任务,一个容器一个任务。
如果查看 Python 脚本,则它接受两个参数:
- container name:要从其中下载文件的存储容器
- pattern:文件名称模式的可选参数
假设我们有四个容器“con1”、“con2”、“con3”、“con4”,以下代码显示将四个任务提交到之前创建的Azure批处理作业“process csv”。
// storing container names in an array
const containerList = ["con1", "con2", "con3", "con4"]; //Replace with list of blob containers within storage account
for (const val of containerList) {
console.log("Submitting task for container : " + val);
const containerName = val;
const taskID = containerName + "_process";
// Task configuration object
const taskConfig = {
id: taskID,
displayName: 'process csv in ' + containerName,
commandLine: 'python processcsv.py --container ' + containerName,
resourceFiles: [{ httpUrl: 'Blob script url', filePath: 'processcsv.py' }]
};
try {
await batchClient.createTask(jobId, taskConfig);
console.log("Task for container : " + containerName + " submitted successfully");
} catch (error) {
console.log("Error occurred while creating task for container " + containerName + ". Details : " + error);
}
}
该代码将多个任务添加到池。 每个任务在所创建的 VM 池中的一个节点上执行。 如果任务数超出池中的 VM 数或 taskSlotsPerNode 属性,则任务会等待节点可用。 此协调由 Azure Batch 自动处理。
门户提供了有关任务和作业状态的详细视图。 还可以使用列表并在 Azure JavaScript SDK 中获取函数。 文档 链接中提供了详细信息。
后续步骤
- 了解 Batch 服务工作流和主要资源,例如池、节点、作业和任务。
- 请参阅 Batch JavaScript 参考 ,了解 Batch API。