Azure 机器学习允许实现批处理终结点和部署,以使用机器学习模型和管道执行长时间运行的异步推理。 在训练机器学习模型或管道时,需要对其进行部署,以便其他人可以将其与新的输入数据一起使用来生成预测。 使用模型或管道生成预测的过程称为 推理。
批处理终结点接收指向数据的指针并以异步方式运行作业,以在计算群集上并行处理数据。 批处理终结点将输出存储到数据存储供进一步分析。 在以下情况下使用批处理终结点:
- 你具有需要较长时间才能运行的昂贵模型或管道。
- 你想要操作机器学习管道并重复使用组件。
- 你需要对大量数据执行推理,这些数据分布在多个文件中。
- 没有低延迟要求。
- 你的模型的输入存储在存储帐户或 Azure 机器学习数据资产中。
- 可以利用并行化。
批量部署
部署是实现终结点提供的功能所需的一组资源和计算。 终结点可以托管多个部署,每个部署都有自己的配置,将终结点接口与部署实现详细信息分离。 调用批处理终结点时,它会自动将客户端路由到其默认部署。 可以随时配置和更改此默认部署。

模型部署
模型部署可实现大规模模型推理的操作化,使你能够以低延迟和异步方式处理大量数据。 Azure 机器学习通过跨计算群集中的多个节点提供推理过程的并行化,从而可以自动检测可伸缩性。
在以下情况下使用 模型部署 :
- 你有昂贵的模型,需要更长的时间运行推理。
- 你需要对大量数据执行推理,这些数据分布在多个文件中。
- 没有低延迟要求。
- 可以利用并行化。
模型部署的主要优势是,可以使用为联机终结点进行实时推理而部署的相同资产,但现在你可以批量运行它们。 如果模型需要简单的预处理或后期处理,则可以创作执行所需数据转换的 评分脚本 。
若要在批处理终结点中创建模型部署,需要指定以下元素:
- Model
- 计算群集
- 评分脚本(对于 MLflow 模型是可选项)
- 环境(对于 MLflow 模型是可选项)
成本管理
调用批处理终结点会触发异步批量推理作业。 Azure 机器学习在作业开始时自动预配计算资源,并在作业完成时自动解除分配计算资源。 因此,你只需在使用计算资源时付费。
小窍门
部署模型时,对于每个批量推理作业,可以替代计算资源设置(例如实例计数)和高级设置(例如最小批大小、错误阈值等)。 利用这些特定配置,可以加快执行速度并降低成本。
批处理终结点也可以在低优先级 VM 上运行。 批处理终结点可以从解除分配的 VM 中自动恢复,并在部署用于推理的模型时从原来的位置恢复工作。 有关如何使用低优先级 VM 来降低批量推理工作负荷的成本的详细信息,请参阅 在批处理终结点中使用低优先级 VM。
最后,Azure 机器学习本身不收取批处理终结点或批处理部署的费用,因此你可以按照最适合自己方案的方式来组织终结点和部署。 端点和部署可以使用独立群集或共享群集,因此可以对作业消耗的计算资源进行精细控制。 在群集中使用scale-to-zero,以确保在闲置时不消耗资源。
简化 MLOps 实践
批处理终结点可以处理同一终结点下的多个部署,从而支持你更改终结点的实现,而无需更改使用者用于调用终结点的 URL。
无需影响终结点本身,即可添加、删除和更新部署。
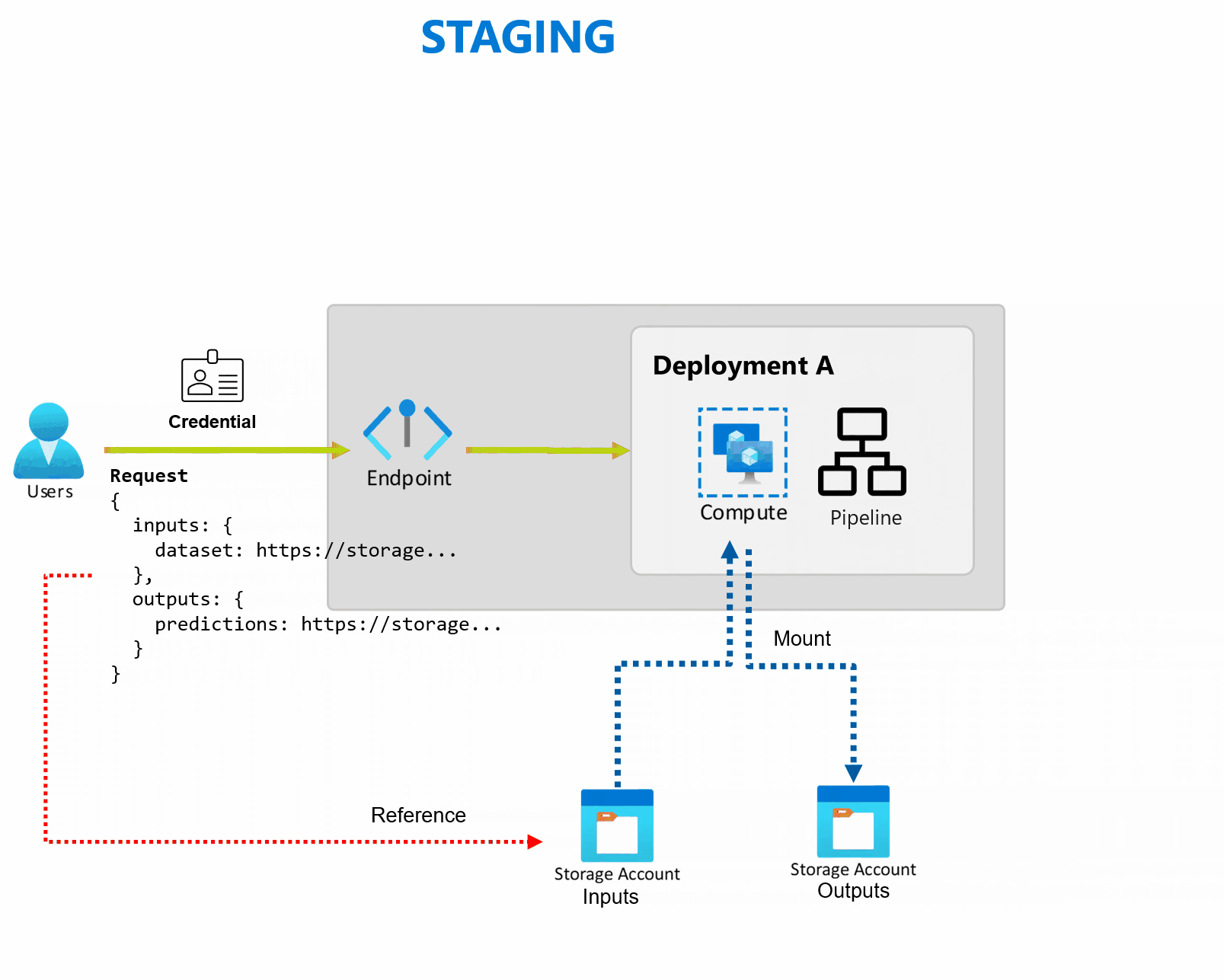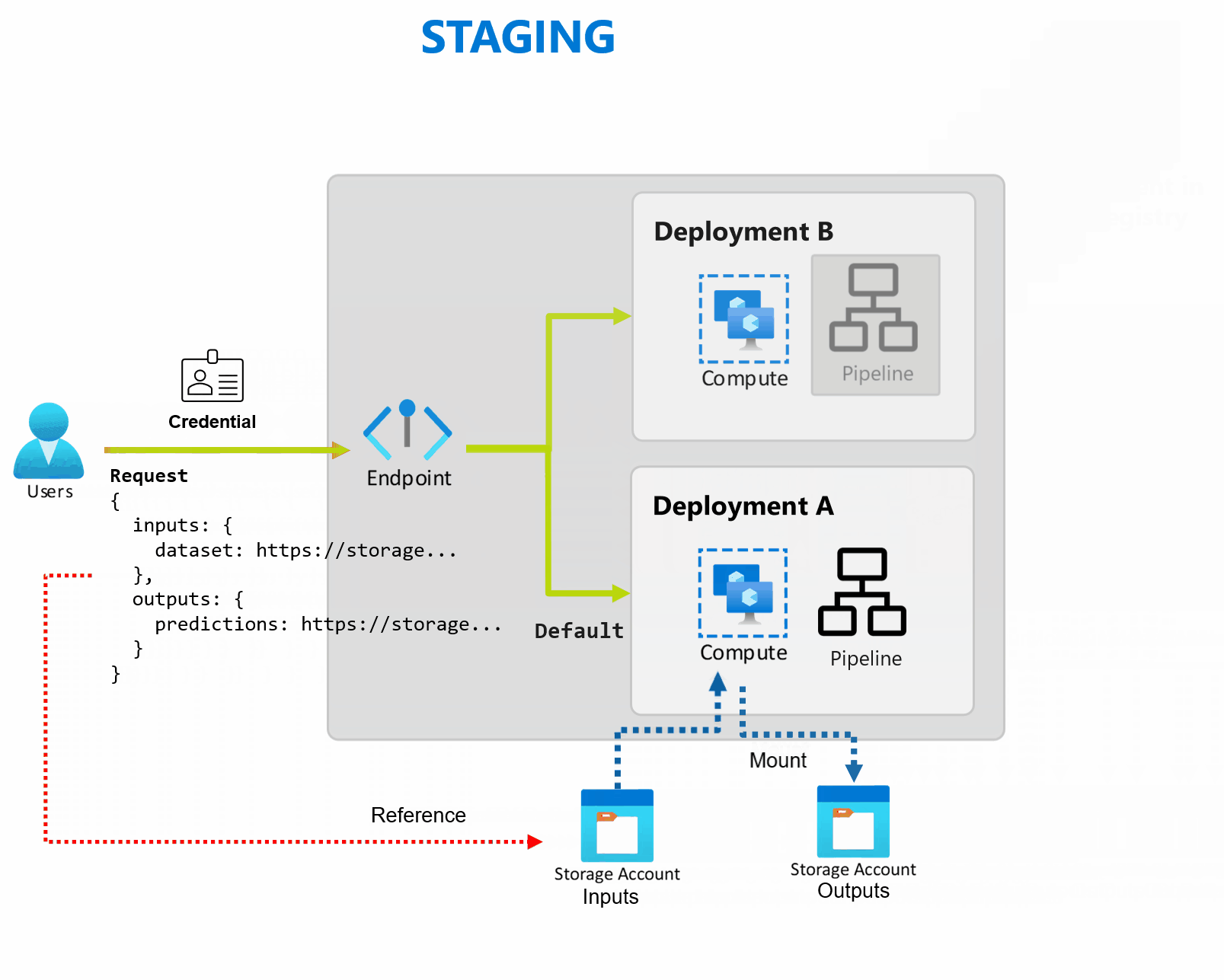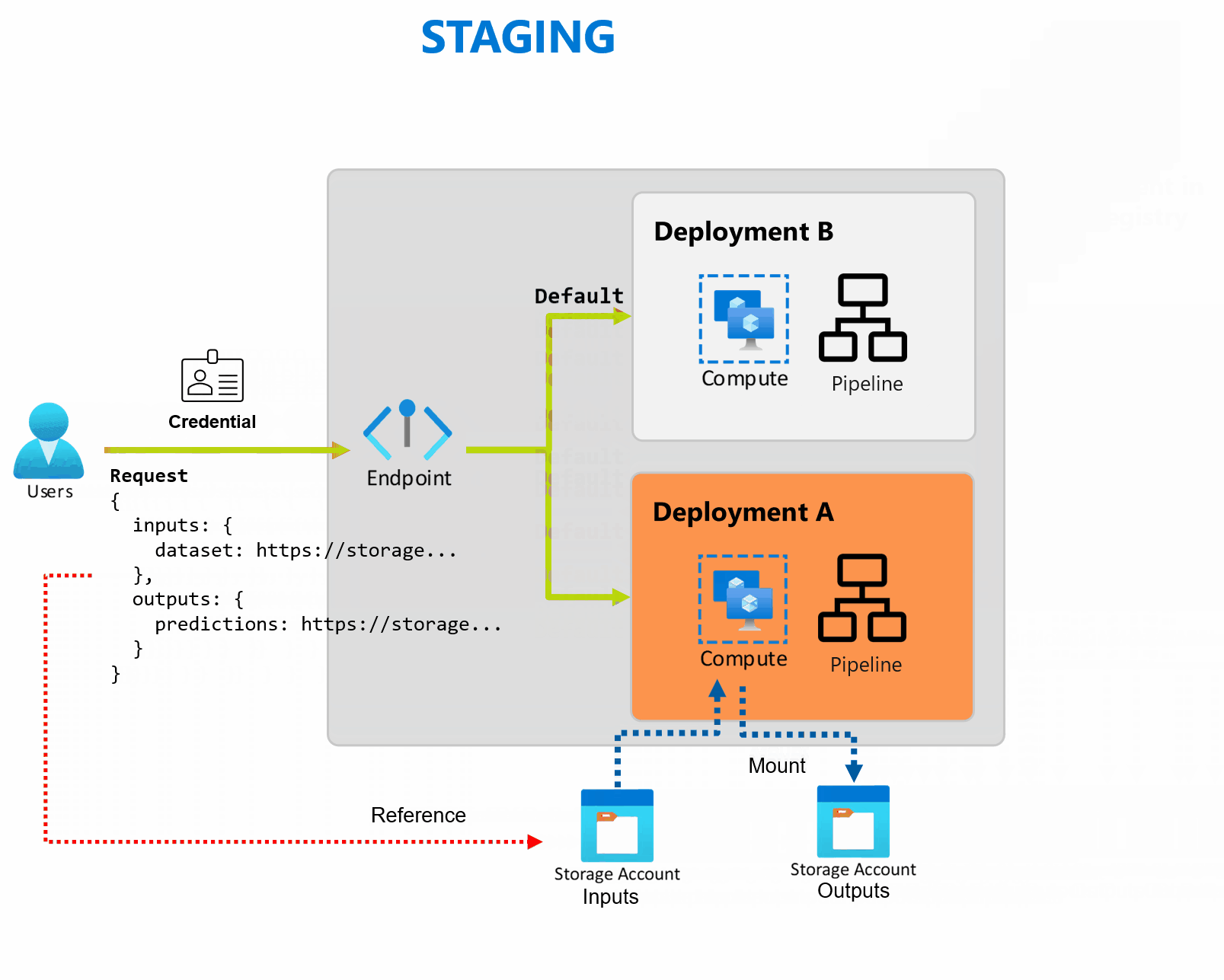