适用于: Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
本文介绍如何使用自动化 ML 训练有关图像数据的计算机视觉模型。 可以使用 Azure 机器学习 CLI 扩展 v2 或 Azure 机器学习 Python SDK v2 训练模型。
自动化 ML 支持将模型训练用于图像分类、物体检测和实例分段等计算机视觉任务。 目前,Azure 机器学习 Python SDK 支持为计算机视觉任务创作 AutoML 模型。 可以从 Azure 机器学习工作室 UI 访问生成的试验试验、模型和输出。 详细了解用于基于图像数据的计算机视觉任务的自动化 ML。
先决条件
- Azure 机器学习工作区。 若要创建工作区,请参阅创建工作区资源。
- 安装并设置 CLI (v2),并确保安装
ml扩展。
选择任务类型
用于图像的自动化 ML 支持以下任务类型:
| 任务类型 | AutoML 作业语法 |
|---|---|
| 图像分类 | CLI v2:image_classification SDK v2: image_classification() |
| 多标签图像分类 | CLI v2:image_classification_multilabel SDK v2: image_classification_multilabel() |
| 图像物体检测 | CLI v2:image_object_detection SDK v2: image_object_detection() |
| 图像实例分段 | CLI v2:image_instance_segmentation SDK v2: image_instance_segmentation() |
将任务类型设置为必需参数。 使用 task 密钥设置此参数。
例如:
task: image_object_detection
训练和验证数据
若要生成计算机视觉模型,请将带标签的图像数据作为MLTable的输入以进行模型训练。 可以从 JSONL 格式的训练数据创建一个 MLTable。
如果训练数据采用不同的格式(如 pascal VOC 或 COCO),则可以使用示例笔记本中包含的帮助程序脚本将数据转换为 JSONL。 有关详细信息,请参阅 使用自动化 ML 为计算机视觉任务准备数据。
注意
训练数据需要至少有 10 个图像才能提交 AutoML 作业。
警告
对于此功能,SDK 和 CLI 支持从 JSONL 格式的数据创建 MLTable。
MLTable目前不支持通过 UI 创建。
JSONL 架构示例
TabularDataset 的结构取决于手头的任务。 对于计算机视觉任务类型,TabularDataset 由以下字段组成:
| 字段 | 说明 |
|---|---|
image_url |
包含文件路径作为 StreamInfo 对象 |
image_details |
图像元数据信息由高度、宽度和格式组成。 此字段可选。 |
label |
图像标签的 json 表示形式,基于任务类型。 |
以下代码是用于图像分类的示例 JSONL 文件:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
以下代码是用于物体检测的示例 JSONL 文件:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
使用数据
将数据转换为 JSONL 格式后,创建训练和验证 MLTable 文件,如以下示例所示。
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
