本页介绍 Databricks 功能存储的工作原理和定义重要术语。
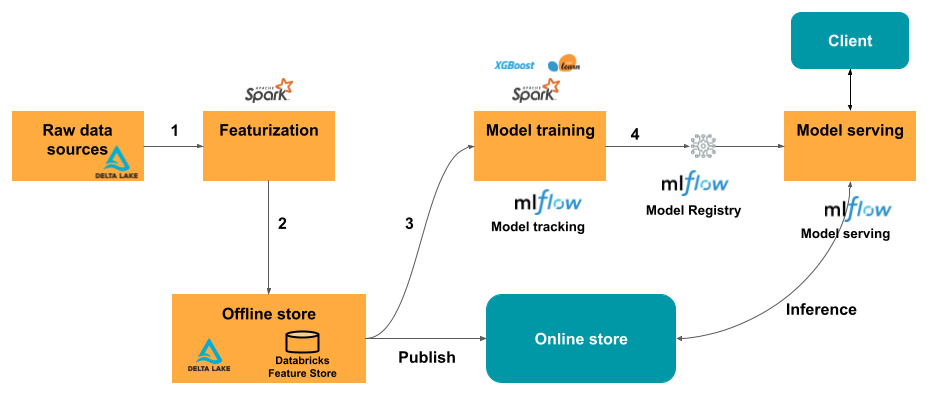
Databricks 的特征工程如何运作?
在 Databricks 上使用特征工程的典型机器学习工作流遵循以下路径:
编写代码以将原始数据转换为功能,并创建包含所需功能的 Spark 数据帧。
在 Unity 目录中创建 具有主键的 Delta 表。
使用特征表训练和记录模型。 执行此作时,模型存储用于训练的功能规范。 当模型用于推理时,它会自动联接相应特征表中的功能。
在 模型注册表中注册模型。
现在可以使用模型对新数据进行预测。 对于批处理用例,模型会自动从功能存储中检索所需的功能。
对于实时服务用例,请将这些功能发布到联机功能存储。
- 在推理时,服务终结点的模型会自动使用请求数据中的实体 ID 来查找来自在线商店的预计算特征,以对 ML 模型评分。 终结点使用 Unity Catalog 将数据血缘从已部署模型解析为训练模型所用的特征,并将数据血缘跟踪到联机特征存储以实现实时访问。
功能存储术语表
特征存储
功能存储是一个集中式存储库,使数据科学家能够查找和共享功能。 使用功能存储还可以确保用于计算特征值的代码在模型训练期间和模型用于推理时相同。 Databricks 上特性存储的工作原理取决于您的工作区是否启用了 Unity Catalog。
- 在为 Unity 目录启用的工作区中,可以使用 Unity 目录中包含主键约束的任何 Delta 表作为功能表。
- 在 2024 年 8 月 19 日下午 4:00:00(UTC)之前创建且未启用 Unity Catalog 的工作区可以访问旧版 工作区功能存储。
机器学习使用现有数据生成模型以预测将来的结果。 几乎所有情况下,原始数据都需要预处理和转换,然后才能用于生成模型。 此过程称为特征工程,此过程的输出称为特征 - 模型的构建基块。
开发特征非常复杂且耗时。 另一个复杂因素是,对于机器学习,需要对模型训练执行特征计算,然后在使用模型进行预测时再次执行。 这些实现可能不是由同一团队或不是使用相同的代码环境完成的,这可能会导致延迟和错误。 此外,组织中的不同团队通常具有类似的特征需求,但可能不知道其他团队所做的工作。 特征存储旨在解决这些问题。
特征表
特征以特征表的形式进行组织。 每个表必须具有主键,并由增量表和其他元数据支持。 特征表元数据用于跟踪从中生成了表的数据源,以及创建或写入该表的笔记本和作业。
使用 Databricks Runtime 13.3 LTS 及更高版本时,如果工作区已启用 Unity Catalog,可使用 Unity Catalog 中具有主键的任何 Delta 表作为特征表。 请参阅在 Unity Catalog 中处理特征表。 存储在本地工作区特征存储中的特征表称为“工作区特征表”。 请参阅使用工作区特征存储(旧版)中的特征表。
特征表中的特征通常是使用通用计算函数来计算和更新的。
可以将特征表发布到联机存储进行实时模型推理。
FeatureLookup
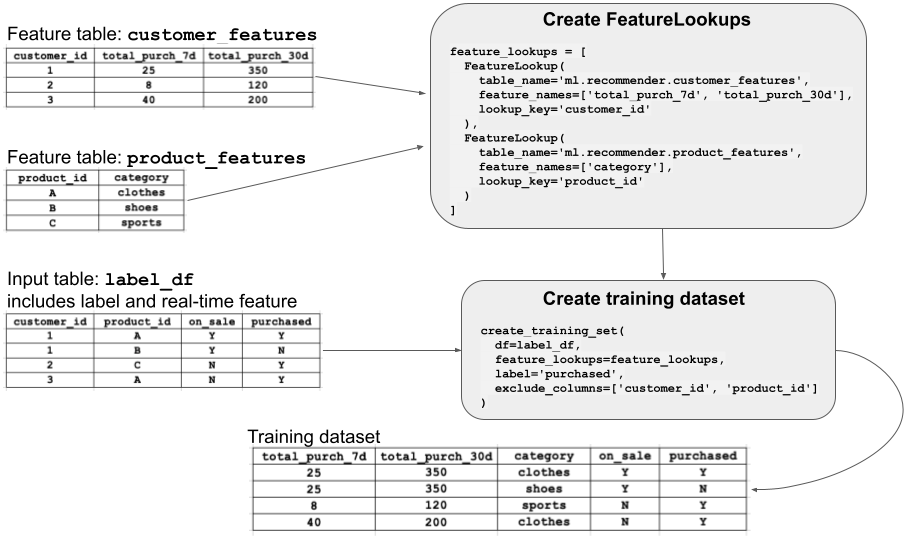
许多不同的模型可能使用特定特征表中的特征,并非所有模型都需要每个特征。 若要使用特征训练模型,请为每个特征表创建 FeatureLookup。
FeatureLookup 指定要从表中使用的特征,并定义用于将特征表联接到传递给 create_training_set 的标签数据的键。
该图说明了 FeatureLookup 的工作原理。 在此示例中,你想要使用两个特征表中的特征(customer_features 和 product_features)来训练模型。 为每个特征表创建一个 FeatureLookup,指定表的名称、要从表中选择的特征(列),以及在联接特征以创建训练数据集时使用的查找键。
然后,调用 create_training_set,如图所示。 此 API 调用指定包含原始训练数据 (label_df)、要使用的 FeatureLookups 和 label(即包含标准答案的列)的数据帧。 训练数据必须包含对应于特征表的每个主键的列。 特征表中的数据根据这些键联接到输入数据帧。 结果以“训练数据集”的形式显示在关系图中。
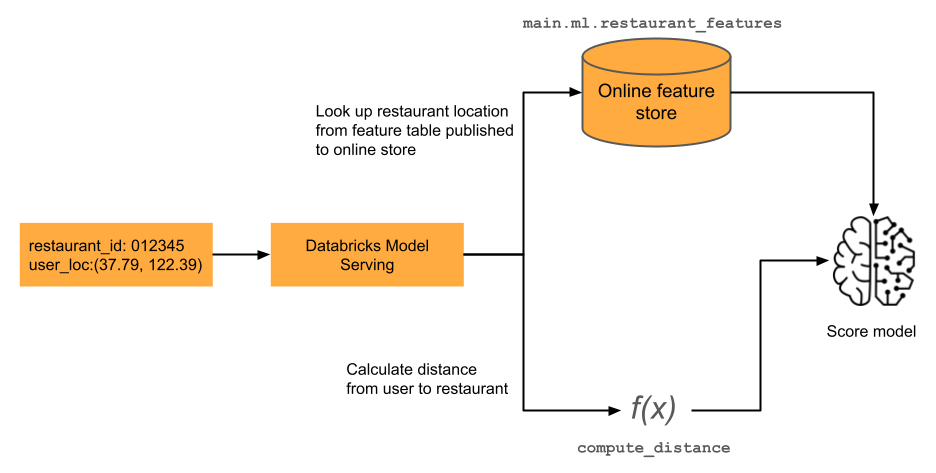
FeatureFunction
某个特征可能依赖于仅在推理时可用的信息。 你可以指定一个 FeatureFunction,该函数将实时输入与特征值相结合来计算最新的特征值。 下图中显示了一个示例。 有关详细信息,请参阅 按需功能计算。
训练集
训练集包括一个特征列表,以及一个包含原始训练数据、标签和用于查找特征的主键的数据帧。 可以通过指定要从特征存储中提取的特征来创建训练集,并在模型训练期间提供训练集作为输入。
有关如何创建和使用训练集的示例,请参阅创建训练数据集。
使用 Unity Catalog 中的特征工程训练并记录模型时,可以在目录资源管理器中查看模型的世系。 自动跟踪和显示用于创建模型的表和函数。 请参阅特征治理和世系。
FeatureSpec
Unity Catalog 实体 FeatureSpec 定义了一组可重复使用的特性和功能,用于服务。
FeatureSpecs 将特征表中的 FeatureLookups 合并成FeatureFunction单个逻辑单元,该单元可用于模型训练或使用特征服务终结点提供。
FeatureSpecs 由 Unity Catalog 存储和管理,并对其组成的脱机特性表和函数进行完整溯源跟踪。 这可实现跨不同模型和应用程序的治理、可发现性和重用性。
可通过以下方式使用:FeatureSpec
- 使用 Python API 或 REST API 创建功能服务终结点。 请参阅 功能服务终结点 ,或使用模型服务 UI 直接部署。 对于高性能应用程序,请启用路由优化。
- 在模型训练中通过引用
FeatureSpec和create_training_set使用。
FeatureSpec 始终引用脱机特性表,但必须将其发布到在线存储以进行实时服务场景。
时序特征表(时间点查找)
用于训练模型的数据通常内置了时间依赖项。 生成模型时,必须仅考虑观测到的目标值之前的特征值。 如果基于在目标值时间戳之后测量的数据对特征进行训练,模型的性能可能会受影响。
时序功能表包含时间戳列,以确保训练数据集中的每个行表示行时间戳时的最新已知特征值。 只要特征值会不断变化(例如,在使用时序数据、基于事件的数据或时间聚合数据时),就应该使用时序特征表。
创建时序功能表时,可以使用参数(适用于 Unity 目录中的功能工程)或参数(适用于工作区功能存储)将时间相关的列指定为主键中的timeseries_columns时序列timestamp_keys。 这样就可以在使用 create_training_set 或 score_batch 时启用时间点查找。 系统使用你指定的 timestamp_lookup_key 执行截至时间戳的联接。
如果不使用 timeseries_columns 参数或 timestamp_keys 参数,并且仅将时序列指定为主键列,则功能存储不会在联接期间将时间点逻辑应用于时序列。 它只匹配具有精确时间匹配项的行,而不匹配时间戳之前的所有行。
脱机存储
脱机特征存储用于特征发现、模型训练和批量推理。 它包含具体化为增量表的特征表。
流式处理
除了批量写入以外,Databricks 特征存储还支持流式处理。 可以将特征值从流式处理源写入特征表,特征计算代码可以利用结构化流式处理将原始数据流转换为特征。
还可以将特征表从脱机存储流式传输到联机存储。
模型打包
使用 Unity Catalog 或工作区特征存储中的特征工程训练机器学习模型并使用客户端的 log_model() 方法对其进行记录时,该模型会保留对这些特征的引用。 在推理时,模型可以选择性地自动检索特征值。 调用方只需提供模型中使用的特征的主键(例如 user_id),然后模型将检索全部所需的特征值。
在批量推理中,特征值是从脱机存储中检索的,并在评分之前与新数据相联接。 在实时推理中,特征值从在线商店中检索。
若要使用特征元数据打包模型,请使用 FeatureEngineeringClient.log_model (适用于 Unity Catalog 中的特征工程)或 FeatureStoreClient.log_model(适用于工作区特征存储)。