Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
数据流可在Azure Data Factory管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
在转换数据后,使用汇聚转换将数据写入目标存储。 每个数据流至少需要一个接收器转换,但你可根据需要写入任意多个接收器来完成转换流。 若要写入更多接收器,请通过新的分支和有条件拆分创建新数据流。
每个接收器转换只与一个数据集对象或链接服务相关联。 汇聚转换决定您要写入的数据的形状和位置。
内联数据集
创建接收器转换时,请选择是在数据集对象内还是在接收器转换中定义接收器信息。 大多数格式只适用于其中之一。 若要了解如何使用特定连接器,请参阅相应的连接器文档。
当某一格式同时受到内联和数据集对象的支持时,这两种方式各有其优势。 数据集对象是可重用的实体,可在其他数据流和复制等活动中使用。 使用强化的架构时,这些可重复使用的实体特别有用。 数据集不基于 Spark。 有时,可能需要在接收器转换中覆盖某些设置或架构投影。
如果使用灵活的架构、一次性接收器实例或参数化接收器,建议使用内联数据集。 如果数据接收端参数化程度高,使用内联数据集可以不创建“伪对象”。 内联数据集基于 Spark,其属性是数据流原生的。
若要使用内联数据集,请在“接收器类型”选择器中选择所需的格式。 选择要与其连接的链接服务,而不是选择接收器数据集。
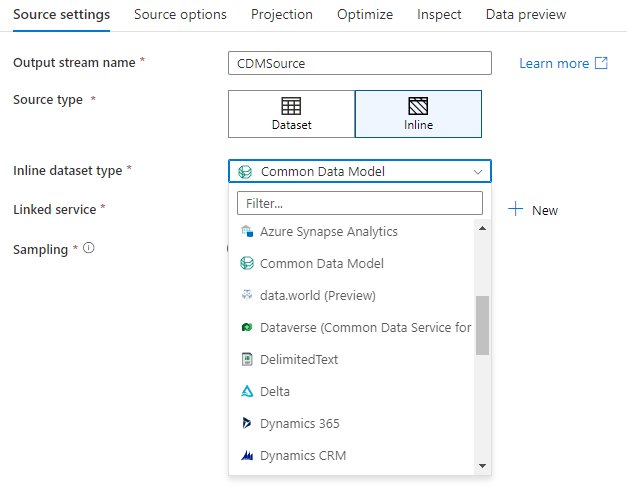
支持的接收器类型
映射数据流遵循提取、加载和转换(ELT)方法,并与Azure中的所有暂存数据集一起工作。 目前,以下数据集可用于汇流转换。
小窍门
接收器的格式可能与源不同。 这是如何从一种格式转换为另一种格式的一个步骤。 例如,从 CSV 到 Parquet 接收器。 可能需要在源和接收器之间进行数据流中的一些转换,这样才能正常工作。 (例如,Parquet 的标头要求比 CSV 更具体。
| 连接器 | 格式 | 数据集/内联 |
|---|---|---|
| Azure Blob Storage |