自动化 ML 不会对计算机视觉任务的训练或验证数据大小施加任何限制。 数据集后面的存储层(例如 Blob 存储)会限制数据集的最大大小。 图像或标签没有最小数量限制。 但是,从每个标签至少 10 到 15 个样本开始,以确保输出模型经过足够的训练。 标签或类总数越高,每个标签所需的样本越多。
使用 training_data 密钥传递所需的训练数据参数。 (可选)使用 validation_data 密钥将另一个 MLTable 指定为验证数据。 如果未指定验证数据,则默认使用 20% 训练数据进行验证,除非传递 validation_data_size 具有不同值的参数。
使用 target_column_name 密钥传递所需的目标列名称参数。 使用此参数作为受监督 ML 任务的目标。 例如,
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
用于运行试验的计算环境
提供计算目标,以便自动化 ML 执行模型训练。 用于计算机视觉任务的自动化 ML 模型要求使用 GPU SKU 并支持 NC 和 ND 系列。 使用 NCsv3 系列(具有 v100 GPU)加快训练速度。 使用多 GPU VM SKU 的计算目标利用多个 GPU 来加快训练速度。 此外,在设置具有多个节点的计算目标的过程中,可以在优化模型的超参数时,通过并行度来更快地执行模型训练。
注意
如果使用 计算实例作为计算 目标,请确保多个 AutoML 作业不会同时运行。 此外,请确保在max_concurrent_trials中将设置为 1。
使用 compute 参数传入计算目标。 例如:
compute: azureml:gpu-cluster
配置试验
对于计算机视觉任务,可以启动 单个试验、 手动扫描或 自动扫描。 从自动扫描开始,获取第一个基线模型。 然后,尝试使用某些模型和超参数配置进行单个试验。 最后,使用手动扫描浏览更有前途的模型和超参数配置附近的多个超参数值。 这种三步式工作流(自动扫描、单独试用、手动扫描)可避免搜索整个超参数空间,这样会导致超参数数量呈指数级增长。
自动扫描可为许多数据集产生有竞争力的结果。 此外,它们不需要对模型体系结构的高级知识。 它们考虑到超参数相关性,并且可在不同的硬件设置之间无缝工作。 所有这些原因使它们成了试验过程早期阶段的有利选择。
主要指标
AutoML 训练作业使用主要指标进行模型优化和超参数优化。 主要指标取决于任务类型,如以下列表所示。 目前不支持其他主要指标值。
作业限制
可以通过在限制设置中为作业指定timeout_minutes、max_trials和max_concurrent_trials来控制 AutoML 图像训练作业上花费的资源,如以下示例中所述。
| 参数 | 详细信息 |
|---|---|
max_trials |
要扫描的最大试用数量的参数。 必须是介于 1 和 1,000 之间的整数。 仅浏览给定模型体系结构的默认超参数时,请将此参数设置为 1。 默认值为 1。 |
max_concurrent_trials |
并发运行的最大试验数。 如果指定了此项,则必须是 1 和 100 之间的整数。 默认值为 1。 注意: max_concurrent_trials 的最大值为 max_trials。 例如,如果设置 max_concurrent_trials=4 和 max_trials=2,这些值在内部更新为 max_concurrent_trials=2 和 max_trials=2。 |
timeout_minutes |
在试验终止之前所花的时间(以分钟为单位)。 如果未指定值,默认的实验超时时间 timeout_minutes 为 7 天(最长 60 天)。 |
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
