注释
本文重点介绍传统机器学习和深度学习模型的 MLflow 3 功能。 MLflow 3 还为 GenAI 应用程序开发提供全面的功能,包括跟踪、评估和人工反馈收集。 有关详细信息 ,请参阅 MLflow 3 for GenAI 。
本文介绍了如何使用 MLflow 3 开发机器学习模型。 本文介绍如何为模型安装 MLflow 3,并包括多个演示笔记本以开始使用。 它还提供了一些链接,指向详细介绍 MLflow 3 模型新功能的页面。
什么是模型 MLflow 3?
Azure Databricks 上的模型 MLflow 3 为机器学习模型提供最先进的试验跟踪、性能评估和生产管理。 MLflow 3 引入了重要的新功能,同时保留了核心跟踪概念,使从 MLflow 2.x 快速和简单迁移。
什么是 GenAI 的 MLflow 3?
除了 MLflow 3 for Models,MLflow 3 for GenAI 还引入了各种新功能和改进,用于代理和 GenAI 应用程序开发。 有关全面概述,请参阅 适用于 GenAI 的 MLflow 3。
适用于 GenAI 的 MLflow 3 中的核心功能包括:
- 跟踪和可观测性 - GenAI 应用程序的端到端可观测性,包括针对 OpenAI、LangChain、LlamaIndex 和 Anthropic 等在内的 20 多个框架的自动化工具支持。
- 评估和监控 - 全面的 GenAI 评估功能,从开发到生产阶段衡量和提高质量。 包括内置的 LLM 法官、可自定义的法官、评估数据集管理和实时监视。
- 人工反馈收集 - 用于收集域专家反馈和交互式测试代理的可自定义评审 UI,以及用于组织和跟踪评审进度的结构化标记会话
- 提示注册表 - 集中式的提示版本控制、管理和 A/B 测试,并与 Unity Catalog 集成
- 应用程序与代理版本控制 - GenAI 应用程序和代理的版本管理,包括跟踪代码修订、参数、质量评估、性能指标以及与应用程序或代理关联的跟踪。
MLflow 3 与 MLflow 2 在模型方面有何不同
Azure Databricks 上的模型 MLflow 3 使你能够:
- 集中跟踪和分析所有环境中模型的性能,从开发笔记本中的交互式查询到生产批处理或实时服务部署。