Avro 带分隔符的文本 Delta JSON ORC Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen2 |
Avro Common Data Model 带分隔符的文本 Delta JSON ORC Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Azure SQL Managed Instance | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| SFTP |
Avro 带分隔符的文本 JSON ORC Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
这些连接器的特定设置位于“设置”选项卡上。有关这些设置的信息和数据流脚本示例位于连接器文档中。
服务可以访问超过 90 个原生连接器。 若要将数据从数据流写入其他源,请使用复制活动从受支持的接收器加载该数据。
接收器设置
添加接收器后,请通过“接收器”选项卡进行配置。可在此处选择或创建接收器所写入的数据集。 可在调试设置中配置数据集参数的开发值。 (必须打开调试模式。)
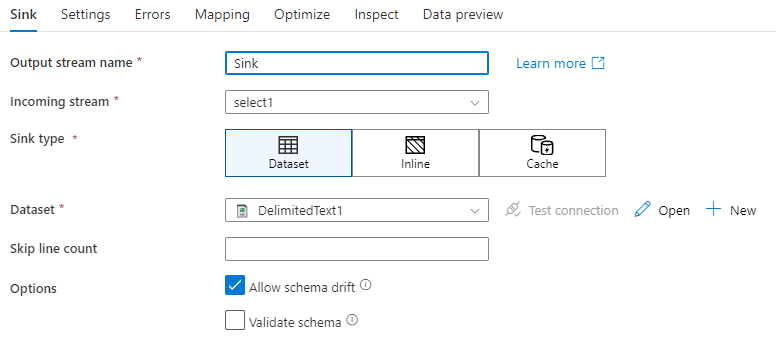
架构偏差:架构偏差是指在无需显式定义列更改的情况下,服务在数据流中以原生方式处理灵活架构的能力。 启用“允许架构偏差”在接收器数据架构中定义的内容之上写入额外的列。
验证架构:如果选择了验证架构,则如果接收器投影中的任一列在接收器存储中未找到,或者数据类型不匹配,数据流将失败。 使用此设置来确保接收器架构符合您定义的投影规范。 在数据库接收端场景中,指示列名称或类型已更改是很有用的。
缓存汇集器
缓存接收器是指数据流将数据写入 Spark 缓存,而不是数据存储。 在映射数据流中,可以使用缓存查找在同一流中多次引用此数据。 想要引用数据作为表达式的一部分,但又不想显式地将列联接到其中时,这很有用。 在缓存接受器可以发挥作用的常见示例包括:在数据存储中查找最大值,以及将错误代码匹配到错误消息数据库中。
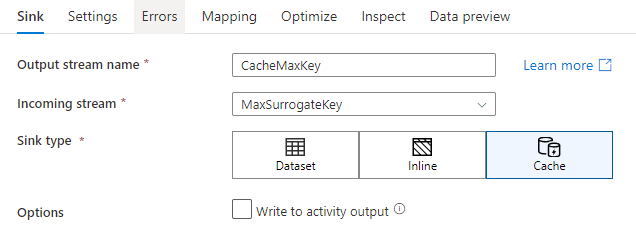
若要写入缓存接收器,请添加接收器转换,然后选择“缓存”作为接收器类型。 与其他汇聚器类型不同,由于不写入外部存储,因此无需选择数据集或链接服务。
在接收器设置中,可以选择性地指定缓存接收器的关键列。 在缓存查找中使用 lookup() 函数时,这些用作匹配条件。 如果指定键列,则不能在缓存查找中使用 outputs() 函数。 若要了解有关缓存查找语法的详细信息,请参阅缓存查找。
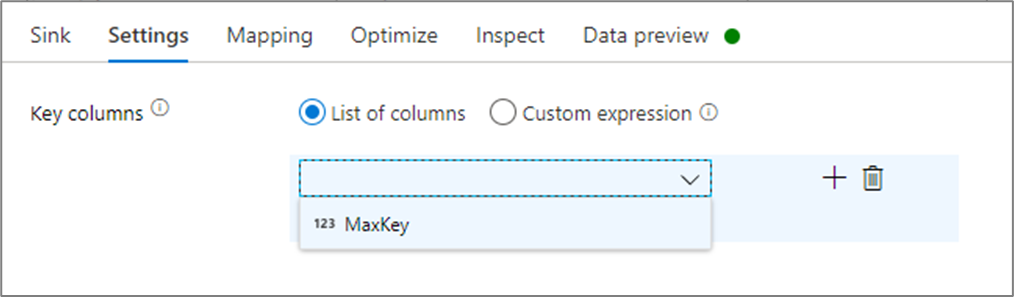
例如,如果在名为 column1 的缓存接收器中指定一个键列 cacheExample,则调用 cacheExample#lookup() 时将有一个参数指定匹配缓存接收器中的哪一行。 函数输出一个复杂列,其中每个映射的列都有子列。
注意事项
缓存接收器必须位于数据流中,且该数据流必须完全独立于通过缓存查找对其进行引用的任意转换。 缓存接收器还必须是第一个写入的接收器。
写入活动输出
缓存接收器可以选择将其数据写入Data Flow活动的输出,然后该输出可用作管道中另一个活动的输入。 这样便可以快速轻松地将数据从数据流活动中传出,而无需将数据保存在数据存储中。
请注意,从Data Flow直接注入到您的管道的输出限制为2MB。 因此,Data Flow 会在保持 2MB 限制的情况下,尽可能多地将行添加到输出。这就是为什么有时你可能看不到活动输出中的所有行。 在Data Flow活动级别设置“仅第一行”还有助于根据需要限制Data Flow的数据输出。
更新方法
对于数据库接收器类型,“设置”选项卡将包含“更新方法”属性。 默认选项为“插入”,但也包括用于“更新”、“更新插入”和“删除”的复选框选项。 若要利用这些附加选项,需要在接收器之前添加更改行转换。 “更改行”将允许你为每个数据库操作定义条件。 如果您的源是启用 CDC 的本机源,则无需“更改行”即可设置更新方法,因为 ADF 已掌握插入、更新、更新插入和删除的行标记。
字段映射
与选择转换类似,可以在接收器的“映射”选项卡上决定要写入哪些传入列。 默认情况下,将映射所有输入列,包括偏移列。 此行为称为自动映射。
