本教程演示如何使用 Apache Hive 在 Azure HDInsight 中创建 Apache HBase 群集、创建 HBase 表和查询表。 有关常规 HBase 信息,请参阅 HDInsight HBase 概述。
本教程中,您将学习如何:
- 创建 Apache HBase 群集
- 创建 HBase 表并插入数据
- 使用 Apache Hive 查询 Apache HBase
- 使用 Curl 调用 HBase REST API
- 检查群集状态
先决条件
SSH 客户端。 有关详细信息,请参阅使用 SSH 连接到 HDInsight (Apache Hadoop)。
Bash。 本文中的示例对 curl 命令使用 Windows 10 上的 Bash shell。 有关安装步骤,请参阅 适用于 Windows 10 的 Windows Subsystem for Linux 安装指南 。 其他 Unix shell 也正常工作。 curl 示例(略有修改)可以在 Windows 命令提示符下工作。 也可以使用 Windows PowerShell cmdlet Invoke-RestMethod。
创建 Apache HBase 群集
以下过程使用 Azure 资源管理器模板创建 HBase 群集。 该模板还会创建依赖的默认 Azure 存储帐户。 若要了解过程中使用的参数和其他群集创建方法,请参阅 在 HDInsight 中创建基于 Linux 的 Hadoop 群集。
选择下图以在 Azure 门户中打开模板。 该模板位于 Azure 快速入门模板中。

在 “自定义部署 ”对话框中,输入以下值:
资产 Description Subscription 选择用于创建群集的 Azure 订阅。 资源组 创建 Azure 资源管理组或使用现有资源组。 位置 指定资源组的位置。 集群名称 输入 HBase 群集的名称。 群集登录名和密码 默认登录名为 admin.SSH 用户名和密码 默认用户名为 sshuser.其他参数是可选的。
每个群集都有一个 Azure 存储帐户依赖项。 删除群集后,数据将保留在存储帐户中。 群集默认存储帐户名称是追加了“store”的群集名称。 它在模板变量部分进行硬编码。
选择 “我同意上述条款和条件”,然后选择“ 购买”。 创建群集大约需要 20 分钟。
删除 HBase 群集后,可以使用同一默认 Blob 容器创建另一个 HBase 群集。 新群集选取在原始群集中创建的 HBase 表。 为了避免不一致,建议在删除群集之前禁用 HBase 表。
创建表和插入数据
可以使用 SSH 连接到 HBase 群集,然后使用 Apache HBase Shell 创建 HBase 表、插入数据和查询数据。
对于大多数人,数据以表格格式显示:

在 HBase 中,相同的数据如下所示:

使用 HBase shell
使用
ssh命令连接到 HBase 群集。 替换以下命令中的CLUSTERNAME为您的群集名称,然后输入该命令:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.cn使用
hbase shell命令启动 HBase 交互式 shell。 在 SSH 连接中输入以下命令:hbase shell使用
create命令创建包含两列系列的 HBase 表。 表格和列的名称区分大小写。 输入以下命令:create 'Contacts', 'Personal', 'Office'使用
list命令列出 HBase 中的所有表。 输入以下命令:list使用
put命令在特定表中指定行的指定列中插入值。 输入以下命令:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'使用
scan命令扫描并返回Contacts表数据。 输入以下命令:scan 'Contacts'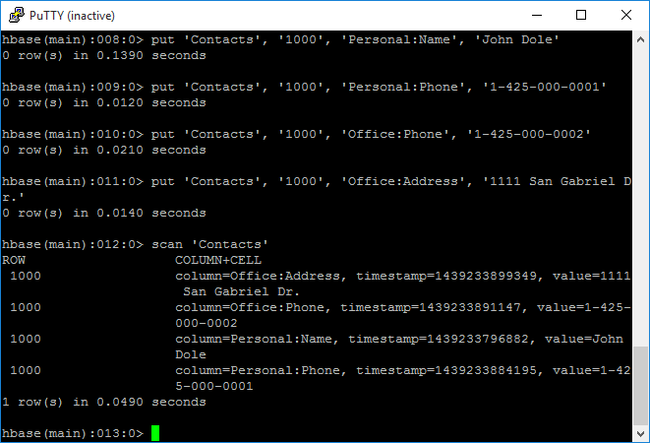
使用
get命令提取行的内容。 输入以下命令:get 'Contacts', '1000'你会看到与使用
scan命令类似的结果,因为只有一行。有关 HBase 表架构的详细信息,请参阅 Apache HBase 架构设计简介。 有关更多 HBase 命令,请参阅 Apache HBase 参考指南。
使用
exit命令停止 HBase 交互式 shell。 输入以下命令:exit
将数据批量加载到联系人 HBase 表中
