适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
本文概述了如何从 Hadoop 分布式文件系统 (HDFS) 服务器复制数据。 若要了解详细信息,请阅读
支持的功能
此 HDFS 连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| 复制操作 (source/-) | (1) (2) |
| 查询活动 | (1) (2) |
| 删除活动 | (1) (2) |
(1) Azure集成运行时 (2) 自承载集成运行时
具体而言,HDFS 连接器支持:
- 使用 Windows (Kerberos) 或 Anonymous 身份验证复制文件。
- 使用 webhdfs 协议或 内置 DistCp 支持来复制文件。
- 按原样复制文件,或者通过解析或生成文件的方式,使用支持的文件格式和压缩编解码器来复制文件。
先决条件
如果数据存储位于本地网络、Azure虚拟网络或 Amazon 虚拟私有云中,则需要配置自承载集成运行时以连接到它。
如果数据存储是托管的云数据服务,则可以使用Azure Integration Runtime。 如果访问仅限于防火墙规则中批准的 IP,则可以将 Azure Integration Runtime IP 添加到允许列表。
还可以在 Azure Data Factory 中使用 托管虚拟网络集成运行时功能访问本地网络,而无需安装和配置自承载集成运行时。
要详细了解网络安全机制和数据工厂支持的选项,请参阅数据访问策略。
注意
请确保集成运行时可以访问 Hadoop 群集的所有 [名称节点服务器]:[名称节点端口] 和 [数据节点服务器]:[数据节点端口]。 默认 [名称节点端口] 为 50070,默认 [数据节点端口] 为 50075。
开始
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建到 HDFS 的链接服务
使用以下步骤在 Azure 门户 UI 中创建指向 HDFS 的链接服务。
浏览到Azure Data Factory或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索“HDFS”并选择 HDFS 连接器。
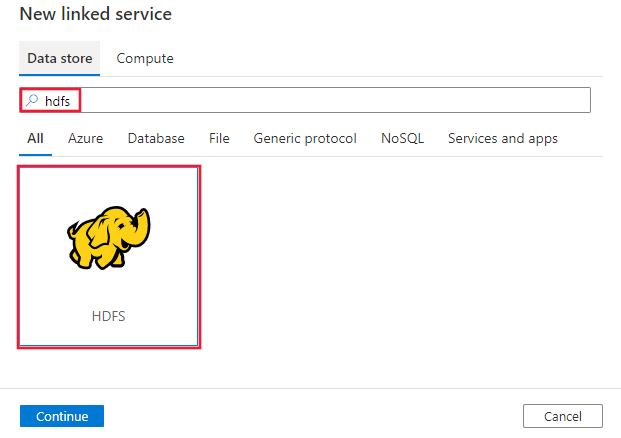
配置服务详细信息、测试连接并创建新的链接服务。
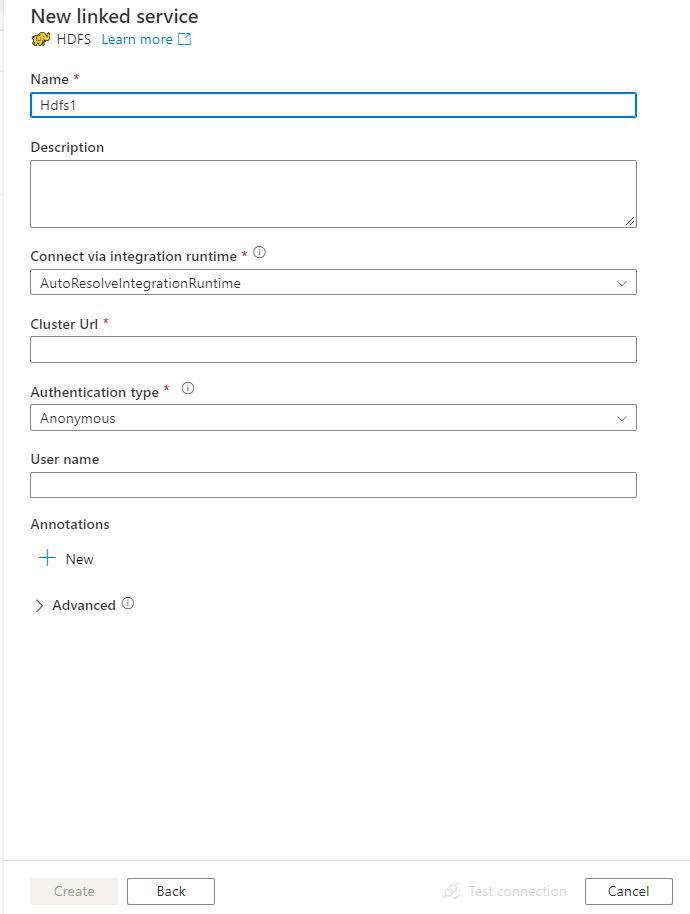
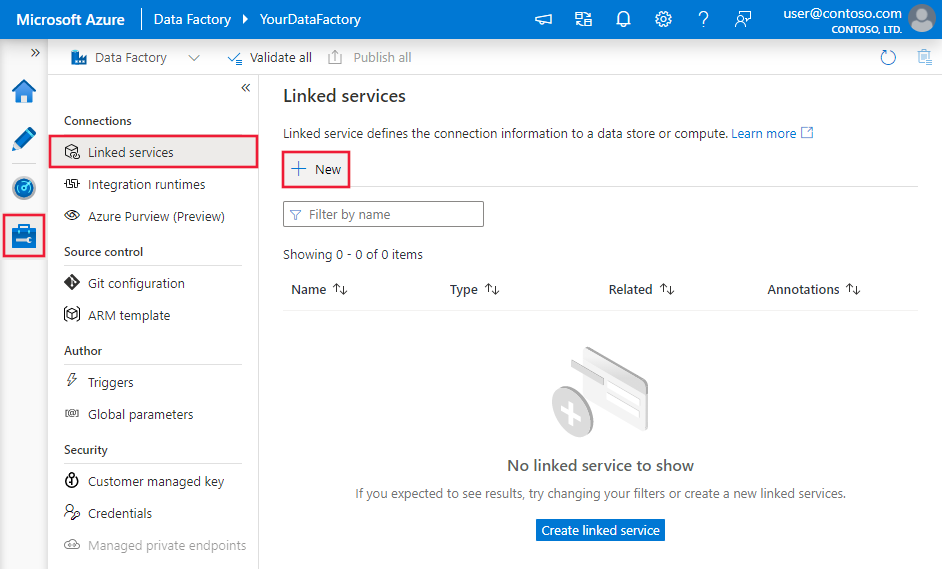
连接器配置详细信息
对于特定于 HDFS 的数据工厂实体,以下部分提供有关用于定义这些实体的属性的详细信息。
连接的服务属性
HDFS 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 Hdfs。 | 是 |
| url | HDFS 的 URL | 是 |
| 认证类型 | 允许的值为 Anonymous 或 Windows。 若要设置本地环境,请参阅对 HDFS 连接器使用 Kerberos 身份验证部分。 |
是 |
| userName | Windows 身份验证的用户名。 对于 Kerberos 身份验证,请指定 <username>@<domain>.com。 | 是(用于Windows身份验证) |
| 密码 | Windows身份验证的密码。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure 密钥保管库中的机密。 | 是(对于Windows身份验证) |
| connectVia | 用于连接到数据存储的集成运行时。 若要了解详细信息,请参阅先决条件部分。 如果未指定integration runtime,服务将使用默认Azure Integration Runtime。 | 否 |
示例:使用匿名身份验证
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:使用 Windows 认证
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
若要查看可用于定义数据集的各部分和属性的完整列表,请参阅数据集。
Azure Data Factory支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
HDFS 支持在基于格式的数据集的 location 设置下的以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集中 下的 type 属性必须设置为 HdfsLocation。 | 是 |
| folderPath | 文件夹的路径。 如果要使用通配符来筛选文件夹,请跳过此设置并在活动源设置中指定路径。 | 否 |
| 文件名 | 指定的 folderPath 下的文件名。 如果要使用通配符来筛选文件,请跳过此设置并在活动源设置中指定文件名。 | 否 |
示例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
复制活动 属性
有关可用于定义活动的各个部分和属性的完整列表,请参阅管道和活动。 本部分提供 HDFS 源支持的属性列表。
以 HDFS 作为源
Azure Data Factory支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
HDFS 支持基于格式的复制源中 storeSettings 设置下的以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 |
type 属性在 storeSettings 下必须设置为 HdfsReadSettings。 |
是 |
| 找到要复制的文件 | ||
| 选项 1:静态路径 |
从数据集中指定的文件夹或文件路径复制。 若要复制文件夹中的所有文件,请另外将 wildcardFileName 指定为 *。 |
|
| 选项 2:通配符 - wildcardFolderPath |
带有通配符的文件夹路径,用于筛选源文件夹。 允许的通配符为: *(匹配零个或更多字符)和 ?(匹配零个或单个字符)。 如果实际文件夹名称中包含通配符或此转义字符,请使用 ^ 进行转义。 如需更多示例,请参阅文件夹和文件筛选器示例。 |
否 |
| 选项 2:通配符 - 通配符文件名 |
指定的 folderPath/wildcardFolderPath 下带有通配符的文件名,用于筛选源文件。 允许的通配符为: *(匹配零个或多个字符)和?(匹配零个或单个字符);如果实际文件名中包含通配符或该转义字符,请使用^进行转义。 如需更多示例,请参阅文件夹和文件筛选器示例。 |
是 |
| 选项 3:文件列表 - 文件列表路径 |
表示要复制指定文件集。 指定一个文本文件,其中包括要复制的文件列表(每行一个文件,并包含相对于数据集中配置路径的相对路径)。 使用此选项时,请不要在数据集中指定文件名。 如需更多示例,请参阅文件列表示例。 |
否 |
| 其他设置 | ||
| recursive | 指示是要从子文件夹中以递归方式读取数据,还是只从指定的文件夹中读取数据。 当 recursive 设置为 true 且接收器是基于文件的存储时,将不会在接收器上复制或创建空的文件夹或子文件夹。 允许的值为 true(默认值)和 false。 如果配置 fileListPath,则此属性不适用。 |
否 |
| 完成后删除文件 | 指示是否会在二进制文件成功移到目标存储后将其从源存储中删除。 文件删除按文件进行。因此,当复制活动失败时,你会看到一些文件已经复制到目标并从源中删除,而另一些文件仍保留在源存储中。 此属性仅在二进制文件复制方案中有效。 默认值:false。 |
否 |
| 修改日期时间起始 | 文件根据“上次修改时间”属性进行筛选。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。如果配置 fileListPath,则此属性不适用。 |
否 |
| 修改日期时间结束 | 同上。 | |
| enablePartitionDiscovery | 对于已分区的文件,请指定是否从文件路径分析分区,并将它们添加为附加的源列。 允许的值为 false(默认)和 true 。 |
否 |
| 分区根路径 | 启用分区发现时,请指定绝对根路径,以便将已分区文件夹读取为数据列。 如果未指定,默认情况下, - 在数据集或源的文件列表中使用文件路径时,分区根路径是在数据集中配置的路径。 - 使用通配符文件夹筛选器时,分区根路径是第一个通配符前的子路径。 例如,假设你将数据集中的路径配置为“root/folder/year=2020/month=08/day=27”: - 如果将分区根路径指定为“root/folder/year=2020”,则除了文件内的列外,复制活动还将生成另外两个列 month 和 day,其值分别为“08”和“27”。- 如果未指定分区根路径,则不会生成额外的列。 |
否 |
| 最大并发连接数 (maxConcurrentConnections) | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
| DistCp 设置 | ||
| distcpSettings | 使用 HDFS DistCp 时将使用的属性组。 | 否 |
| 资源管理器端点 | YARN (Yet Another Resource Negotiator) 终结点 | 是(如果使用 DistCp) |
| tempScriptPath | 用于存储临时 DistCp 命令脚本的文件夹路径。 脚本文件将生成并在复制作业完成后删除。 | 是(如果使用 DistCp) |
| distcpOptions | 提供给 DistCp 命令的其他选项。 | 否 |
示例:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
文件夹和文件筛选器示例
本部分介绍了对文件夹路径和文件名使用通配符筛选器时产生的行为。
| folderPath | 文件名 | recursive | 源文件夹结构和筛选器结果(用粗体表示的文件已检索) |
|---|---|---|---|
Folder* |
(为空,使用默认值) | 假 | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(为空,使用默认值) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
假 | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
文件列表示例
本部分介绍使用Copy activity源中的文件列表路径导致的行为。 假设有以下源文件夹结构,并且要复制粗体类型的文件:
| 示例源结构 | FileListToCopy.txt 中的内容 | 配置 |
|---|---|---|
| 根 FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv 元数据 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
在数据集中: - 文件夹路径: root/FolderA在复制活动的源中: - 文件列表路径: root/Metadata/FileListToCopy.txt 文件列表路径指向同一数据存储中的一个文本文件,该文件包含要复制的文件列表(每行一个文件,带有数据集中所配置路径的相对路径)。 |
使用 DistCp 从 HDFS 复制数据
DistCp 是 Hadoop 本机命令行工具,用于在 Hadoop 群集中进行分布式复制。 在 Distcp 中运行某个命令时,该命令首先列出要复制的所有文件,然后在 Hadoop 群集中创建多个 Map 作业。 每个 Map 作业会将数据以二进制格式从源复制到接收器。
Copy activity 支持使用 DistCp 将文件按原样复制到 Azure Blob 存储(包括 分段复制)。 在这种情况下,DistCp 可以利用群集的功能,而不必在自承载集成运行时上运行。 使用 DistCp 可以提供更高的复制吞吐量,尤其是在群集非常强大的情况下。 根据配置,Copy activity会自动构造 DistCp 命令,将其提交到 Hadoop 群集,并监视复制状态。
先决条件
若要使用 DistCp 将文件从 HDFS 复制到 Azure Blob 存储(包括暂存复制),请确保 Hadoop 群集满足以下要求:
启用了 MapReduce 和 YARN 服务。
YARN 版本为 2.5 或更高版本。
HDFS 服务器与目标数据存储集成:Azure Blob 存储:
自 Hadoop 2.7 以来,Azure Blob FileSystem 得到原生支持。 只需在 Hadoop 环境配置中指定 JAR 路径即可。
在 HDFS 中准备临时文件夹。 此临时文件夹用于存储 DistCp shell 脚本,因此会占用 KB 级的空间。
确保 HDFS 链接服务中提供的用户帐户具有以下权限:
- 在 YARN 中提交应用程序。
- 在临时文件夹下创建一个子文件夹和读/写文件。
配置
如需与 DistCp 相关的配置和示例,请参阅以 HDFS 作为源部分。
对 HDFS 连接器使用 Kerberos 身份验证
可以通过两个选项来设置本地环境,以便对 HDFS 连接器使用 Kerberos 身份验证。 你可以选择更适合自己情况的选项。
对于任一选项,确保为 Hadoop 集群启用 webhdfs:
为 webhdfs 创建 HTTP 主体和密钥表。
重要
根据 Kerberos HTTP SPNEGO 规范,HTTP Kerberos 主体必须以“HTTP/”开头。 可从此处了解详细信息。
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS 配置选项:在
hdfs-site.xml中添加以下三个属性。<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
方法 1:在 Kerberos 领域中加入自承载集成运行时计算机
要求
- 自承载集成运行时计算机需要加入 Kerberos 领域,并且无法加入任何 Windows 域。
配置方式
在 KDC 服务器上:
创建主体并指定密码。
重要
用户名应不包含主机名。
Kadmin> addprinc <username>@<REALM.COM>
在自托管集成运行时计算机上:
运行 Ksetup 实用工具来配置 Kerberos 密钥分发中心 (KDC) 服务器和领域。
计算机必须配置为工作组的成员,因为 Kerberos 领域不同于Windows域。 可运行以下命令来设置 Kerberos 领域和添加 KDC 服务器,以便实现此配置。 将 REALM.COM 替换为你自己的领域名称。
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>运行上述命令后,重启计算机。
使用
Ksetup命令验证配置。 输出应如下所示:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
在数据工厂或 Synapse 工作区中:
- 使用 Windows authentication 和 Kerberos 主体名称和密码来配置 HDFS 连接器,以连接到 HDFS 数据源。 有关配置详细信息,请查看 HDFS 链接服务属性部分。
选项 2:启用 Windows 域与 Kerberos 域之间的相互信任
要求
- 自主托管集成运行时计算机必须加入 Windows 域。
- 更新域控制器设置需要权限。
配置方式
注意
将以下教程中的 REALM.COM 和 AD.COM 替换为你自己的领域名和域控制器。
在 KDC 服务器上:
编辑 krb5.conf 文件中的 KDC 配置,以便 KDC 通过引用以下配置模板信任Windows域。 默认情况下,配置位于 /etc/krb5.conf。
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }在配置此文件后,重启 KDC 服务。
在 KDC 服务器中使用以下命令准备名为“krbtgt/REALM.COM@AD.COM”的主体:
Kadmin> addprinc krbtgt/REALM.COM@AD.COM在 hadoop.security.auth_to_local HDFS 服务配置文件中,添加
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//。
在域控制器上:
运行以下
Ksetup命令以添加领域条目:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM建立从Windows域到Kerberos域的信任。 [password] 是主体 krbtgt/REALM.COM@AD.COM 的密码。
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]选择在 Kerberos 中使用的加密算法。
a. 选择 Server Manager>Group Policy Management>Domain>组策略对象>默认或活动域策略,然后选择编辑。
b. 在 Group 策略管理编辑器窗格中,选择 Computer Configuration>Policies>Windows Settings>Security Settings>Local Policies>Security Options, 然后配置 Network 安全性:配置 Kerberos 允许的加密类型。
c. 选择需要在连接到 KDC 服务器时使用的加密算法。 可以选择所有选项。
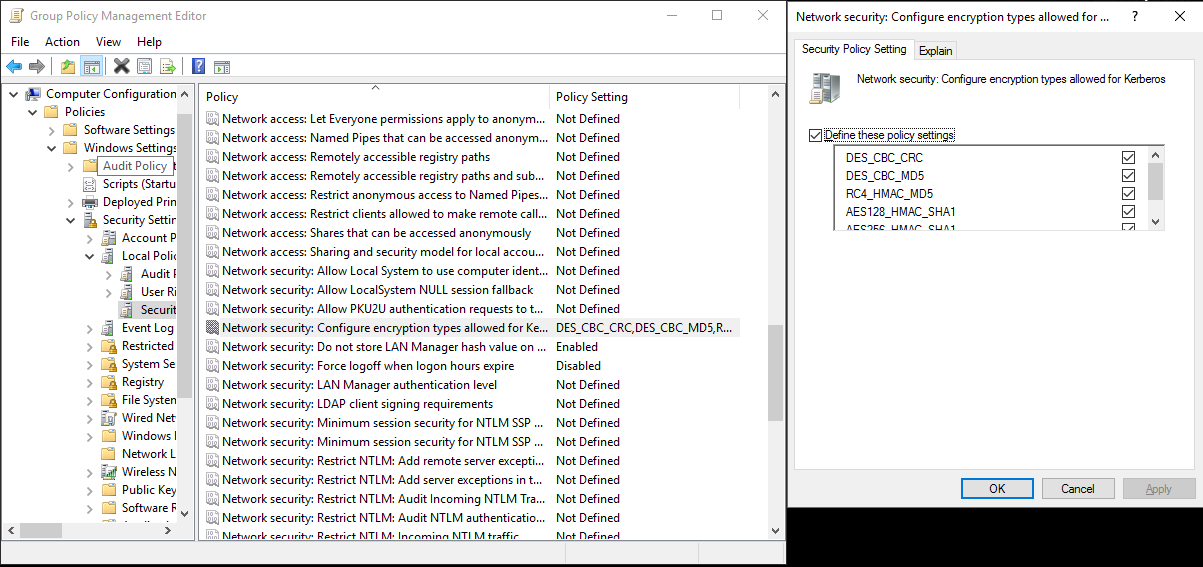
d. 使用
Ksetup命令可指定要在指定领域使用的加密算法。C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96在域帐户和 Kerberos 主体之间创建映射,以便在Windows域中使用 Kerberos 主体。
a. 选择 管理工具>Active Directory 用户和计算机。
b. 选择视图下的>以配置高级功能。
c. 在“高级功能”窗格中,右键单击要创建映射的帐户,然后在“名称映射”窗格中选择“Kerberos 名称”选项卡 。
d. 从领域中添加主体。
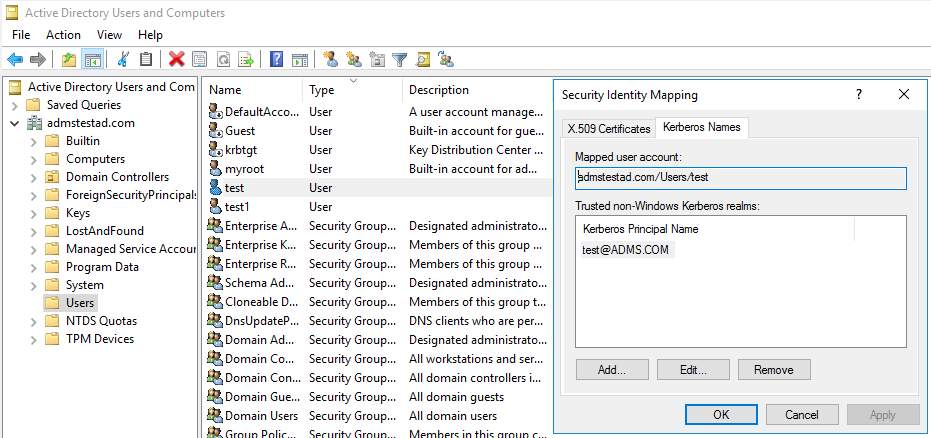
在自托管集成运行时计算机上:
运行以下
Ksetup命令以添加领域条目。C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
在数据工厂或 Synapse 工作区中:
- 使用 Windows authentication,通过域帐户或 Kerberos 主体,配置 HDFS 连接器以连接到 HDFS 数据源。 有关配置详细信息,请参阅 HDFS 链接服务属性部分。
查找活动属性
有关 Lookup 活动属性的详细信息,请参阅 Lookup 活动。
删除活动属性
有关 Delete 活动属性的详细信息,请参阅 Delete 活动。
传统模型
注意
仍会按原样支持以下模型,以实现后向兼容性。 建议你使用前面讨论的新模型,因为创作 UI 已切换到生成新模型。
旧数据集模型
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 FileShare | 是 |
| folderPath | 文件夹的路径。 支持通配符筛选功能。 允许的通配符为 *(匹配零个或多个字符)和 ?(匹配零个或一个字符);如果实际文件名中包含通配符或此转义字符,请使用 ^ 进行转义。 示例:“rootfolder/subfolder/”,请参阅文件夹和文件筛选器示例中的更多示例。 |
是 |
| 文件名 | 指定的“folderPath”下的文件的名称或通配符筛选器。 如果没有为此属性指定任何值,则数据集会指向文件夹中的所有文件。 对于筛选器,允许的通配符为 *(匹配零个或零个以上的字符)和 ?(匹配零个或单个字符)。- 示例 1: "fileName": "*.csv"- 示例 2: "fileName": "???20180427.txt"如果实际文件夹名称中包含通配符或此转义字符,请使用 ^ 进行转义。 |
否 |
| 修改日期时间起始 | 文件根据“上次修改时间”属性进行筛选。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 请注意,当你要对大量文件应用文件筛选器时,启用此设置会影响数据移动的整体性能。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。 |
否 |
| 修改日期时间结束 | 文件根据“上次修改时间”属性进行筛选。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 请注意,当你要对大量文件应用文件筛选器时,启用此设置会影响数据移动的整体性能。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。 |
否 |
| 格式 | 若要在基于文件的存储之间按原样复制文件(二进制副本),可以在输入和输出数据集定义中跳过格式节。 若要分析具有特定格式的文件,以下是受支持的文件格式类型:TextFormat、JsonFormat、AvroFormat、OrcFormat、ParquetFormat 。 请将格式中的“type”属性设置为上述值之一。 有关详细信息,请参阅文本格式、JSON 格式、Avro 格式、ORC 格式和 Parquet 格式部分。 |
否(仅适用于二进制复制方案) |
| 压缩 | 指定数据的压缩类型和级别。 有关详细信息,请参阅受支持的文件格式和压缩编解码器。 支持的类型包括:Gzip、Deflate、Bzip2 和 ZipDeflate。 支持的级别为:“最佳”和“最快” 。 |
否 |
提示
如需复制文件夹下的所有文件,请仅指定 folderPath。
要复制具有指定名称的单个文件,请指定文件夹路径为folderPath,文件名为fileName。
如需复制文件夹下的文件子集,请指定文件夹部分的 folderPath 和通配符筛选器部分的 fileName。
示例:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
旧版Copy activity源模型
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制操作源的 type 属性必须设置为 HdfsSource。 | 是 |
| recursive | 指示是要从子文件夹中以递归方式读取数据,还是只从指定的文件夹中读取数据。 当 recursive 设置为 true 且接收器是基于文件的存储时,将不会在接收器上复制或创建空的文件夹或子文件夹。 允许的值为 true(默认值)和 false。 |
否 |
| distcpSettings | 使用 HDFS DistCp 时的属性组。 | 否 |
| 资源管理器端点 | YARN Resource Manager终结点 | 是(如果使用 DistCp) |
| tempScriptPath | 用于存储临时 DistCp 命令脚本的文件夹路径。 脚本文件将生成并在复制作业完成后删除。 | 是(如果使用 DistCp) |
| distcpOptions | 提供给 DistCp 命令的其他选项。 | 否 |
| 最大并发连接数 (maxConcurrentConnections) | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:在复制活动中使用 DistCp 的 HDFS 源
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
相关内容
有关 Copy 活动支持的作为源和汇的数据存储列表,请参阅 支持的数据存储。