自动扫描模型超参数 (AutoMode)
重要
此功能目前处于公开预览状态。 此预览版不附带服务级别协议。 某些功能可能不受支持或者受限。 有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
很难预测数据集的最佳模型体系结构和超参数。 此外,在某些情况下,分配给优化超参数的人工时间有限。 对于计算机视觉任务,你可指定任意尝试次数,系统会自动确定要扫描的超参数空间区域。 无需定义超参数搜索空间、采样方法或提前终止策略。
触发 AutoMode
通过在 max_trials 中将 limits 设置为大于一的值,并且不指定搜索空间、采样方法和终止策略来执行自动扫描。 此功能为 AutoMode。 请参阅以下示例。
limits:
max_trials: 10
max_concurrent_trials: 2
进行 10 到 20 次试验在许多数据集上效果良好。 你仍然可以为 AutoML 作业设置 时间预算,但只有当每次试验可能耗时很长时才设置此值。
警告
UI 当前不支持启动自动扫描。
单独试用
在单独试用中,你可以直接控制模型体系结构和超参数。 通过 model_name 参数传递模型体系结构。
支持的模型体系结构
下表汇总了每个计算机视觉任务支持的旧模型。 仅使用这些遗留模型会触发使用遗留运行时的运行,其中每个单独的运行或试验都作为命令作业提交。 有关 HuggingFace 和 MMDetection 支持的信息,请参阅下一部分。
| 任务 | 模型体系结构 | 字符串字面量语法default_model* 用 * 表示 |
|---|---|---|
| 图像分类 (多类和多标签) |
MobileNet:适用于移动应用程序的轻型模型 ResNet:残差网络 ResNeSt:拆分注意力网络 SE-ResNeXt50:压缩奖惩网络 ViT:视觉变换器网络 |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224(小)vitb16r224*(基本)vitl16r224(大) |
| 对象检测 | YOLOv5:单阶段物体检测模型 Faster RCNN ResNet FPN:双阶段物体检测模型 RetinaNet ResNet FPN:使用聚焦损失函数解决类不平衡问题 注意:有关 YOLOv5 模型大小,请参阅 model_size 超参数。 |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| 实例分段 | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
若要对给定的体系结构(例如 yolov5)使用默认的超参数值,请在model_name节中使用training_parameters键来指定体系结构。 例如,
training_parameters:
model_name: yolov5
手动扫描模型超参数
训练计算机视觉模型时,模型性能在很大程度上取决于所选的超参数值。 通常,需要优化超参数以获得最佳性能。 对于计算机视觉任务,可以扫描超参数以找到模型的最佳设置。 此功能将应用 Azure 机器学习中的超参数优化功能。 了解如何优化超参数。
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
定义参数搜索空间
定义要在参数空间中遍历的模型架构和超参数。 可以指定单个模型体系结构或多个体系结构。
- 有关每个任务类型支持的模型体系结构列表,请参阅 “单个试验”。
- 有关每个计算机视觉任务类型的超参数,请参阅 计算机视觉任务的超参数。
- 有关离散和连续超参数支持的分布的详细信息,请参阅 如何优化超参数。
扫描的采样方法