关闭自动映射时,可以添加基于固定列的映射或基于规则的映射。 使用基于规则的映射,可以编写具有模式匹配的表达式。 固定的映射会映射逻辑和物理列名称。 有关基于规则的映射的详细信息,请参阅映射数据流中的列模式。
自定义接收器排序
默认情况下,数据以不确定的顺序写入多个接收器。 转换逻辑完成时,执行引擎并行写入数据,并且接收器排序可能会在每次运行时发生变化。 若要指定确切的接收器排序,请在数据流的“常规”选项卡上启用“自定义接收器排序” 。 启用后,数据节点按递增顺序依次写入。
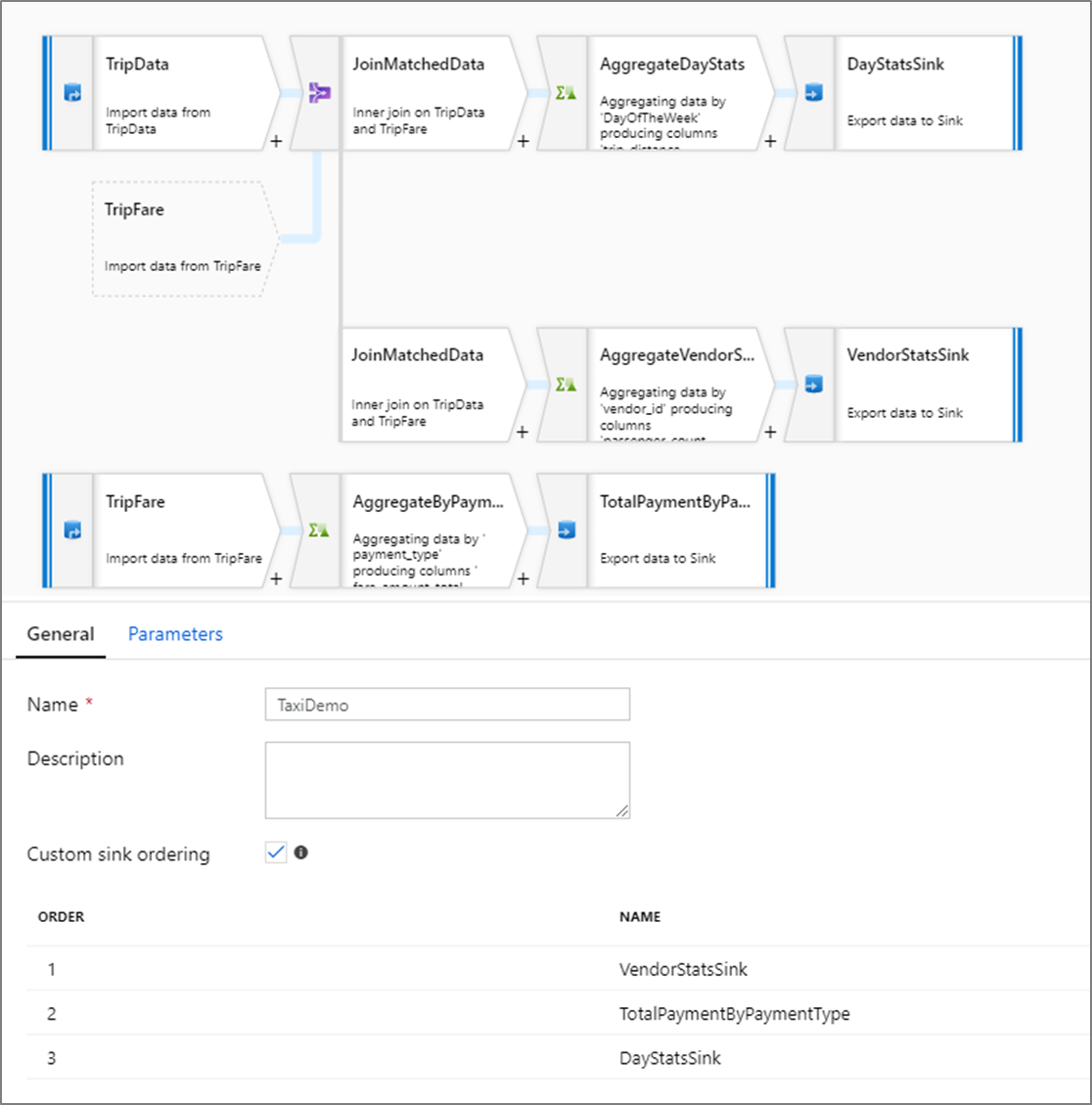
注意事项
使用缓存查询时,请确保接收器排序已将缓存接收器设置为 1,即排序中最低的一个(或第一个)。
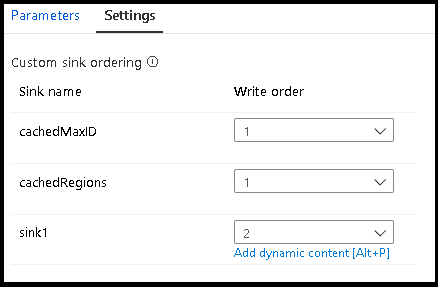
汇聚组
可以对一系列接收器使用同一顺序编号来将接收器组合在一起。 服务会将这些接收端视为可以并行运行的组。 管道数据流活动中将显示并行执行的选项。
错误
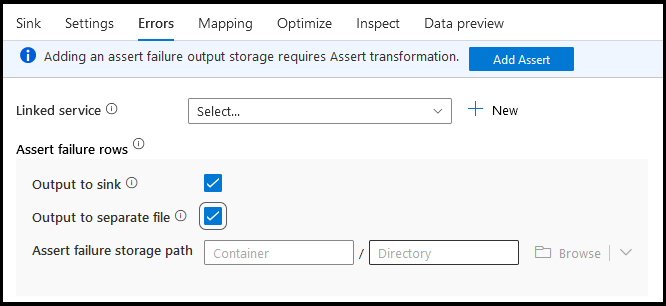
在“接收器错误”选项卡上,可以配置错误行处理来捕获和重定向数据库驱动程序错误的输出和失败断言的输出。
写入数据库时,某些数据行可能会由于目标设置的约束而失败。 默认情况下,遇到第一个错误时,数据流运行将失败。 在某些连接器中,可以选择“出错时继续运行”,确保即使单个行存在错误,也可以完成数据流。 目前,此功能仅在Azure SQL Database和Azure Synapse中可用。 有关详细信息,请参阅 Azure SQL DB 中的 error 行处理。
对于断言失败行,你可以在数据流的上游使用“断言转换”,然后将失败的断言重定向到“接收器错误”选项卡中此处的输出文件。你还可以在此处选择忽略断言失败的行,而不将这些行输出到接收器目标数据存储。
接收器中的数据预览
在调试群集中获取数据预览时,不会将任何数据写入接收器。 将返回数据的快照,但不会将任何内容写入您的目标位置。 要测试将数据写入汇,请从管道设计界面运行管道调试。
数据流脚本
示例
下面是汇聚转换及其数据流脚本的示例:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
相关内容
创建数据流后,请将数据流活动添加到管道。