HDInsight 4.0 的重大版本更改和优势
与 HDInsight 3.6 相比,HDInsight 4.0 具有几项更为显著的优势。 下面概述了 Azure HDInsight 4.0 中的新增功能。
| # | OSS 组件 | HDInsight 4.0 版 | HDInsight 3.6 版 |
|---|---|---|---|
| 1 | Apache Hadoop | 3.1.1 | 2.7.3 |
| 2 | Apache HBase | 2.1.6 | 1.1.2 |
| 3 | Apache Hive | 3.1.0 | 1.2.1、2.1 (LLAP) |
| 4 | Apache Kafka | 2.1.1、2.4 (GA) | 1.1 |
| 5 | Apache Phoenix | 5 | 4.7.0 |
| 6 | Apache Spark | 2.4.4、3.0.0(预览版) | 2.2 |
| 7 | Apache TEZ | 0.9.1 | 0.7.0 |
| 8 | Apache ZooKeeper | 3.4.6 | 3.4.6 |
| 9 | Apache Kafka | 2.1.1、2.4.1(预览版) | 1.1 |
| 10 | Apache Ranger | 1.1.0 | 0.7.0 |
工作负载和功能
Hive
- 高级功能
- LLAP 工作负载管理
- LLAP 支持 JDBC、Druid 和 Kafka 连接器
- 更好的 SQL 功能 – 约束和默认值
- 代理项键
- 信息架构。
- 性能优势
- 结果缓存 - 缓存查询结果允许重用先前计算的查询结果
- 动态具体化视图 - 摘要预先计算
- ACID V2 在存储格式和执行引擎方面的性能提升
- 安全性
- 对 Apache Hive 事务启用 GDPR 合规性
- Ranger 中的 Hive UDF 执行授权
HBase
- 高级功能
- Procedure 2。 Procedure V2 (procv2) 是用于执行多步 HBase 管理操作的已更新框架。
- 完全堆外读/写路径。
- 内存中压缩
- HBase 群集支持高级 ADLS Gen2
- 性能优势
- 加速写入使用 Azure 高级 SSD 托管磁盘,可以改善 Apache HBase 预写日志 (WAL) 的性能。
- 安全性
- 强化 Local 和 Global 这两个辅助索引
Kafka
- 高级功能
- Azure 容错域上的 Kafka 分区分发
- Zstd 压缩支持
- Kafka 使用者增量再平衡
- 支持 MirrorMaker 2.0
- 性能优势
- 改进了 Kafka 流中的开窗聚合性能
- 通过减少消息转换操作的内存占用量提高了代理复原能力
- 快速先导故障转移相关的复制协议改进
- 安全性
- 根据特定主题/主题前缀对主题创建进行访问控制
- 通过主机名验证防止 SSL 配置遭受中间人攻击
- 通过更快的传输层安全性 (TLS) 和 CRC32C 实现改进了加密支持
Spark
- 高级功能
- 对 ORC 的结构化流式处理支持
- 能够与新的元存储目录功能集成
- 对 Hive 流式处理库的结构化流式处理支持
- 透明写入 Hive 仓库
- Spark Cruise - Spark 的自动计算重用系统。
- 性能优势
- 结果缓存 - 缓存查询结果允许重用先前计算的查询结果
- 动态具体化视图 - 摘要预先计算
- 安全性
- 为 Spark 事务启用 GDPR 合规性
Hive 分区发现和修复
Hive 自动发现并同步 Hive 元存储中的分区的元数据。
discover.partitions 表属性启用和禁用文件系统与分区的同步。 在外部已分区表中,此属性默认已启用 (true)。
当 Hive 元存储服务 (HMS) 在远程服务模式下启动时,将每隔 300 秒(此间隔可通过 metastore.partition.management.task.frequency config 来配置)定期计划一次后台线程 (PartitionManagementTask),该线程查找 discover.partitions 表属性设置为 true 的表,并在同步模式下执行 msck 修复。
如果表是事务表,则在执行 msck repair 之前获取该表的排他锁。 如果使用此表属性,就不再需要手动运行 MSCK REPAIR TABLE table_name SYNC PARTITIONS。
假设你的某个外部表是使用不支持分区发现的 Hive 版本创建的,你想要为该表启用分区发现。
ALTER TABLE exttbl SET TBLPROPERTIES ('discover.partitions' = 'true');
将分区同步设置为每隔 10 分钟(以秒表示)发生一次:在“Ambari”>“Hive”>“配置”中,将 set metastore.partition.management.task.frequency 设置为 3600 或更大。
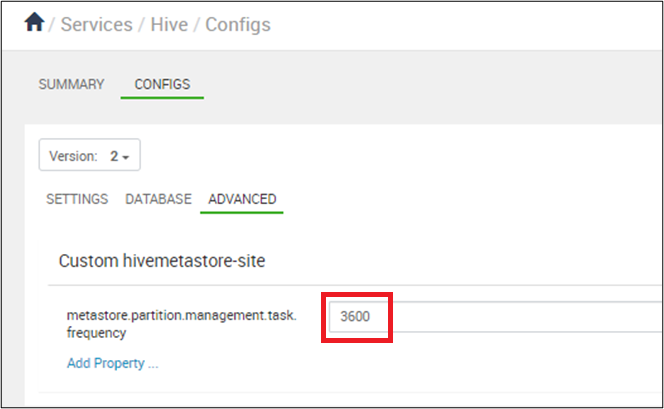
警告
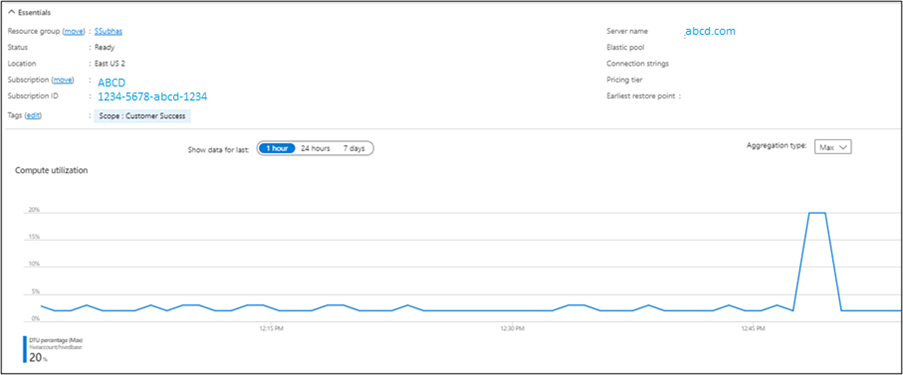
在 management.task 每隔 10 分钟运行的情况下,SQL 服务器 DTU 会承受压力。
可以从 Azure 门户验证输出。
Hive 会删除保留期过后创建的任何分区中的元数据和相应数据。 使用数字并后接一个或多个字符来表示保留时间。 Hive 会删除保留期过后创建的任何分区中的元数据和相应数据。 使用数字并后接一个或多个字符来表示保留时间。
ms (milliseconds)
s (seconds)
m (minutes)
d (days)
将分区保留期配置为一周。
ALTER TABLE employees SET TBLPROPERTIES ('partition.retention.period'='7d');
一周后将自动删除 Hive 中员工的分区元数据和实际数据。
Hive 3
在 Hive 3 中可以使用性能优化
OLAP 矢量化动态半联接化简 Parquet 支持使用 LLAP 自动查询缓存进行矢量化。
新的 SQL 功能
具体化视图代理键约束元存储 CachedStore。
OLAP 矢量化
矢量化使 Hive 能够同时处理一批行,而无需一次处理一行。 每个批通常是一个基元类型数组。 操作针对整个列矢量执行,从而改善了指令管道和缓存的使用。 PTF、汇总和分组集的矢量化执行。
动态 Semijoin 化简
显著提高了选择性联接的性能。 它从联接的一端构建 bloom 筛选器,并在另一端筛选行。 跳过不符合联接条件的行的扫描和进一步计算。
Parquet 支持使用 LLAP 进行矢量化
矢量化查询执行是可以大幅降低典型查询操作的 CPU 使用率的功能,例如以下操作
- 扫描
- 筛选器
- aggregate
- 联接
还为 ORC 格式实现了矢量化。 从 Spark 2.0 开始,Spark 还使用 Whole Stage Codegen 和这种矢量化(用于 Parquet)。 在 LLAP 下添加了 Parquet 矢量化和格式的时间戳列。
警告
从时间戳转换为区域时间时,Parquet 写入速度缓慢。 有关详细信息,请参阅此文。
自动查询缓存
- 使用
hive.query.results.cache.enabled=true时,在 Hive 3 中运行的每个查询会将其结果存储在缓存中。 - 如果输入表发生更改,Hive 将从缓存中逐出无效数据。 例如,如果你执行聚合,而基表发生更改,则最常运行的查询将保留在缓存中,但已过时的查询将被逐出。
- 查询结果缓存仅适用于托管表,因为 Hive 无法跟踪对外部表的更改。
- 如果联接外部表和托管表,Hive 将回退为执行完整查询。 查询结果缓存适用于 ACID 表。 如果你更新 ACID 表,Hive 将自动重新运行查询。
- 可以从命令行启用和禁用查询结果缓存。 你可能会出于调试查询的目的这样做。
- 通过将以下参数设置为 false 来禁用查询结果缓存:
hive.query.results.cache.enabled=false - Hive 将查询结果缓存存储在
/tmp/hive/__resultcache__/中。 默认情况下,Hive 为查询结果缓存分配 2 GB 空间。 可以通过配置以下参数(以字节为单位)来更改此设置:hive.query.results.cache.max.size - 对查询处理的更改:在查询编译期间,检查结果缓存以确定其中是否已包含查询结果。 如果存在缓存命中,则查询计划将设置为
FetchTask以从缓存位置读取。
在查询执行期间:
Parquet DataWriteableWriter 依赖于使用 NanoTimeUtils 将时间戳对象转换为二进制值。 此查询对时间戳对象调用 toString(),然后分析字符串。
- 如果结果缓存可用于此查询
- 查询是从缓存的结果目录中
FetchTask读取的。 - 不需要群集任务。
- 查询是从缓存的结果目录中
- 如果无法使用结果缓存,则如常运行群集任务
- 检查已计算的查询结果是否符合添加到结果缓存的条件。
- 如果可以缓存结果,则为查询生成的临时结果将保存到结果缓存中。 可能需要执行此处的步骤,以确保查询清理不会删除查询结果目录。
SQL 功能
具体化视图
Apache Hive 3.0.0 中引入的初始实现侧重于在项目中基于这些具体化引入具体化视图和自动查询重写。 具体化视图可以存储在 Hive 本地或存储在其他自定义存储处理程序 (ORC) 中,它们可以无缝利用令人兴奋的 Hive 新功能,例如 LLAP 加速。
有关详细信息,请参阅 Hive - 具体化视图 - Azure 技术社区
代理项键
在表中输入数据时,使用内置的 SURROGATE_KEY 用户定义函数 (UDF) 自动为行生成数字 ID。 生成的代理键可以替换多个宽型组合键。
Hive 仅支持 ACID 表上的代理键。 要使用代理键联接的表不能包含需要强制转换的列类型。 这些数据类型必须是基元,例如 INT 或 STRING。
使用生成的键的联接比使用字符串的联接速度更快。 使用生成的键不会强制数据按行号进入单个节点。 可以生成键作为自然键的抽象。 代理键相比 UUID 更具优势,后者速度更慢且是概率性的。
SURROGATE_KEY UDF 为插入到表中的每一行生成唯一 ID。
它根据分布式系统中的执行环境生成键,这就涉及到许多因素,例如
- 内部数据结构
- 表的状态
- 最后一个事务 ID。
生成代理键不需要在计算任务之间进行任何协调。 UDF 不采用参数,或者两个参数为
- 写入 ID 位
- 任务 ID 位
约束
SQL 约束可以强制实施数据完整性并提高性能。 优化器使用约束信息做出明智的决策。 约束能使数据可预测且易于查找。
| 约束 | 说明 |
|---|---|
| 勾选标记 | 限制可在列中放置的值的范围。 |
| PRIMARY KEY | 使用唯一标识符来标识表中的每一行。 |
| FOREIGN KEY | 使用唯一标识符来标识另一个表中的行。 |
| UNIQUE KEY | 检查列中存储的值是否不同。 |
| NOT NULL | 确保无法将某列设置为 NULL。 |
| ENABLE | 确保所有传入数据符合约束。 |
| DISABLE | 不确保所有传入数据符合约束。 |
| VALIDATEC | 检查表中的所有现有数据是否符合约束。 |
| NOVALIDATE | 不检查表中的所有现有数据是否符合约束 |
| ENFORCED | 映射到 ENABLE NOVALIDATE。 |
| NOT ENFORCED | 映射到 DISABLE NOVALIDATE。 |
| RELY | 指定遵守某个约束;由优化器用来应用进一步的优化。 |
| NORELY | 指定不遵守某个约束。 |
有关详细信息,请参阅 https://cwiki.apache.org/confluence/display/Hive/Supported+Features%3A++Apache+Hive+3.1
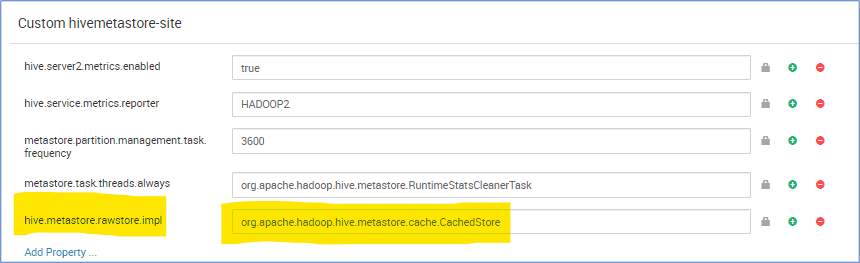
元存储 CachedStore
Hive 元存储操作需要很长时间,因此会减慢 Hive 编译速度。 在某些极端情况下,它需要的时间比实际查询运行时间要长。 尤其是,我们发现云数据库的延迟很高,占总查询运行时间 90% 的时间都在等待完成元存储 SQL 数据库操作。 根据观察到的这种状况,如果具有可以缓存数据库查询结果的内存结构,则可以增强元存储操作性能。
hive.metastore.rawstore.impl=org.apache.hadoop.hive.metastore.cache.CachedStore
故障排除指南
适用于 Hive 工作负载的 HDInsight 3.6 到 4.0 故障排除指南提供了将 Hive 工作负载从 HDInsight 3.6 迁移到 HDInsight 4.0 时所遇到的常见问题的解答。
参考
Hive 3.1.0
HBase 2.1.6
https://apache.googlesource.com/hbase/+/ba26a3e1fd5bda8a84f99111d9471f62bb29ed1d/RELEASENOTES.md
Hadoop 3.1.1