扫描超参数时,请指定用于对定义的参数空间进行扫描的采样方法。 目前,该 sampling_algorithm 参数支持以下采样方法:
| 采样类型 | AutoML 作业语法 |
|---|---|
| 随机采样 | random |
| 网格采样 | grid |
| 贝叶斯采样 | bayesian |
注意
目前,只有随机采样和网格采样支持条件超参数空间。
提前终止策略
使用提前终止策略自动结束性能不佳的试用。 早期终止通过节省否则可能用于不太可能成功的试验的计算资源,提高了计算效率。 自动化图像机器学习通过使用 early_termination 参数支持以下早期终止策略。 如果未指定终止策略,则所有试用版都会运行到完成。
| 提前终止策略 | AutoML 作业语法 |
|---|---|
| 老虎机策略 | CLI v2:bandit SDK v2: BanditPolicy() |
| 中间值停止策略 | CLI v2:median_stopping SDK v2: MedianStoppingPolicy() |
| 截断选择策略 | CLI v2:truncation_selection SDK v2: TruncationSelectionPolicy() |
有关详细信息,请参阅 如何为超参数扫描配置提前终止策略。
注意
有关完整的扫描配置示例,请参阅 教程。
可配置与扫描相关的所有参数,如以下示例所示。
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
固定设置
传递在参数空间扫描期间不会更改的固定设置或参数,如以下示例所示。
training_parameters:
early_stopping: True
evaluation_frequency: 1
数据增强
一般情况下,深度学习模型的性能通常可以随着数据的增加而提高。 数据扩充是一种实用技术,用于增加数据集的规模和多样性。 此方法有助于防止过度拟合,并提高模型对看不见数据的通用化能力。 在将输入图像馈送到模型之前,自动化 ML 将根据计算机视觉任务应用不同的数据增强技术。 目前,没有超参数控制数据扩充。
| 任务 | 受影响的数据集 | 应用的数据扩充技术 |
|---|---|---|
| 图像分类(多类和多标签) | 培训 验证和测试 |
随机调整大小和裁剪、水平翻转、颜色抖动(亮度、对比度、饱和度和色调),使用通道方向 ImageNet 的平均值和标准偏差进行规范化 调整大小、中心裁剪、规范化 |
| 物体检测、实例分段 | 培训 验证和测试 |
围绕边界框随机裁剪、展开、水平翻转、规范化、调整大小 规范化、调整大小 |
| 使用 yolov5 进行物体检测 | 培训 验证和测试 |
马赛克、随机仿射(旋转、平移、缩放、剪切)、水平翻转 上下黑边调整大小 |
默认情况下,该模型会对图像作业的自动化机器学习应用上表中定义的增强。 为了提供对扩充的控制,图像的自动化 ML 公开以下两个标志来关闭某些扩充。 目前,这些标志仅支持对象检测和实例分段任务。
- apply_mosaic_for_yolo: 此标志特定于 Yolo 模型。 将其设置为 False 以关闭马赛克数据扩充。 模型在训练时应用此扩充。
-
apply_automl_train_augmentations: 将此标志设置为 false,以关闭模型在对象检测和实例分段模型训练期间应用的扩充。 请参阅上表中列出的详细信息以了解扩充。
- 对于非 yolo 对象检测模型和实例分段模型,此标志仅关闭前三个增强。 例如:在边界框周围随机裁剪、扩展、水平翻转。 无论此标志如何,都会应用规范化和调整大小扩充。
- 对于 Yolo 模型,此标志会关闭随机仿射和水平翻转扩充。
