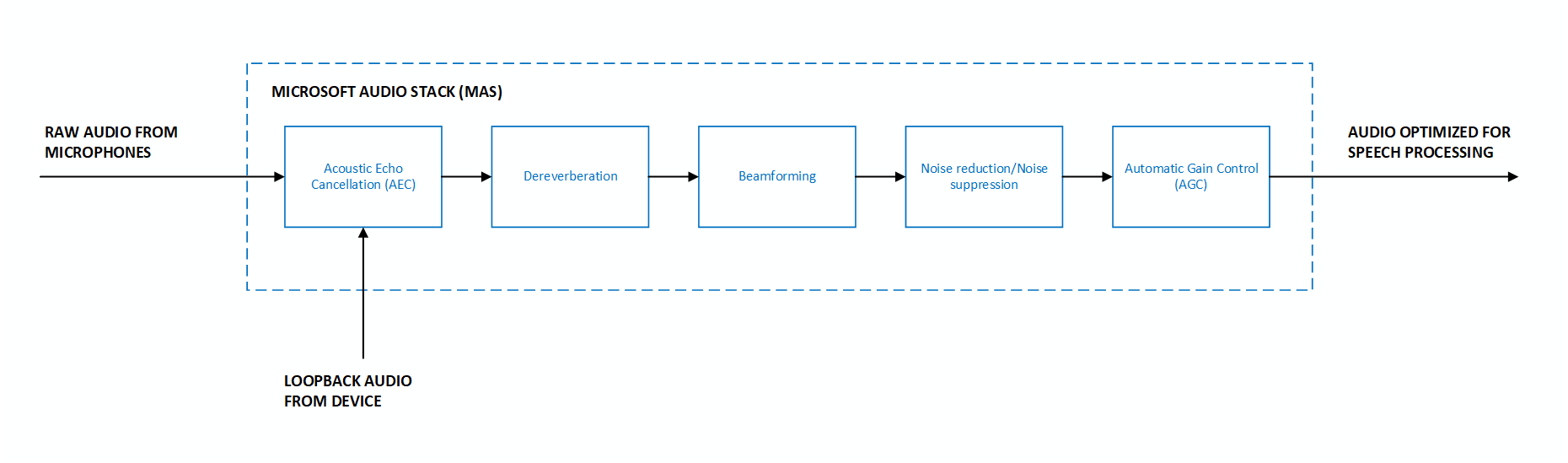
Microsoft音频堆栈中默认基于 DSP 的管道(AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT)使用传统的数字信号处理算法来增强输入音频。 有关可用管道的比较,请参阅 音频处理概述 。 有关基于模型的回声消除的更多信息,请参阅使用 Microsoft 音频堆栈的基于模型的回声消除。
DSP 增强功能
基于 DSP 的管道针对输入音频信号提供以下增强功能:
- 波束成形 - 使用多个麦克风定位声音来源并优化音频信号。
- 去混响 - 减少环境中表面的声音反射。
- 声学回声消除 - 抑制设备在麦克风输入处于活动状态时播放的音频。
-
自动增益控制 - 动态调整人员的语音级别,以考虑声音较小的发言者、距离远或未校准的麦克风。
- 噪音抑制 - 降低背景噪音水平。 需要使用麦克风阵列以获得最佳性能;使用单个麦克风或信噪比低的音频时,效果不佳。
不同场景和用例可能需要进行不同的优化来影响音频处理堆栈的行为。 例如,在诸如电话通话之类的电信场景中,在应用了处理之后,音频信号中的轻微失真是可以接受的。 正是因为人们可以持续高精度地理解语音。 然而,在回声中听到自己的声音是不可接受的,这也具有扰乱性。 这与语音处理场景形成对比,在语音处理场景中,失真的音频可能会对机器学习语音识别模型的准确度产生不利影响,但可以接受轻微程度的回声残余。
主要功能
基于 DSP 的管道通过语音 SDK 支持以下功能:
- 增强功能选项 - 为了让你对应用场景进行全面控制,SDK 允许你禁用单个增强功能,如残响消除、噪声抑制、自动增益控制和回声消除。 例如,如果您的方案不包括渲染需要从输入音频中消除的输出音频,那么您可以选择禁用声学回声消除。
- 自定义麦克风几何 - 此 SDK 允许你提供自己的自定义麦克风几何信息,并支持预设几何,例如线性双麦、线性四麦和环形七麦阵列(有关支持的预设几何的详细信息,请参阅麦克风阵列建议)。
- 波束赋形角度 - 可提供特定的波束赋形角度来优化源自预定位置(相对于麦克风)的音频输入。
基于 DSP 的管道需要以下输入参数:
-
Raw audio - Microsoft音频堆栈需要原始(未处理)音频作为输入才能产生最佳结果。
-
麦克风几何图形 - 设备上每个麦克风的几何信息是正确执行所有增强功能所必需的。 该信息包括麦克风数量、其物理排列和坐标。 最多支持 16 个输入麦克风通道。
- 环回或参考音频 - 执行声学回声消除需要一个表示设备正在播放音频的音频通道。
-
输入格式 - 支持对采样率为 16 kHz 整数倍的下采样。 要求最低采样率为16 kHz。
代码示例
以下示例演示如何使用不同的配置使用基于 DSP 的管道。
默认选项
此示例演示了如何使用 MAS 应用所有默认增强选项于设备的默认麦克风输入。
var speechConfig = SpeechConfig.FromEndpoint(new Uri("YourSpeechEndpoint"), "YourSpeechKey");
var audioProcessingOptions = AudioProcessingOptions.Create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT);
var audioInput = AudioConfig.FromDefaultMicrophoneInput(audioProcessingOptions);
var recognizer = new SpeechRecognizer(speechConfig, audioInput);
auto speechConfig = SpeechConfig::FromEndpoint("YourServiceEndpoint", "YourSpeechResoureKey");
auto audioProcessingOptions = AudioProcessingOptions::Create(AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT);
auto audioInput = AudioConfig::FromDefaultMicrophoneInput(audioProcessingOptions);
auto recognizer = SpeechRecognizer::FromConfig(speechConfig, audioInput);
SpeechConfig speechConfig = SpeechConfig.fromEndpoint(new java.net.URI("YourSpeechEndpoint"), "YourSpeechKey");
AudioProcessingOptions audioProcessingOptions = AudioProcessingOptions.create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT);
AudioConfig audioInput = AudioConfig.fromDefaultMicrophoneInput(audioProcessingOptions);
SpeechRecognizer recognizer = new SpeechRecognizer(speechConfig, audioInput);
预设麦克风几何结构
此示例显示了如何在指定的音频输入设备上将 MAS 与预定义的麦克风几何配合使用。 在本示例中:
-
增强功能选项 - 应用于输入音频流的默认增强功能。
- 预设几何 - 预设几何表示线性双麦克风阵列。
- 音频输入设备 - 音频输入设备 ID 是
hw:0,1。 若要详细了解如何选择音频输入设备,请参阅如何:使用语音 SDK 选择音频输入设备。
var speechConfig = SpeechConfig.FromEndpoint(new Uri("YourSpeechEndpoint"), "YourSpeechKey");
var audioProcessingOptions = AudioProcessingOptions.Create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, PresetMicrophoneArrayGeometry.Linear2);
var audioInput = AudioConfig.FromMicrophoneInput("hw:0,1", audioProcessingOptions);
var recognizer = new SpeechRecognizer(speechConfig, audioInput);
auto speechConfig = SpeechConfig::FromEndpoint("YourServiceEndpoint", "YourSpeechResoureKey");
auto audioProcessingOptions = AudioProcessingOptions::Create(AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, PresetMicrophoneArrayGeometry::Linear2);
auto audioInput = AudioConfig::FromMicrophoneInput("hw:0,1", audioProcessingOptions);
auto recognizer = SpeechRecognizer::FromConfig(speechConfig, audioInput);
SpeechConfig speechConfig = SpeechConfig.fromEndpoint(new java.net.URI("YourSpeechEndpoint"), "YourSpeechKey");
AudioProcessingOptions audioProcessingOptions = AudioProcessingOptions.create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, PresetMicrophoneArrayGeometry.Linear2);
AudioConfig audioInput = AudioConfig.fromMicrophoneInput("hw:0,1", audioProcessingOptions);
SpeechRecognizer recognizer = new SpeechRecognizer(speechConfig, audioInput);
自定义麦克风几何结构
此示例显示了如何在指定的音频输入设备上将 MAS 与自定义麦克风几何配合使用。 在本示例中:
-
增强功能选项 - 应用于输入音频流的默认增强功能。
-
自定义几何结构 - 通过麦克风坐标提供 7 麦克风阵列的自定义麦克风几何结构。 坐标单位为毫米。
-
音频输入 - 音频输入来自文件,文件中的音频应来自与指定的自定义几何结构相对应的音频输入设备。
var speechConfig = SpeechConfig.FromEndpoint(new Uri("YourSpeechEndpoint"), "YourSpeechKey");
MicrophoneCoordinates[] microphoneCoordinates = new MicrophoneCoordinates[7]
{
new MicrophoneCoordinates(0, 0, 0),
new MicrophoneCoordinates(40, 0, 0),
new MicrophoneCoordinates(20, -35, 0),
new MicrophoneCoordinates(-20, -35, 0),
new MicrophoneCoordinates(-40, 0, 0),
new MicrophoneCoordinates(-20, 35, 0),
new MicrophoneCoordinates(20, 35, 0)
};
var microphoneArrayGeometry = new MicrophoneArrayGeometry(MicrophoneArrayType.Planar, microphoneCoordinates);
var audioProcessingOptions = AudioProcessingOptions.Create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, microphoneArrayGeometry, SpeakerReferenceChannel.LastChannel);
var audioInput = AudioConfig.FromWavFileInput("katiesteve.wav", audioProcessingOptions);
var recognizer = new SpeechRecognizer(speechConfig, audioInput);
auto speechConfig = SpeechConfig::FromEndpoint("YourServiceEndpoint", "YourSpeechResoureKey");
MicrophoneArrayGeometry microphoneArrayGeometry
{
MicrophoneArrayType::Planar,
{ { 0, 0, 0 }, { 40, 0, 0 }, { 20, -35, 0 }, { -20, -35, 0 }, { -40, 0, 0 }, { -20, 35, 0 }, { 20, 35, 0 } }
};
auto audioProcessingOptions = AudioProcessingOptions::Create(AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, microphoneArrayGeometry, SpeakerReferenceChannel::LastChannel);
auto audioInput = AudioConfig::FromWavFileInput("katiesteve.wav", audioProcessingOptions);
auto recognizer = SpeechRecognizer::FromConfig(speechConfig, audioInput);
SpeechConfig speechConfig = SpeechConfig.fromEndpoint(new java.net.URI("YourSpeechEndpoint"), "YourSpeechKey");
MicrophoneCoordinates[] microphoneCoordinates = new MicrophoneCoordinates[7];
microphoneCoordinates[0] = new MicrophoneCoordinates(0, 0, 0);
microphoneCoordinates[1] = new MicrophoneCoordinates(40, 0, 0);
microphoneCoordinates[2] = new MicrophoneCoordinates(20, -35, 0);
microphoneCoordinates[3] = new MicrophoneCoordinates(-20, -35, 0);
microphoneCoordinates[4] = new MicrophoneCoordinates(-40, 0, 0);
microphoneCoordinates[5] = new MicrophoneCoordinates(-20, 35, 0);
microphoneCoordinates[6] = new MicrophoneCoordinates(20, 35, 0);
MicrophoneArrayGeometry microphoneArrayGeometry = new MicrophoneArrayGeometry(MicrophoneArrayType.Planar, microphoneCoordinates);
AudioProcessingOptions audioProcessingOptions = AudioProcessingOptions.create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, microphoneArrayGeometry, SpeakerReferenceChannel.LastChannel);
AudioConfig audioInput = AudioConfig.fromWavFileInput("katiesteve.wav", audioProcessingOptions);
SpeechRecognizer recognizer = new SpeechRecognizer(speechConfig, audioInput);
选择增强功能
此示例显示了如何将 MAS 与一组自定义增强功能配合用于输入音频。 默认启用所有增强功能,但可以使用一些选项通过 AudioProcessingOptions 来分别禁用残响消除、噪声抑制、自动增益控制和回声消除。
在本示例中:
- 增强功能选项 - 禁用回声消除和噪声抑制,并让所有其他增强功能保持启用状态。
- 音频输入设备 - 音频输入设备是此设备的默认麦克风。
var speechConfig = SpeechConfig.FromEndpoint(new Uri("YourSpeechEndpoint"), "YourSpeechKey");
var audioProcessingOptions = AudioProcessingOptions.Create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_DISABLE_ECHO_CANCELLATION | AudioProcessingConstants.AUDIO_INPUT_PROCESSING_DISABLE_NOISE_SUPPRESSION | AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT);
var audioInput = AudioConfig.FromDefaultMicrophoneInput(audioProcessingOptions);
var recognizer = new SpeechRecognizer(speechConfig, audioInput);
auto speechConfig = SpeechConfig::FromEndpoint("YourServiceEndpoint", "YourSpeechResoureKey");
auto audioProcessingOptions = AudioProcessingOptions::Create(AUDIO_INPUT_PROCESSING_DISABLE_ECHO_CANCELLATION | AUDIO_INPUT_PROCESSING_DISABLE_NOISE_SUPPRESSION | AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT);
auto audioInput = AudioConfig::FromDefaultMicrophoneInput(audioProcessingOptions);
auto recognizer = SpeechRecognizer::FromConfig(speechConfig, audioInput);
SpeechConfig speechConfig = SpeechConfig.fromEndpoint(new java.net.URI("YourSpeechEndpoint"), "YourSpeechKey");
AudioProcessingOptions audioProcessingOptions = AudioProcessingOptions.create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_DISABLE_ECHO_CANCELLATION | AudioProcessingConstants.AUDIO_INPUT_PROCESSING_DISABLE_NOISE_SUPPRESSION | AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT);
AudioConfig audioInput = AudioConfig.fromDefaultMicrophoneInput(audioProcessingOptions);
SpeechRecognizer recognizer = new SpeechRecognizer(speechConfig, audioInput);
此示例显示了如何在指定的音频输入设备上将 MAS 与自定义麦克风几何以及波束赋形配合使用。 在本示例中:
-
增强功能选项 - 应用于输入音频流的默认增强功能。
- 自定义几何 - 通过指定麦克风坐标来提供四麦阵列的自定义麦克风几何。 坐标单位为毫米。
- 波束赋形角度 - 指定波束赋形角度可以针对源自该范围内的音频进行优化。 角度单位为度。
-
音频输入 - 音频输入来自推送流,流中的音频应来自与指定的自定义几何结构相对应的音频输入设备。
在下面的代码示例中,开始角度设置为 70 度,结束角度设置为 110 度。
var speechConfig = SpeechConfig.FromEndpoint(new Uri("YourSpeechEndpoint"), "YourSpeechKey");
MicrophoneCoordinates[] microphoneCoordinates = new MicrophoneCoordinates[4]
{
new MicrophoneCoordinates(-60, 0, 0),
new MicrophoneCoordinates(-20, 0, 0),
new MicrophoneCoordinates(20, 0, 0),
new MicrophoneCoordinates(60, 0, 0)
};
var microphoneArrayGeometry = new MicrophoneArrayGeometry(MicrophoneArrayType.Linear, 70, 110, microphoneCoordinates);
var audioProcessingOptions = AudioProcessingOptions.Create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, microphoneArrayGeometry, SpeakerReferenceChannel.LastChannel);
var pushStream = AudioInputStream.CreatePushStream();
var audioInput = AudioConfig.FromStreamInput(pushStream, audioProcessingOptions);
var recognizer = new SpeechRecognizer(speechConfig, audioInput);
auto speechConfig = SpeechConfig::FromEndpoint("YourServiceEndpoint", "YourSpeechResoureKey");
MicrophoneArrayGeometry microphoneArrayGeometry
{
MicrophoneArrayType::Linear,
70,
110,
{ { -60, 0, 0 }, { -20, 0, 0 }, { 20, 0, 0 }, { 60, 0, 0 } }
};
auto audioProcessingOptions = AudioProcessingOptions::Create(AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, microphoneArrayGeometry, SpeakerReferenceChannel::LastChannel);
auto pushStream = AudioInputStream::CreatePushStream();
auto audioInput = AudioConfig::FromStreamInput(pushStream, audioProcessingOptions);
auto recognizer = SpeechRecognizer::FromConfig(speechConfig, audioInput);
SpeechConfig speechConfig = SpeechConfig.fromEndpoint(new java.net.URI("YourSpeechEndpoint"), "YourSpeechKey");
MicrophoneCoordinates[] microphoneCoordinates = new MicrophoneCoordinates[4];
microphoneCoordinates[0] = new MicrophoneCoordinates(-60, 0, 0);
microphoneCoordinates[1] = new MicrophoneCoordinates(-20, 0, 0);
microphoneCoordinates[2] = new MicrophoneCoordinates(20, 0, 0);
microphoneCoordinates[3] = new MicrophoneCoordinates(60, 0, 0);
MicrophoneArrayGeometry microphoneArrayGeometry = new MicrophoneArrayGeometry(MicrophoneArrayType.Planar, 70, 110, microphoneCoordinates);
AudioProcessingOptions audioProcessingOptions = AudioProcessingOptions.create(AudioProcessingConstants.AUDIO_INPUT_PROCESSING_ENABLE_DEFAULT, microphoneArrayGeometry, SpeakerReferenceChannel.LastChannel);
PushAudioInputStream pushStream = AudioInputStream.createPushStream();
AudioConfig audioInput = AudioConfig.fromStreamInput(pushStream, audioProcessingOptions);
SpeechRecognizer recognizer = new SpeechRecognizer(speechConfig, audioInput);
回声消除的参考通道
Microsoft 音频堆栈要求使用参考通道(也称为环回通道)来执行回声消除。 参考通道的源因平台而异:
- Windows - 如果在创建 时提供
SpeakerReferenceChannel::LastChannel 选项,则语音 SDK 会自动收集参考通道。
-
Linux - 必须将 ALSA(高级 Linux 声音体系结构)配置为提供参考音频流作为所用音频输入设备的最后一个通道。 在创建
SpeakerReferenceChannel::LastChannel 时,除了提供 AudioProcessingOptions 选项外,还要配置 ALSA。
相关内容