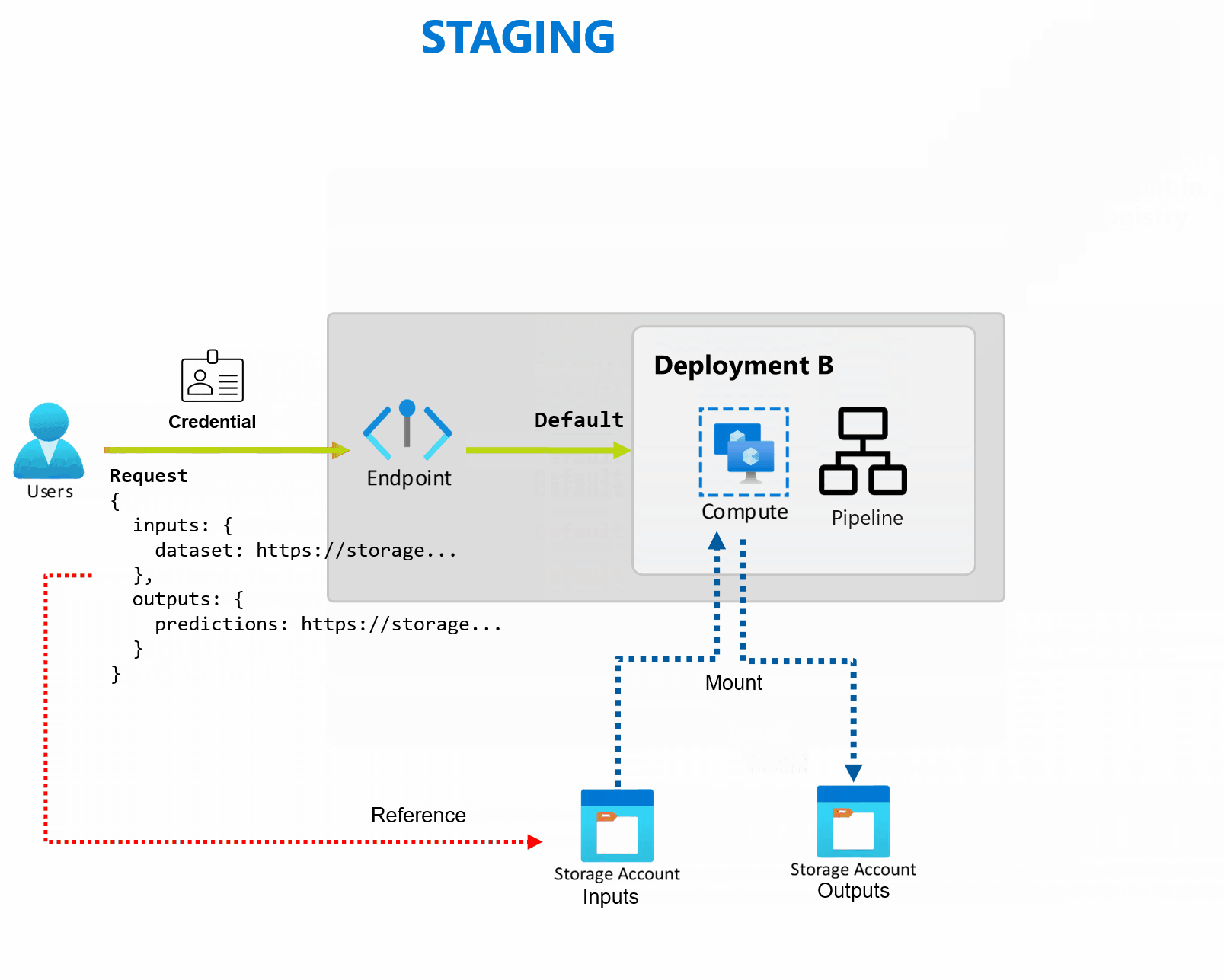
灵活的数据源和存储
批处理终结点直接从存储读取和写入数据。 可以将Azure 机器学习数据存储、Azure 机器学习数据资产或存储帐户指定为输入。 有关支持的输入选项以及如何指定它们的详细信息,请参阅 创建作业和向批处理终结点输入数据。
安全性
批处理终结点提供在企业设置中操作生产级工作负载所需的全部功能。 它们支持安全工作区上的专用网络和 Microsoft Entra 身份验证,使用用户主体(例如用户帐户)或服务主体(例如托管标识或非托管标识)均可。 由批处理终结点生成的作业在调用方标识下运行,这使你可以灵活地实现任何方案。 有关使用批处理终结点时的授权的详细信息,请参阅如何在批处理终结点上进行身份验证。