可以通过training_parameters下的advanced_settings设置这两个标志。
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
这两个标志彼此独立。 还可以使用以下设置将它们组合在一起。
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
在我们的实验中,这些扩充有助于模型更好地通用化。 如果关闭这些增强功能,可以将它们与其他离线增强功能结合使用,以获得更好的效果。
增量训练(可选)
训练作业完成后,可以通过加载训练的模型检查点来进一步训练模型。 使用相同的数据集或其他数据集进行增量训练。 如果对模型感到满意,请停止训练并使用当前模型。
通过作业 ID 传递检查点
传递作业 ID 以从中加载检查点。
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
提交 AutoML 作业
若要提交 AutoML 作业,请使用.yml文件、工作区名称、资源组和订阅 ID 的路径运行以下 CLI v2 命令。
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
输出和评估指标
自动化 ML 训练作业生成输出模型文件、评估指标、日志和部署项目,例如评分文件和环境文件。 可以从子作业的输出和日志和指标选项卡中查看这些文件和指标。
提示
在查看作业结果部分了解如何导航到作业结果。
有关为每次作业提供的性能图表和指标的定义和示例,请参阅评估自动化机器学习试验结果。
注册和部署模型
作业完成后,注册基于最佳试验创建的模型(即得到最佳主要指标的配置)。 可以在下载模型后注册模型,或者通过指定具有相应作业 ID 的 azureml 路径来注册模型。 如果要更改推理设置,请下载模型、更改 settings.json和注册更新的模型文件夹。
获取最佳试用
CLI example not available, please use Python SDK.
注册模型
使用 azureml 路径或本地下载的路径注册模型。
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
注册模型后,可以使用托管联机终结点 deploy-managed-online-endpoint 部署模型。
配置联机终结点
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
创建终结点
请使用之前创建的 MLClient 在工作区中创建终结点。 此命令会启动终结点创建操作,并在终结点创建操作继续时返回确认响应。
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
配置联机部署
部署是一组资源,用于承载执行实际推理的模型。 使用 ManagedOnlineDeployment 类为终结点创建部署。 可以将 GPU 或 CPU VM 版本用于部署群集。
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
创建部署
在工作区中使用之前创建的MLClient来创建部署。 此命令将启动部署创建操作,并在部署创建操作继续时返回确认响应。
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
更新流量
默认情况下,当前部署设置为接收 0% 流量。 设置当前部署应接收的流量百分比。 具有一个终结点的所有部署的流量百分比总和不能超过 100%。
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
或者,可以从 Azure 机器学习工作室 UI 部署模型。 导航到要在自动化 ML 作业的 “模型 ”选项卡中部署的模型。 选择“ 部署 ”,然后选择“ 部署到实时终结点”。
 。
。
这是你的审阅页面的外观。 可以选择实例类型、实例计数,并为当前部署设置流量百分比。
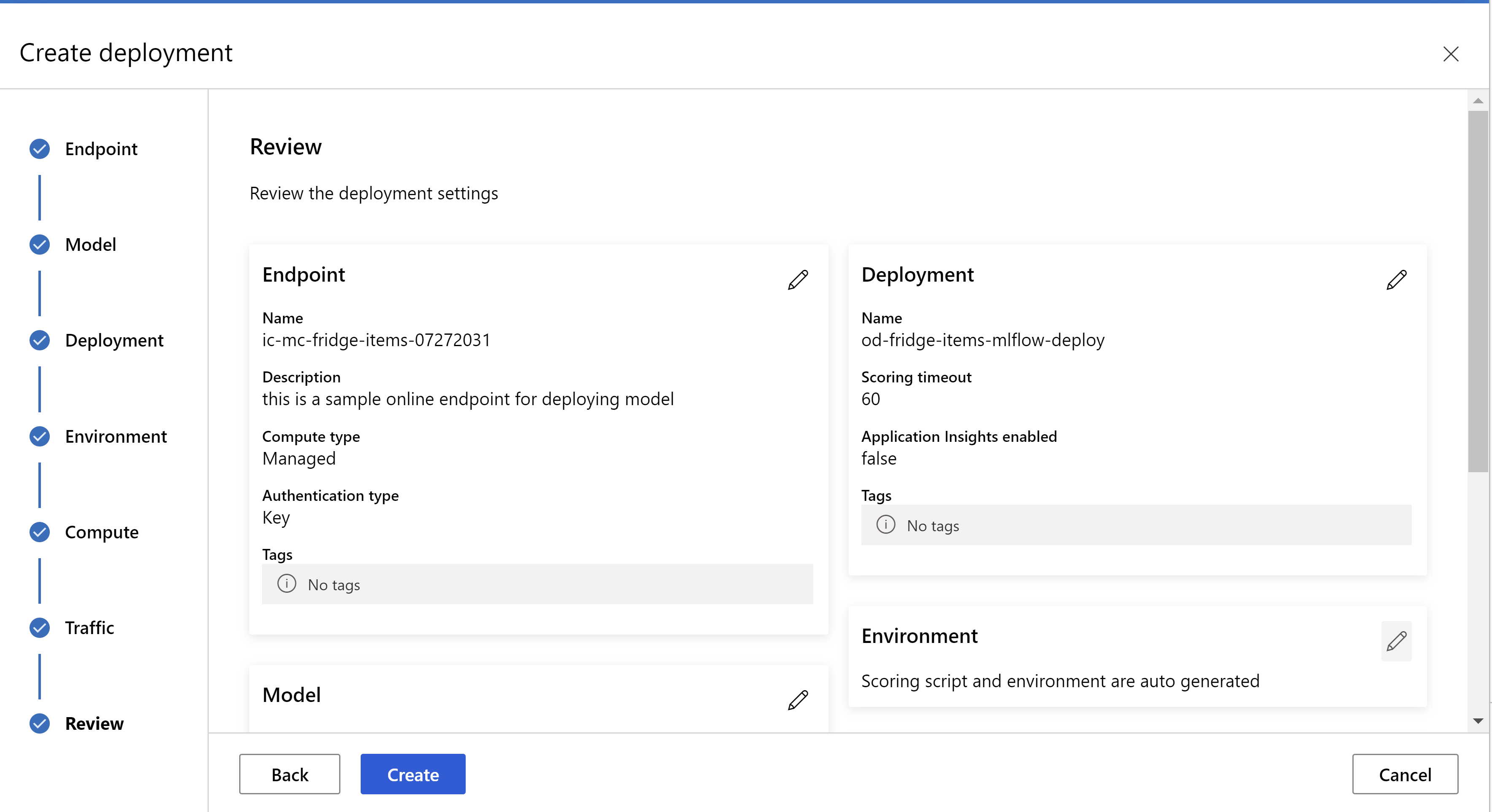 。
。
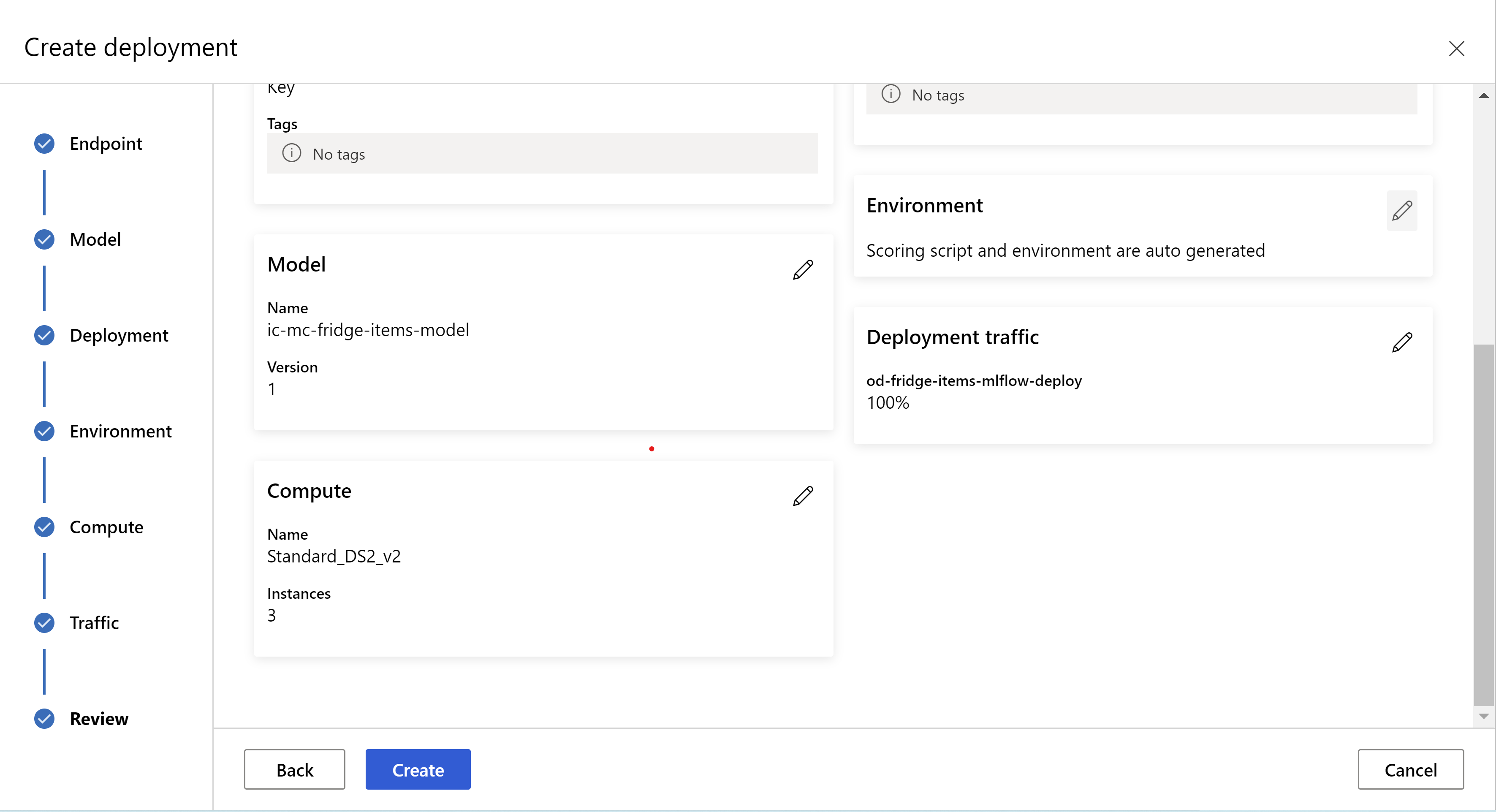 。
。
更新推理设置
在上一个步骤中,你从最佳模型下载了文件mlflow-model/artifacts/settings.json。 在注册模型之前,使用此文件更新推理设置。 为了获得最佳性能,请使用与训练相同的参数。
每个任务(和某些模型)都有一组参数。 默认情况下,我们将为参数使用在训练和验证期间所用的相同值。 根据使用模型进行推理时所需的行为,我们可以更改这些参数。 在下面可以找到每个任务类型和模型的参数列表。
| 任务 | 参数名称 | 默认 |
|---|---|---|
| 图像分类(多类和多标签) | valid_resize_sizevalid_crop_size |
256 224 |
| 对象检测 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
使用 yolov5 进行物体检测 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 中 0.1 0.5 |
| 实例分段 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
若要详细了解特定于任务的超参数,请参阅自动化机器学习中计算机视觉任务的超参数。
如果要使用平铺和控制平铺行为,可以使用以下参数: tile_grid_size、 tile_overlap_ratio和 tile_predictions_nms_thresh。 有关这些参数的更多详细信息,请参阅 使用 AutoML 训练小型对象检测模型。
测试部署
若要测试部署并可视化模型中的检测,请参阅 “测试部署”。
生成预测解释
重要
这些设置目前以公共预览版提供。 在没有服务级别协议的情况下提供它们。 某些功能可能不受支持或者受限。 有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
警告
模型可解释性 仅支持 多类分类 和 多标签分类。
使用可解释人工智能(XAI)与自动机器学习(AutoML)技术相结合处理图像的优点包括:
- 改进了复杂视觉模型预测中的透明度
- 帮助用户了解输入图像中有助于模型预测的重要特征或像素
- 帮助对模型进行故障排除
- 帮助发现偏见
说明
解释是根据对模型预测的贡献,为输入图像中的每个像素提供 特征属性 或权重。 每个权重可为负(与预测负相关)或为正(与预测正相关)。 根据预测的类计算这些属性。 对于多类分类,每个样本仅生成一个具有大小 [3, valid_crop_size, valid_crop_size] 的归因矩阵。 对于多标签分类,将为每个样本的每个预测标签或类生成大小 [3, valid_crop_size, valid_crop_size] 属性矩阵。
通过在部署的终结点上使用 AutoML for Images 与 Explainable AI, 您可以获取有关每个图像的解释的可视化(将贡献度叠加在输入图像上)和贡献度(大小为[3, valid_crop_size, valid_crop_size]的多维数组)。 除了可视化效果之外,还可以获取属性矩阵,以更好地控制解释,例如使用属性生成自定义可视化效果或仔细查看归因段。 所有解释算法都使用大小为 valid_crop_size 的裁剪正方形图像来生成归因。
可以从 联机终结点 或 批处理终结点生成说明。 部署终结点后,可以使用它生成预测说明。 在联机部署中,请确保将 request_settings = OnlineRequestSettings(request_timeout_ms=90000) 参数 ManagedOnlineDeployment 传递给并设置为 request_timeout_ms 其最大值,以避免在生成说明时出现 超时问题 (请参阅 寄存器和部署模型部分)。 一些可解释性(XAI)方法,例如xrai,会消耗更多时间,尤其是在多标签分类中,因为您需要为每个预测标签生成归因和可视化。 使用任何 GPU 实例以实现更快的解释。 有关用于生成解释的输入和输出架构的详细信息,请参阅架构文档。
AutoML for images 支持以下最先进的可解释性算法:
- XRAI (xrai)
- 集成渐变 (integrated_gradients)
- 引导式 GradCAM (guided_gradcam)
- 引导式反向传播 (guided_backprop)
下表介绍了 XRAI 和集成渐变的可解释性算法特定优化参数。 引导式反向传播和引导式 gradcam 不需要任何优化参数。
| XAI 算法 | 算法特定的参数 | 默认值 |
|---|---|---|
xrai |
1. n_steps:求近似值方法使用的步数。 增加步骤数量会导致更好地近似归因(解释)。 n_steps的范围为 [2, inf),但属性的性能在 50 个步骤后开始收敛。 Optional, Int 2. xrai_fast:是否使用更快的 XRAI 版本。 如果为 True,则解释的计算时间更快,但会导致解释(属性)的准确度更低Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps:求近似值方法使用的步数。 更多的步骤会导致更好的归属(解释)。 n_steps的范围为 [2, inf),但属性的性能在 50 个步骤后开始收敛。Optional, Int 2. approximation_method:求整数近似值的方法。 可用的求近似值方法是 riemann_middle 和 gausslegendre。Optional, String |
n_steps = 50 approximation_method = riemann_middle |
在内部,XRAI 算法使用集成渐变。 因此,集成渐变和 XRAI 算法都需要参数 n_steps 。 更多的步骤消耗更多时间来近似解释,这可能会导致联机终结点出现超时问题。
有关更好的说明,请使用 XRAI > 引导式 GradCAM > 集成渐变 > 引导式 BackPropagation 算法。 欲获得更快速的解释,请按照指定顺序使用引导式反向传播 > 引导式 GradCAM > 集成梯度 > 和 XRAI。
对联机终结点的示例请求如下所示。 当 model_explainability 设置为 True 时,此请求会生成解释。 以下请求通过 50 个步骤使用 XRAI 算法的更快版本生成可视化效果和属性。
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
有关生成解释的详细信息,请参阅用于自动化机器学习的 GitHub 笔记本存储库示例。
解释可视化效果
如果已部署的终端同时将 model_explainability 和 visualizations 设置为 True,则返回一个 base64 编码的图像字符串。 按照 笔记本 中所述解码 base64 字符串,或使用以下代码对预测中的 base64 图像字符串进行解码和可视化。
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
下图展示了对示例输入图像的解释进行的可视化。

解码的 base64 图在 2 x 2 网格中具有四个图像部分。
- 左上角的图像(0,0)是裁剪的输入图像。
- 右上角 (0, 1) 的图像是色标 bgyw(蓝绿黄白)的属性热度地图,其中白色像素对预测类别的贡献最高,蓝色像素最低。
- 左下角的图像(1, 0)是裁剪后的输入图像上的属性融合热图。
- 右下角的图像(1,1)是裁剪的输入图像,其前 30% 的像素基于属性分数。
解读归因
如果 model_explainability 和 attributions 均设置为 True,则部署的终结点将返回属性。 有关更多详细信息,请参阅 多类分类和多标签分类笔记本。
这些属性使用户能够更控制地生成自定义可视化效果或审查像素级属性分数。 以下代码片段描述了使用属性矩阵生成自定义可视化效果的方法。 有关多类分类和多标签分类的属性架构的详细信息,请参阅架构文档。
使用所选模型的确切 valid_resize_size 和 valid_crop_size 值生成解释(默认值分别为 256 和 224)。 以下代码使用 Captum 可视化功能生成自定义可视化效果。 用户可以利用任何其他库来生成可视化效果。 有关更多详细信息,请参阅 captum 可视化实用工具。
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
大型数据集
如果使用 AutoML 训练大型数据集,则某些实验性设置可能很有用。
重要
这些设置目前以公共预览版提供。 在没有服务级别协议的情况下提供它们。 某些功能可能不受支持或者受限。 有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
多 GPU 和多节点训练
默认情况下,每个模型在单个 VM 上进行训练。 如果训练模型需要太多时间,则使用包含多个 GPU 的 VM 可能会有所帮助。 在大型数据集上训练模型的时间会根据使用的 GPU 数量大致呈线性比例下降。 例如,模型在具有两个 GPU 的 VM 上的训练速度大约是仅有一个 GPU 的 VM 上的两倍。 如果在具有多个 GPU 的 VM 上训练模型的时间仍然很高,则可以增加用于训练每个模型的 VM 数量。 与多 GPU 训练类似,在大型数据集上训练模型的时间也会与使用的 VM 数量大致呈线性比例下降。 在多个 VM 上训练模型时,请务必使用支持 InfiniBand 的计算 SKU 来获得最佳结果。 可以通过设置 AutoML 作业的 node_count_per_trial 属性来配置用于训练单个模型的 VM 数量。
properties:
node_count_per_trial: "2"
从存储中流式传输图像文件
默认情况下,训练过程会在启动之前将所有映像文件下载到磁盘。 如果映像文件的大小大于可用磁盘空间,作业将失败。 若要避免此问题,请选择在训练期间从 Azure 存储流式传输图像文件的选项。 训练过程将映像文件从 Azure 存储直接流式传输到系统内存,绕过磁盘。 同时,进程从磁盘上的存储缓存尽可能多的文件,以最大程度地减少对存储的请求数。
注意
如果启用流式处理,请确保 Azure 存储帐户与计算资源位于同一区域,以最大程度地降低成本和延迟。
training_parameters:
advanced_settings: >
{"stream_image_files": true}
示例笔记本
有关详细的代码示例和用例,请参阅 GitHub 笔记本存储库,了解自动化机器学习示例。 查找前缀为“automl-image-”的文件夹,以获取构建计算机视觉模型的特定示例。
代码示例
有关详细的代码示例和用例,请参阅 用于自动化机器学习示例的 azureml 示例存储库。