Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
对于除Azure SQL Database以外的每个源,建议保留 使用当前分区作为所选值。 从所有其他源系统读取数据时,数据流会根据数据的大小自动对数据进行均匀分区。 为大约每 128 MB 的数据创建一个新分区。 随着数据大小的增加,分区数也会增加。
自定义分区将在 Spark 读取数据之后发生,并且可能对数据流性能产生负面影响。 由于数据在读取时均匀分区,除非先了解数据的形状和基数,否则不建议这样做。
注释
读取速度可以受源系统的吞吐量限制。
Azure SQL 数据库源
Azure SQL Database具有一个名为“源”分区的唯一分区选项。 启用源分区可以通过在源系统上启用并行连接来提高从Azure SQL Database的读取时间。 指定分区数以及如何对数据进行分区。 使用基数较高的分区列。 还可以输入与源表的分区方案匹配的查询。
小窍门
对于源分区,SQL Server的 I/O 是瓶颈。 添加过多分区可能会让源数据库饱和。 使用此选项时,通常最理想的是有四个或五个分区。
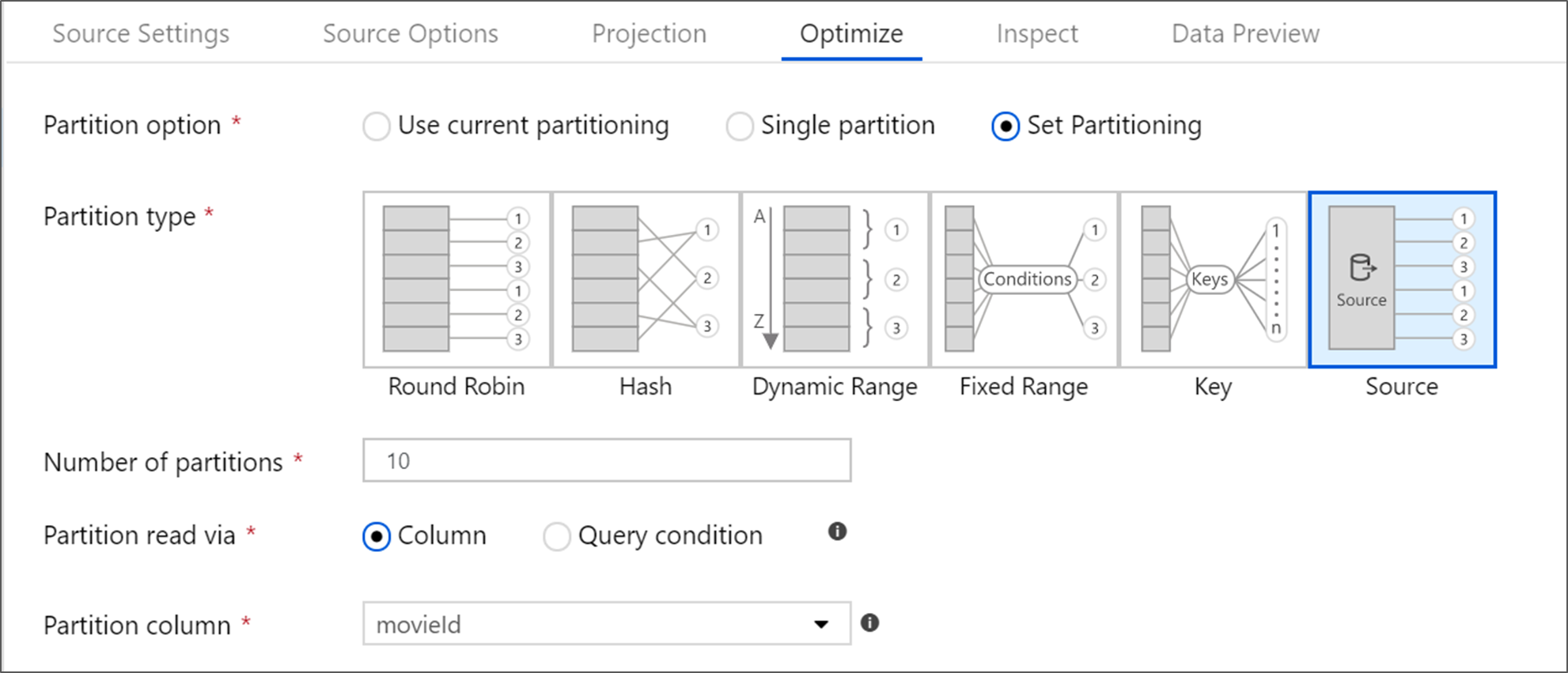
隔离级别
Azure SQL源系统上读取的隔离级别会影响性能。 选择“未提交读取”可以提供最快的性能,并避免对数据库加锁。 若要详细了解 SQL 隔离级别,请参阅 了解隔离级别。
使用查询读取
可以使用表或 SQL 查询从Azure SQL Database读取数据。 如果要执行 SQL 查询,必须先完成查询,然后才能开始转换。 SQL 查询可用于向下推送操作,这些操作的执行速度可能更快,并减少从 SELECT、WHERE 和 JOIN 语句等SQL Server读取的数据量。 在向下推送操作时,你将失去在数据进入数据流之前跟踪转换的世系和性能的能力。
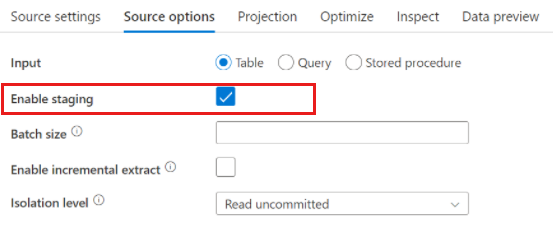
Azure Synapse Analytics数据源
使用 Azure Synapse Analytics时,源选项中存在名为 Enable 暂存的设置。 这使服务能够使用 Staging 从 Synapse 读取,通过使用最具性能的大容量加载功能(如 CETAS 和 COPY 命令),极大地提高了读取性能。 启用 Staging要求在数据流活动设置中指定Azure Blob Storage或 Azure Data Lake Storage第 2 代暂存位置。
基于文件的源
Parquet 与带分隔符的文本
虽然数据流支持各种文件类型,但建议使用 Spark 原生 Parquet 格式,以获得最佳读取和写入时间。
如果在一组文件上运行相同的数据流,建议从一个文件夹中读取,使用通配符路径或从文件列表中读取。 单个数据流活动运行可以批量处理所有文件。 有关如何配置这些设置的详细信息,请参阅 Azure Blob Storage 连接器文档中的 Source transformation 部分。
如果可能,请避免使用 For-Each 活动通过一组文件运行数据流。 这会导致 for-each 的每个迭代启动其自己的 Spark 群集,这通常不是必需的,并且可能很昂贵。
内联数据集与共享数据集
ADF 和 Synapse 数据集是工厂和工作区中的共享资源。 在读取大量源文件夹和文件,其中包含分隔文本和 JSON 源时,通过在“投影”中的“架构选项”对话框中设置“用户指定的架构”选项,可以提高数据流文件发现的性能。 此选项关闭 ADF 的默认架构自动发现,并大大提高了文件发现的性能。 在设置此选项之前,请确保导入投影,以便 ADF 具有用于投影的现有架构。 此选项与模式漂移不兼容。
相关内容
请参阅与性能相关的其他Data Flow文章: