本页介绍了 Azure Databricks 如何使用 Lakeguard 在共享计算环境中强制实施用户隔离,以及专用计算中的精细访问控制。
什么是 Lakeguard?
Lakeguard 是 Databricks 上的一组技术,旨在强制实施代码隔离和数据过滤,使多个用户能够安全且经济高效地共享同一计算资源,并在计算服务上应用精细的访问控制以实现数据访问,同时提供特权机器访问权限。
Lakeguard 的工作原理是什么?
在标准经典计算、无服务器计算和 SQL 仓库等共享计算环境中,Lakeguard 将用户代码与 Spark 引擎和其他用户隔离开来。 此设计使许多用户能够共享相同的计算资源,同时在用户、Spark 驱动程序和执行程序之间保持严格的边界。
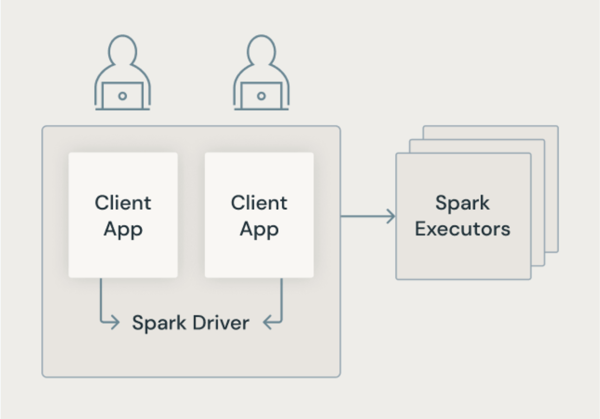
经典 Spark 体系结构
下图显示了传统 Spark 体系结构中用户应用程序如何共享具有对基础计算机的特权访问权限的 JVM。
Lakeguard 体系结构
Lakeguard 使用安全容器隔离所有用户代码。 这样,多个工作负荷就可以在同一计算资源上运行,同时保持用户之间的严格隔离。
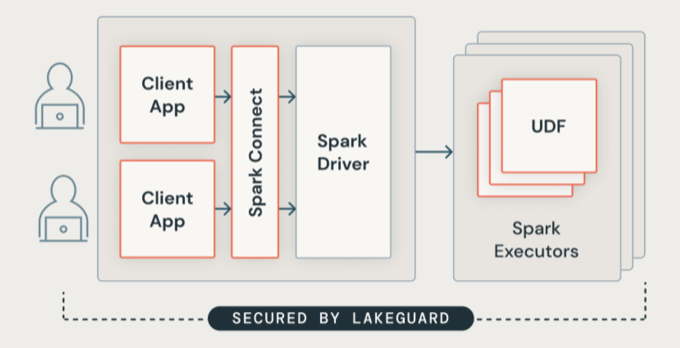
Spark 客户端隔离
Lakeguard 使用两个关键组件将客户端应用程序与 Spark 驱动程序相互隔离:
Spark Connect:Lakeguard 使用 Spark Connect(Apache Spark 3.4 引入)将客户端应用程序与驱动程序分离。 客户端应用程序和驱动程序不再共享相同的 JVM 或类路径。 这种分离可防止未经授权的数据访问。 此设计还可防止用户在查询包括行级或列级筛选器时访问因过度提取而生成的数据。
注释
Spark Connect 将分析和名称解析推迟到执行时间,这可能会更改代码的行为。 请参阅 “将 Spark 连接与 Spark 经典版进行比较”。
容器沙盒:每个客户端应用程序在其自己的独立容器环境中运行。 这样可以防止用户代码访问其他用户的数据或基础计算机。 沙盒使用基于容器的隔离技术在用户之间创建安全边界。
UDF 隔离
默认情况下,Spark 执行程序不会隔离 UDF。 这种缺乏隔离可以允许 UDF 写入文件或访问基础计算机。
Lakeguard 通过以下方法隔离 Spark 执行程序上的用户定义的代码,包括 UDF:
- 在 Spark 执行程序上沙盒执行环境。
- 隔离来自 UDF 的出口网络流量,以防止未经授权的外部访问。
- 将客户端环境复制到 UDF 沙盒中,以便用户可以访问所需的库。
此隔离适用于标准计算上的 UDF 和无服务器计算和 SQL 仓库上的 Python UDF。