HBase 包括将数据加载到表中的几种方法。 有关详细信息,请参阅 大容量加载。
可以在公共 Blob 容器 wasb://hbasecontacts@hditutorialdata.blob.core.chinacloudapi.cn/contacts.txt中找到示例数据文件。 数据文件的内容为:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
可以选择创建文本文件并将该文件上传到自己的存储帐户。 有关如何上传数据的说明,请参阅 在 HDInsight 中为 Apache Hadoop 作业上传数据。
此过程使用 Contacts 在上一过程中创建的 HBase 表。
从打开的 ssh 连接中运行以下命令,将数据文件转换为 StoreFiles,并存储在指定的
Dimporttsv.bulk.output相对路径。hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.chinacloudapi.cn/contacts.txt运行以下命令,将数据从
/example/data/storeDataFileOutputHBase 表上传到:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput Contacts可以打开 HBase shell,并使用
scan命令列出表内容。
使用 Apache Hive 查询 Apache HBase
可以使用 Apache Hive 查询 HBase 表中的数据。 在本部分中,你将创建一个 Hive 表,该表映射到 HBase 表,并使用它来查询 HBase 表中的数据。
在打开的 ssh 连接中,使用以下命令启动 Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n admin有关 Beeline 的详细信息,请参阅 将 Hive 与 HDInsight 中的 Hadoop 与 Beeline 配合使用。
运行以下 HiveQL 脚本以创建映射到 HBase 表的 Hive 表。 运行此语句之前,请确保已使用 HBase shell 创建了本文前面引用的示例表。
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');运行以下 HiveQL 脚本以查询 HBase 表中的数据:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;若要退出 Beeline,请使用
!exit。若要退出 ssh 连接,请使用
exit。
单独的 Hive 和 HBase 群集
无需从 HBase 群集执行用于访问 HBase 数据的 Hive 查询。 Hive 附带的任何群集(包括 Spark、Hadoop、HBase 或交互式查询)都可用于查询 HBase 数据,前提是已完成以下步骤:
- 这两个群集必须附加到同一虚拟网络和子网
- 从 HBase 群集头节点复制
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xml到 Hive 群集头节点和工作节点。
保护群集
也可以使用已启用 ESP 的 HBase 从 Hive 查询 HBase 数据:
- 遵循多群集模式时,两个群集都必须启用 ESP。
- 若要允许 Hive 查询 HBase 数据,请确保
hive授予用户通过 HBase Apache Ranger 插件访问 HBase 数据的权限 - 使用启用了 ESP 的单独群集时,必须将 HBase 群集头节点中的
/etc/hosts内容追加到 Hive 群集的头节点和工作节点的/etc/hosts中。
注释
缩放任一群集后,必须再次追加/etc/hosts
通过 Curl 使用 HBase REST API
HBase REST API 通过基本身份验证进行保护。 应始终使用安全 HTTP(HTTPS)发出请求,以帮助确保凭据安全地发送到服务器。
若要在 HDInsight 群集中启用 HBase REST API,请将以下自定义启动脚本添加到 “脚本作 ”部分。 可以在创建群集时或在创建群集后添加启动脚本。 对于 节点类型,请选择 “区域服务器 ”以确保脚本仅在 HBase 区域服务器中执行。 脚本在区域服务器上的 8090 端口上启动 HBase REST 代理。
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fi设置环境变量以方便使用。 通过将以下命令中的
MYPASSWORD替换为群集登录密码来进行编辑。 将MYCLUSTERNAME替换为您的HBase群集的名称。 然后输入命令。export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAME使用以下命令列出现有的 HBase 表:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.cn/hbaserest/使用以下命令创建包含两列系列的新 HBase 表:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.cn/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -v架构以 JSON 格式提供。
使用以下命令插入某些数据:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.cn/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vBase64 对开关中指定的
-d值进行编码。 在示例中:MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==:个人:姓名
Sm9obiBEb2xl: John Dole
false-row-key 允许以批量的方式插入多个值。
使用以下命令获取一行数据:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.cn/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
注释
尚不支持扫描群集终结点。
有关 HBase Rest 的详细信息,请参阅 Apache HBase 参考指南。
注释
HDInsight 中的 HBase 不支持 Thrift。
使用 Curl 或任何其他 REST 与 WebHCat 通信时,必须通过为 HDInsight 群集管理员提供用户名和密码对请求进行身份验证。 还必须使用群集名称作为用于将请求发送到服务器的统一资源标识符(URI)的一部分:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.cn/templeton/v1/status
你应该收到类似以下的响应:
{"status":"ok","version":"v1"}
检查群集状态
HDInsight 中的 HBase 附带用于监视群集的 Web UI。 使用 Web UI 可以请求有关区域的统计信息或信息。
访问 HBase Master UI
登录至 Ambari Web UI
https://CLUSTERNAME.azurehdinsight.cn,此处CLUSTERNAME是您的 HBase 群集的名称。从左侧菜单中选择 HBase 。
选择页面顶部的 “快速链接 ”,指向活动的 Zookeeper 节点链接,然后选择 “HBase 主 UI”。 UI 在另一个浏览器选项卡中打开:
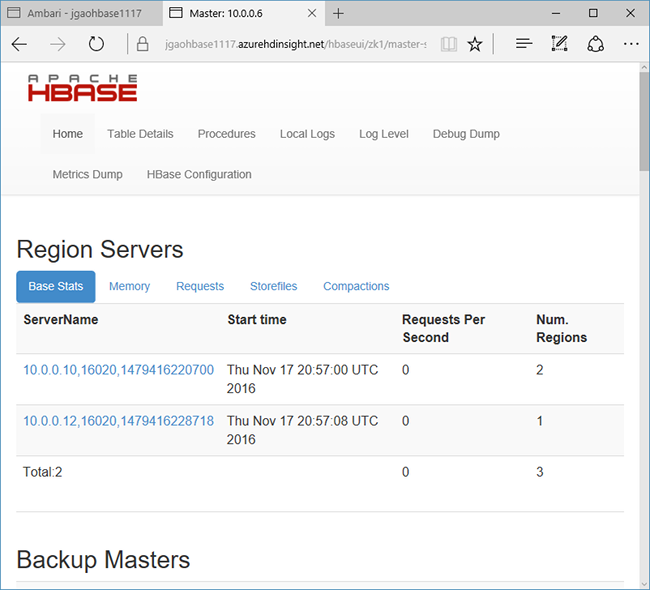
HBase Master UI 包含以下部分:
- 区域服务器
- 备份主控设备
- tables
- tasks
- 软件属性
群集重建
删除 HBase 群集后,可以使用同一默认 Blob 容器创建另一个 HBase 群集。 新群集选取在原始群集中创建的 HBase 表。 但是,为了避免不一致,建议在删除群集之前禁用 HBase 表。
可以使用 HBase 命令 disable 'Contacts'。
清理资源
如果不打算继续使用此应用程序,请删除使用以下步骤创建的 HBase 群集:
- 登录到 Azure 门户。
- 在顶部的 “搜索 ”框中,键入 HDInsight。
- 在“服务”下选择“HDInsight 群集”。
- 在显示的 HDInsight 群集列表中,单击为本教程创建的群集旁边的 ... 。
- 单击 “删除” 。 单击“是”。
后续步骤
本教程介绍了如何创建 Apache HBase 群集。 以及如何从 HBase shell 创建表并查看这些表中的数据。 你还了解了如何在 HBase 表中使用 Hive 查询数据。 如何使用 HBase C# REST API 创建 HBase 表并从表中检索数据。 若要了解详细信息,请参阅: