Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
输出配置
下表包含将事件中心数据流配置为输出所需的参数。
| 属性名称 | 说明 |
|---|---|
| 输出别名 | 查询中使用的友好名称,用于将查询输出定向到此事件中心。 |
| 事件中心命名空间 | 一组消息传送实体的容器。 创建新的事件中心时,还创建了事件中心命名空间。 |
| 事件中心名称 | 事件中心输出的名称。 |
| 事件中心策略名称 | 可在事件中心的 “配置 ”选项卡上创建的共享访问策略。每个共享访问策略都有一个名称、设置的权限和访问密钥。 |
| 事件中心策略密钥 | 用于对事件中心命名空间的访问权限进行身份验证的共享访问密钥。 |
| 分区键列 | 可选。 包含事件中心输出分区键的列。 |
| 事件序列化格式 | 输出数据的序列化格式。 支持 JSON、CSV 和 Avro。 |
| 编码 | 对于 CSV 和 JSON,UTF-8 是目前唯一支持的编码格式。 |
| 分隔符 | 仅适用于 CSV 序列化。 流分析支持多种常见的分隔符,用于以 CSV 格式序列化数据。 支持的值为逗号、分号、空格、制表符和垂直条。 |
| Format | 仅适用于 JSON 序列化。 行分隔 指定输出的格式是让每个 JSON 对象用新行分隔。 如果选择 “行分隔”,则 JSON 一次读取一个对象。 整个内容本身不是有效的 JSON。 数组 指定输出的格式为 JSON 对象的数组。 |
| 属性列 | 可选。 需要作为传出消息的用户属性而不是有效负载附加的逗号分隔列。 有关此功能的详细信息,请参阅 输出的自定义元数据属性部分。 |
Partitioning
分区因分区对齐方式而异。 当事件中心输出的分区键与上游查询步骤相等时,编写器数与事件中心输出中的分区数相同。 每个编写器都使用 EventHubSender 类 将事件发送到特定分区。 当事件中心输出的分区键与上游(上一)查询步骤不一致时,编写器数与上一步中的分区数相同。 每个编写器都使用 EventHubClient 中的 SendBatchAsync 类将事件发送到所有输出分区。
输出批大小
最大消息大小为每条消息 256 KB 或 1 MB。 有关详细信息,请参阅 事件中心限制。 当输入/输出分区不一致时,每个事件将单独打包并在 EventData 一批中发送至最大消息大小。 如果使用 自定义元数据属性 ,也会发生这种情况。 当输入/输出分区对齐时,多个事件会打包成单个 EventData 实例,最大消息大小并发送。
输出的自定义元数据属性
可以将查询列作为用户属性附加到传出消息。 这些列不会进入有效负载。 这些属性以输出消息上的字典的形式存在。 键 是列名, 值为 属性字典中的列值。 除记录和数组外,支持所有流分析数据类型。
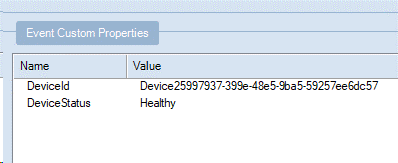
在以下示例中,字段 DeviceId 并 DeviceStatus 添加到元数据中。
使用以下查询:
select *, DeviceId, DeviceStatus from iotHubInput在输出中配置为
DeviceId,DeviceStatus属性列。
下图显示了使用 Service Bus Explorer 在事件中心检查的预期输出消息属性。
恰好一次传递
默认情况下,事件中心输出支持传递一次。 无论输入如何,流分析都保证在事件中心输出中不会丢失数据或无重复项,从上次输出时间开始重启用户启动,从而防止生成重复项。 这大大简化了流式处理管道,无需监视、实现和排查重复数据删除逻辑问题。
后续步骤
使用托管标识从Azure Stream Analytics作业(预览版) - Quickstart:使用 Azure 门户创建流分析作业