![]()
- 在所有工作区和试验中,从 Unity 目录中的模型版本页和 REST API 查看和访问模型指标和参数。
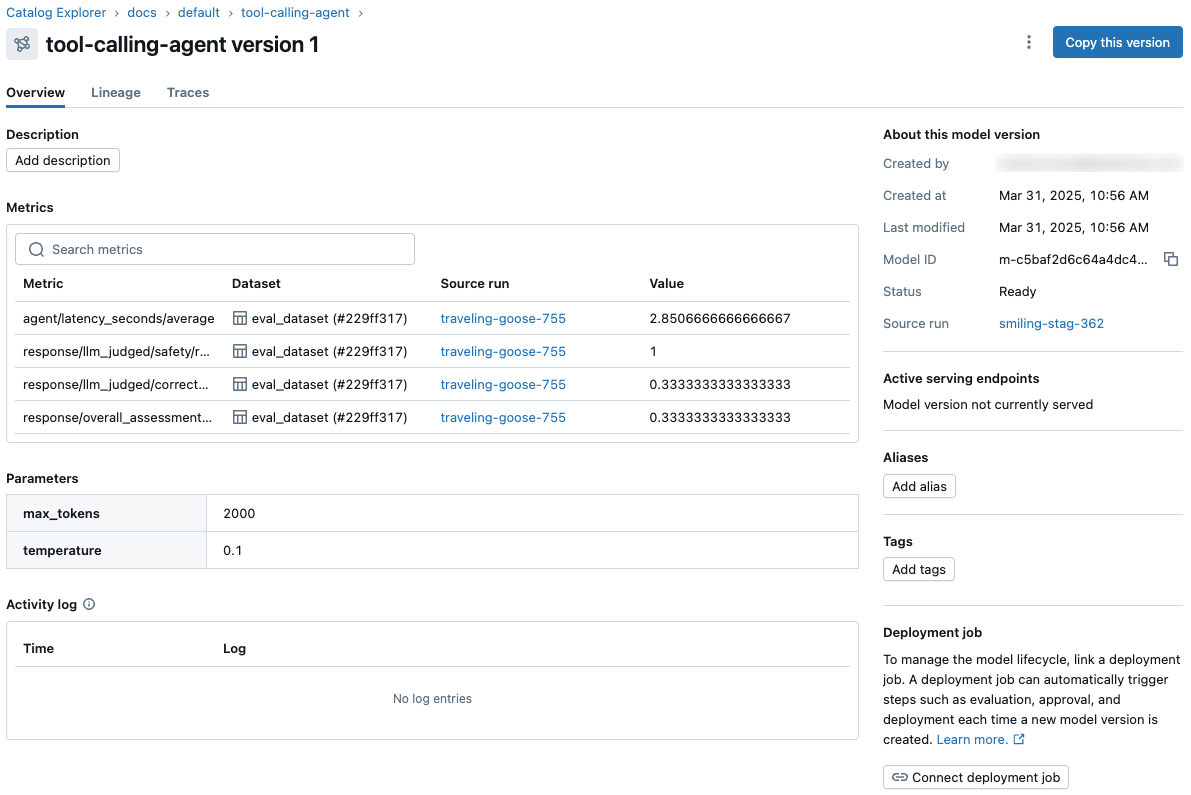
- 使用 Unity 目录协调评估和部署工作流,并访问模型的每个版本的综合状态日志。
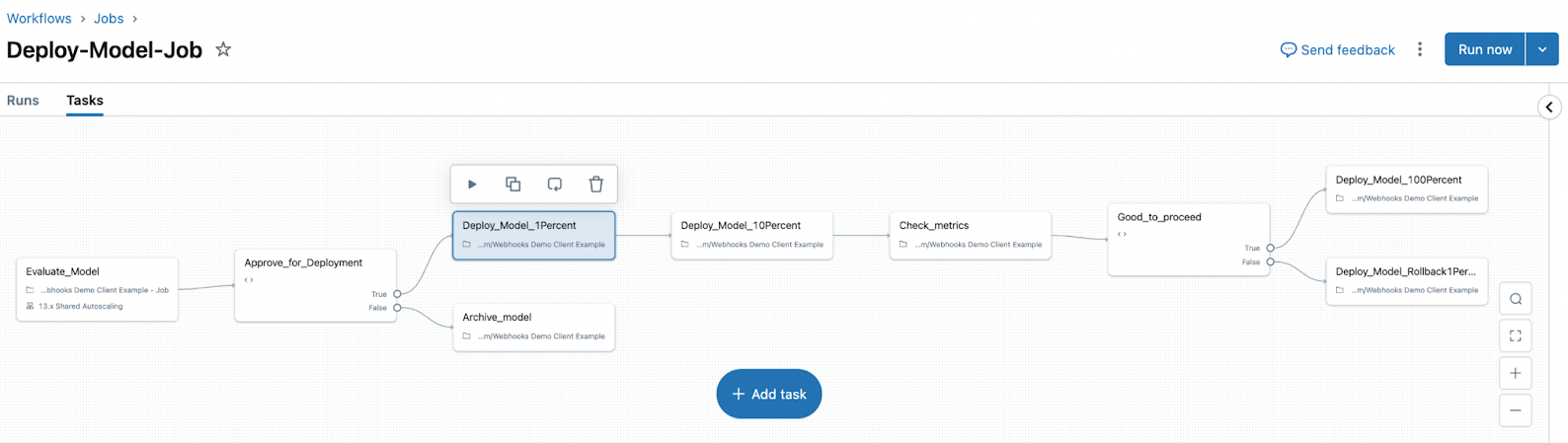
这些功能简化机器学习模型开发、评估以及生产环境部署。
已记录模型
MLflow 3 的大部分新功能都源于新 LoggedModel概念。 对于深度学习和传统机器学习模型, LoggedModels 提升训练运行生成的模型的概念,并将其确立为一个专用对象,用于跟踪不同训练和评估运行中的模型生命周期。
LoggedModels 跨开发阶段(训练和评估)以及环境(开发、过渡和生产)捕获指标、参数和跟踪。
LoggedModel被提升为 Unity 目录中的一个模型版本时,来自原始LoggedModel的所有性能数据将会在 Unity 目录的模型版本页面上显示,从而为所有工作区和试验提供可见性。 有关更多详细信息,请参阅 使用 MLflow Logged Models 跟踪和比较模型。
部署作业
MLflow 3 还引入了部署作业的概念。 部署作业使用 Lakeflow 作业来管理模型生命周期,包括评估、审批和部署等步骤。 这些模型工作流由 Unity 目录管理,所有事件都保存到 Unity 目录中的模型版本页上可用的活动日志。
从 MLflow 2.x 迁移
尽管 MLflow 3 中有许多新功能,但试验和运行的核心概念及其元数据(如参数、标记和指标)保持不变。 从 MLflow 2.x 迁移到 3.0 非常简单,在大多数情况下,这应该需要最少的代码更改。 本节着重介绍与MLflow 2.x版本相比的一些关键区别,以及为实现无缝过渡而应注意的事项。
日志记录模型
在 2.x 中记录模型时,使用 artifact_path 参数。
with mlflow.start_run():
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=python_model,
...
)
在 MLflow 3 中,请改用 name,这样以后可以按名称搜索模型。
artifact_path该参数仍受支持,但已弃用。 此外,在记录模型时,MLflow 不再需要运行处于活动状态,因为模型已成为 MLflow 3 中的一流公民。 无需首先启动运行即可直接记录模型。
mlflow.pyfunc.log_model(
name="model",
python_model=python_model,
...
)
模型工件
在 MLflow 2.x 中,模型项目作为运行项目存储在运行的项目路径下。 在 MLflow 3 中,模型工件现在存储在模型工件路径下的不同位置。
# MLflow 2.x
experiments/
└── <experiment_id>/
└── <run_id>/
└── artifacts/
└── ... # model artifacts are stored here
# MLflow 3
experiments/
└── <experiment_id>/
└── models/
└── <model_id>/
└── artifacts/
└── ... # model artifacts are stored here
建议使用mlflow.<model-flavor>.load_model并通过mlflow.<model-flavor>.log_model返回的模型 URI 来加载模型,以避免任何问题。 此模型 URI 的格式 models:/<model_id> (而不是 runs:/<run_id>/<artifact_path> 在 MLflow 2.x 中所示),如果只有模型 ID 可用,也可以手动构造。
模型注册表
在 MLflow 3 中,默认注册表 URI 现在 databricks-uc为,这意味着将使用 Unity 目录中的 MLflow 模型注册表(有关更多详细信息,请参阅 Unity 目录中的管理模型生命周期 )。 Unity 目录中注册的模型名称格式为 <catalog>.<schema>.<model>。 调用需要已注册模型名称的 API(例如mlflow.register_model)时,将使用完整的三级名称。
对于启用了 Unity Catalog 且其默认目录位于 Unity Catalog 的工作区,可以使用 作为名称,在这种情况下,将自动推断默认目录和架构(MLflow 2.x 的行为没有变化)。 如果工作区已启用 Unity 目录,但其 默认目录 未配置为位于 Unity 目录中,则需要指定完整的三级名称。
Databricks 建议使用 Unity 目录中的 MLflow 模型注册表来管理模型的生命周期。
若要继续使用 工作区模型注册表(旧版),请使用以下方法之一将注册表 URI databricks设置为:
- 使用
mlflow.set_registry_uri("databricks")。 - MLFLOW_REGISTRY_URI设置环境变量。
- 若要大规模设置注册表 URI 的环境变量,可以使用 init 脚本。 这需要 全用途计算。
其他重要更改
- MLflow 3 客户端可以加载使用 MLflow 2.x 客户端记录的所有运行、模型和跟踪。 但是,反过来不一定成立,因此使用 MLflow 3 客户端记录的模型和记录可能无法使用较旧的 2.x 客户端版本加载。
-
mlflow.evaluateAPI 已弃用。 对于传统的 ML 或深度学习模型,请使用mlflow.models.evaluate它与原始mlflow.evaluateAPI 保持完全兼容性。 对于 LLM 或 GenAI 应用程序,请改用mlflow.genai.evaluateAPI。 -
run_uuid该属性已从RunInfo对象中删除。 在代码中改为使用run_id。
安装 MLflow 3
若要使用 MLflow 3,必须更新包才能使用正确的 (>= 3.0) 版本。 每次运行笔记本时,必须执行以下代码行:
%pip install mlflow>=3.0 --upgrade
dbutils.library.restartPython()
示例笔记本
以下页面演示了用于传统 ML 和深度学习的 MLflow 3 模型跟踪工作流。 每个页面都包含一个示例笔记本。
限度
虽然 Spark 模型日志记录 (mlflow.spark.log_model) 在 MLflow 3 中继续工作,但它不使用新 LoggedModel 概念。 通过 Spark 模型日志记录的模型继续使用 MLflow 2.x 运行和运行产物。
后续步骤
若要详细了解 MLflow 3 的新功能,请参阅以下文章: