使用适用于 PostgreSQL 的 Azure Cosmos DB 设计多租户数据库
适用对象:![]() Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
在本教程中,你将使用适用于 PostgreSQL 的 Azure Cosmos DB 来了解如何执行以下操作:
- 创建群集
- 使用 psql 实用工具创建架构
- 在节点之间将表分片
- 引入示例数据
- 查询租户数据
- 租户之间共享数据
- 自定义每租户架构
先决条件
如果没有 Azure 订阅,请在开始前创建一个试用版订阅帐户。
创建群集
登录到 Azure 门户,并按照以下步骤创建 Azure Cosmos DB for PostgreSQL 群集:
转到 Azure 门户中的创建 Azure Cosmos DB for PostgreSQL 群集。
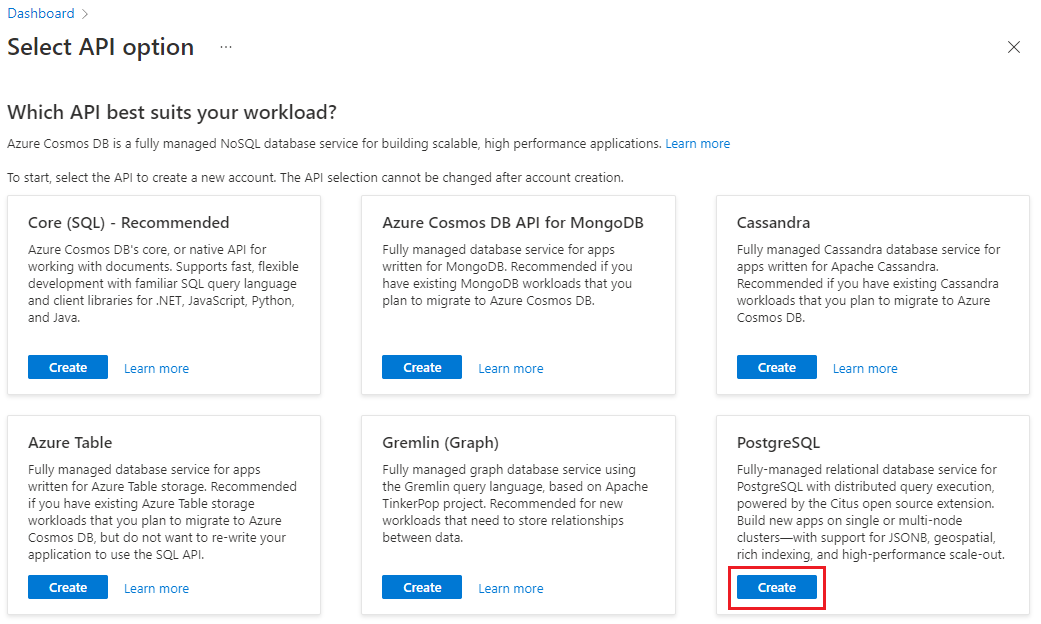
在“创建适用于 PostgreSQL 的 Azure Cosmos DB 群集”窗体上:
在“基本信息”选项卡上填写相关信息。
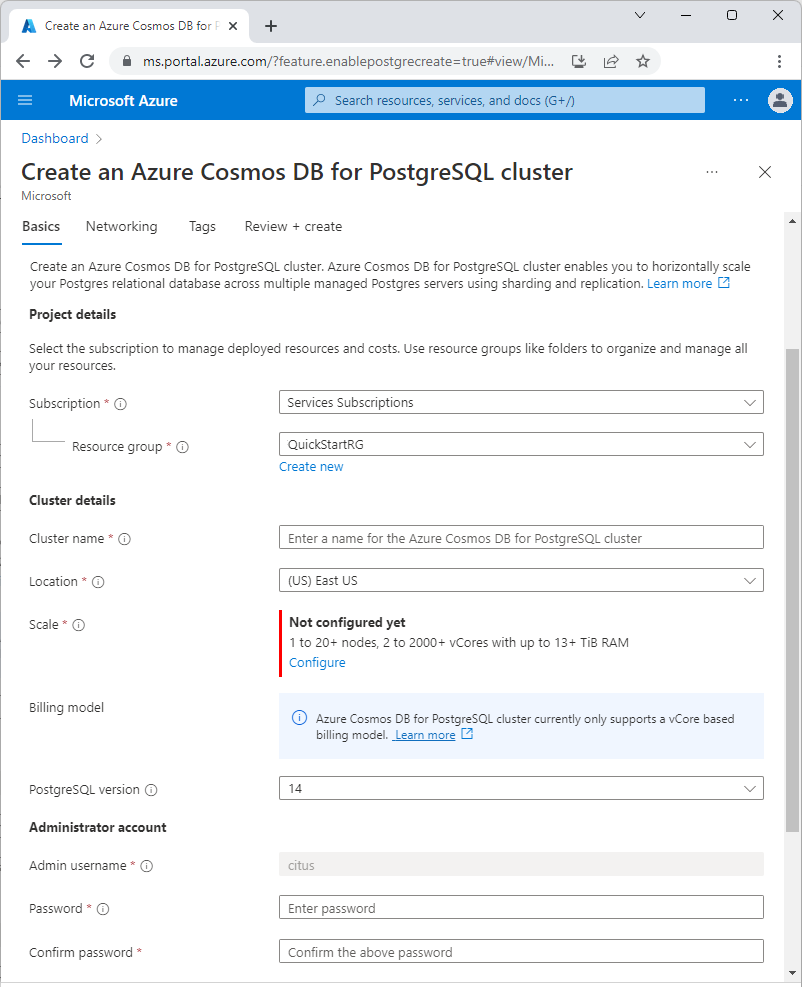
大多数选项都是一目了然的,但请记住:
- 群集名称决定应用程序用来进行连接的 DNS 名称(采用
<node-qualifier>-<clustername>.<uniqueID>.postgres.database.chinacloudapi.cn格式)。 - 可以选择主要 PostgreSQL 版本,例如 15。 Azure Cosmos DB for PostgreSQL 始终支持所选主要 Postgres 版本的最新 Citus 版本。
- 管理员用户名必须是值
citus。 - 可以将数据库名称保留为默认值“citus”,也可以定义唯一的数据库名称。 预配群集后无法重命名数据库。
- 群集名称决定应用程序用来进行连接的 DNS 名称(采用
在屏幕底部选择“下一步: 网络”。
在“网络”屏幕中,选择“允许从 Azure 内的 Azure 服务和资源公开访问此群集”。
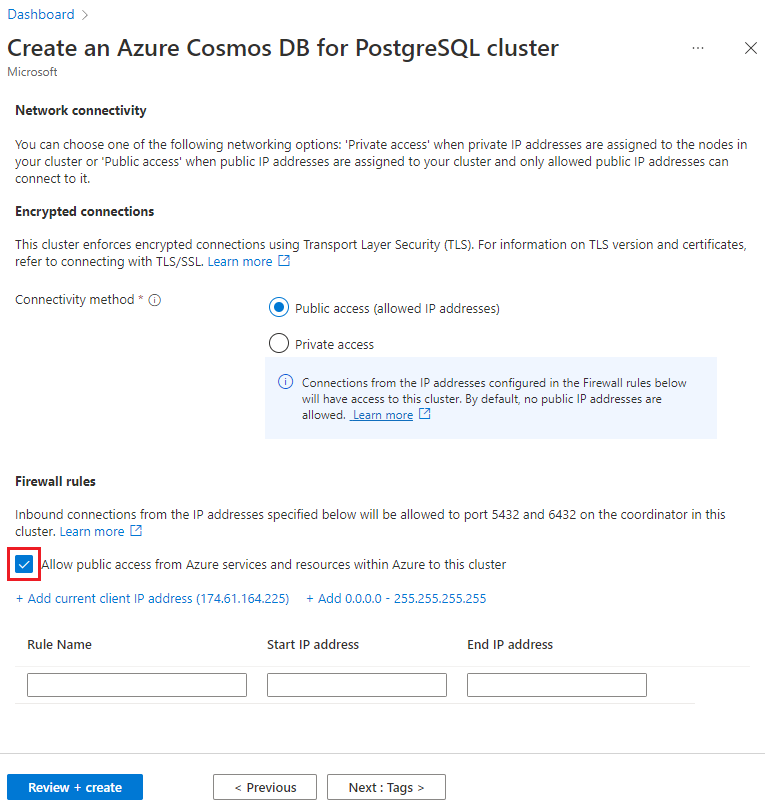
选择“查看 + 创建”,在验证通过时,选择“创建”以创建群集。
预配需要数分钟。 页面会重定向,以监视部署。 当状态从“部署进行中”更改为“部署已完成”时,请选择“转到资源”。
使用 psql 实用工具创建架构
使用 psql 连接到适用于 PostgreSQL 的 Azure Cosmos DB 后,可以完成一些基本任务。 本教程将指导你创建 Web 应用,该应用允许广告厂商跟踪他们的广告系列。
多家公司可以使用该应用,让我们创建一个表来记录这些公司,创建另一个表来记录他们的广告系列。 在 psql 控制台中,运行这些命令:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
每个广告系列会支付运行广告的费用。 此外,添加用于广告的一个表,方法是在以上代码后,运行以下代码:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
最后,我们将跟踪有关每个广告的点击次数和展示次数的统计信息:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
现在,你可以在 psql 中看到表列表中新建的表,方法是运行:
\dt
多租户应用程序仅可以对每个租户强制实施唯一性,因此所有主键和外键包含公司 ID。
在节点之间将表分片
适用于 PostgreSQL 的 Azure Cosmos DB 部署基于用户指定的列的值存储不同节点上的表行。 此“分布列”标记哪个租户拥有哪些行。
让我们将分布列设置为 company_id,即租户标识符。 在 psql 中运行以下函数:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
重要
需要分发表或使用基于架构的分片才能利用 Azure Cosmos DB for PostgreSQL 性能功能。 如果不分发表或架构,则工作器节点无法帮助运行涉及其数据的查询。
引入示例数据
现在,在 psql 外部,在常规命令行中,下载示例数据集:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
返回到 psql 内部,大容量加载数据。 请务必在下载数据文件的目录中运行 psql。
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
现在,此数据将跨工作器节点分布。
查询租户数据
当应用程序请求单个租户的数据时,数据库可以在单个工作器节点上执行查询。 单租户查询根据单个租户 ID 进行筛选。 例如,以下查询针对 company_id = 5 筛选广告和展示次数。 尝试在 psql 中运行它并查看结果。
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
租户之间共享数据
到目前为止,已按照 company_id 分发所有表。 但一些数据不会“自然地”属于任何租户,并且这些数据可以共享。 例如,示例广告平台中的所有公司可能需要获取基于 IP 地址的受众地理位置信息。
创建一个表来记录共享地理位置信息。 在 psql 中运行以下命令:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
接下来,将 geo_ips 设置为“引用表”,存储每个工作器节点上的表副本。
SELECT create_reference_table('geo_ips');
将它和示例数据一同加载。 请记住要从下载数据集的目录内部运行此命令。
\copy geo_ips from 'geo_ips.csv' with csv
将单击次数表和 geo_ips 联接,这在所有节点上都是高效的。 以下是一个用于查找点击广告 290 的所有人的位置的联接。请尝试在 psql 中运行查询。
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
自定义每租户架构
每个租户可能需要存储他人不需要的特殊信息。 但是,所有租户都共享具有相同数据库架构的同一基础结构。 额外的数据可以到哪儿去?
一个技巧是使用开放式列类型,例如 PostgreSQL 的 JSONB。 我们的架构在 clicks 中有一个 JSONB 字段,称为 user_data。
一家公司(例如 company five)可以使用列来跟踪用户是否使用移动设备。
以下查询用于发现是移动设备访客还是传统访客的点击次数更高。
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
可以为单个公司优化此查询,方法是创建部分索引。
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
更概括地说,我们可以在列中的每个键和值上创建 GIN 索引。
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
清理资源
在前面的步骤中,你已在群集中创建了 Azure 资源。 如果你认为以后不需要这些资源,请删除该群集。 在群集的“概述”页中,选择“删除”按钮。 弹出页面上出现提示时,请确认群集的名称,然后选择最后一个“删除”按钮。
后续步骤
在本教程中,你已了解如何预配群集。 你已使用 psql 连接到该组,创建了架构并分布了数据。 你已了解如何在租户中和租户之间查询数据,以及如何自定义每租户架构。