评估自动化机器学习试验结果
本文介绍如何评估和比较自动机器学习(自动化 ML)试验训练的模型。 在自动化 ML 试验过程中,创建了许多作业,每次作业都会创建一个模型。 对于每个模型,自动化 ML 生成评估指标和图表,帮助你衡量模型的性能。 可以进一步生成负责任 AI 仪表板,默认对建议的最佳模型执行整体评估和调试。 这包括模型解释、公平性和性能资源管理器、数据资源管理器、模型错误分析等见解。 详细了解如何生成负责任 AI 仪表板。
例如,自动化 ML 根据试验类型生成以下图表。
| 分类 | 回归/预测 |
|---|---|
| 混淆矩阵 | 残差直方图 |
| 接收方操作特征 (ROC) 曲线 | 预测值与实际值 |
| 精度-召回率 (PR) 曲线 | 预测边际 |
| 提升曲线 | |
| 累积增益曲线 | |
| 校准曲线 |
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 该预览版在提供时没有附带服务级别协议,建议不要将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
先决条件
- Azure 订阅。 (如果没有 Azure 订阅,请在开始前创建试用版订阅)
- 使用以下之一创建 Azure 机器学习试验:
查看作业结果
自动 ML 试验完成后,可以通过以下方式找到作业历史记录:
- 包含 Azure 机器学习工作室的浏览器
- 使用 JobDetails Jupyter 小组件的 Jupyter 笔记本
以下步骤和视频演示了如何在工作室中查看运行历史记录和模型评估指标及图表:
- 登录到工作室并导航到你的工作区。
- 在左侧菜单中,选择“作业”。
- 从试验列表中选择你的试验。
- 在页面底部的表中,选择自动化 ML 作业。
- 在“模型”选项卡中,选择要评估的模型的“算法名称” 。
- 在“指标”选项卡中,使用左侧的复选框查看指标和图表。
分类指标
自动化 ML 为试验生成的每个分类模型计算性能指标。 这些指标基于 scikit learn 实现。
许多分类指标定义为对两个类进行二元分类,并要求对多个类进行平均以产生一个多类分类得分。 Scikit-learn 提供了几种平均方法,其中三种是自动化 ML 公开:宏、Micro 和加权 。
- 宏 - 计算每个类的指标并取未加权平均值
- Micro - 通过统计真正、假负和假正总值(独立于类)来全局计算指标。
- 加权 - 计算每个类的指标,并根据每个类的样本数取加权平均值。
虽然每种平均值方法都有其优点,但在选择合适的方法时,一个常见的考虑因素是类不平衡。 如果类具有不同的样本数,则使用宏平均值(向少数类赋予与多数类相等的权重)可能会提供更多信息。 进一步了解自动化 ML 中的二进制与多类指标。
下表汇总了模型性能指标,这些指标是自动化 ML 针对每个为试验生成的分类模型计算的。 有关更多详细信息,请参阅每个指标的“计算”字段中链接的 scikit-learn 文档。
注意
有关图像分类模型的指标的更多详细信息,请参阅图像指标部分。
| 指标 | 说明 | 计算 |
|---|---|---|
| AUC | AUC 是接收方操作特性曲线下面的区域。 目标:越接近 1 越好 范围: [0, 1] 支持的指标名称包括, AUC_macro,每个类的 AUC 算术平均值。AUC_micro,通过统计真报率、漏报率和误报率总值来计算。 AUC_weighted,每个类的评分算术平均值,按每个类中的真实实例数加权。 AUC_binary,将一个特定类视为 true 类并将所有其他类合并为 false 类的 AUC 值。 |
计算 |
| accuracy | Accuracy 是与真实类标签完全匹配的预测比率。 目标:越接近 1 越好 范围: [0, 1] |
计算 |
| average_precision | 平均精度以每个阈值实现的加权精度汇总精度-召回率曲线,使用前一阈值中的召回率增量作为权重。 目标:越接近 1 越好 范围: [0, 1] 支持的指标名称包括, average_precision_score_macro,每个类的平均精度评分算术平均值。average_precision_score_micro,通过统计真报率、漏报率和误报率总值来计算。average_precision_score_weighted,每个类的平均精度评分算术平均值,按每个类中的真实实例数加权。 average_precision_score_binary,将一个特定类视为 true 类并将所有其他类合并为 false 类的平均精度值。 |
计算 |
| balanced_accuracy | 平衡准确度是每个类的召回率算术平均值。 目标:越接近 1 越好 范围: [0, 1] |
计算 |
| f1_score | F1 评分是精度和召回率的调和平均值。 这是一个很好的衡量假正和假负的平衡。 然而,它没有考虑到真负。 目标:越接近 1 越好 范围: [0, 1] 支持的指标名称包括, f1_score_macro:每个类的 F1 评分算术平均值。 f1_score_micro:通过统计真正、假负和假正总值来计算得出。 f1_score_weighted:按每个类的 F1 评分类频率计算的加权平均值。 f1_score_binary,将一个特定类视为 true 类并将所有其他类合并为 false 类的 f1 值。 |
计算 |
| log_loss | 这是(多项式) 逻辑回归及其扩展(例如神经网络)中使用的损失函数,在给定概率分类器的预测的情况下,定义为真实标签的负对数可能性。 目标:越接近 0 越好 范围: [0, inf) |
计算 |
| norm_macro_recall | 规范化宏召回率是对宏召回率进行规范化和平均化,因此,随机性能的评分为 0,完美性能的评分为 1。 目标:越接近 1 越好 范围: [0, 1] |
(recall_score_macro - R) / (1 - R) 其中, R 是随机预测的 recall_score_macro 期望值。R = 0.5 用于二元分类。 R = (1 / C) 表示 C 类分类问题。 |
| matthews_correlation | Matthews 关联系数是一种平衡准确性度量值,即使一个类比另一个类有更多的样本,也可以使用它。 系数 1 表示完美预测、0 表示随机预测以及 -1 表示反向预测。 目标:越接近 1 越好 范围: [-1, 1] |
计算 |
| 精准率 | 精准率是模型避免将负样本标记为正样本的能力。 目标:越接近 1 越好 范围: [0, 1] 支持的指标名称包括, precision_score_macro,每个类的精度算术平均值。 precision_score_micro,通过统计真正和假正总值来全局计算 Micro。 precision_score_weighted,每个类的精度算术平均值,按每个类中的真实实例数加权。 precision_score_binary,将一个特定类视为 true 类并将所有其他类合并为 false 类的精度值。 |
计算 |
| 召回率 | 召回率是模型检测所有正的样本。 目标:越接近 1 越好 范围: [0, 1] 支持的指标名称包括, recall_score_macro,每个类的召回率算术平均值。 recall_score_micro:通过统计真正、假负和假正总值来全局计算。recall_score_weighted:每个类的召回率算术平均值,按每个类中的真实实例数加权。 recall_score_binary,将一个特定类视为 true 类并将所有其他类合并为 false 类的召回值。 |
计算 |
| weighted_accuracy | 加权准确性是指每个样本按属于同一类别的样本总数加权的准确性。 目标:越接近 1 越好 范围: [0, 1] |
计算 |
二进制与多类分类指标
自动 ML 会自动检测数据是否为二进制数据,还允许用户通过指定 true 类来激活二元分类指标(即使数据属于多类)。 如果数据集包含两个或更多类,则会报告多类分类指标。 仅当数据为二进制时,才会报告二进制分类指标。
请注意,多类分类指标适用于多类分类。 正如你所期望的那样,这些指标在应用于二元分类数据集时不会将任何类视为 true 类。 明确用于多类的指标以 micro、macro 或 weighted 为后缀。 示例包括 average_precision_score、f1_score、precision_score、recall_score、AUC。 例如,多类平均召回率(micro、macro 或 weighted)不按 tp / (tp + fn) 计算召回率,而是对二进制分类数据集的两个类进行平均。 这相当于分别计算 true 类和 false 类的召回率,然后取二者的平均值。
此外,尽管支持自动检测二元分类,但仍建议一律手动指定 true 类,以确保为正确的类计算二元分类指标。
若要在数据集本身为多类时激活二元分类数据集的指标,用户只需指定要视为 true 类的类,即可计算这些指标。
混淆矩阵
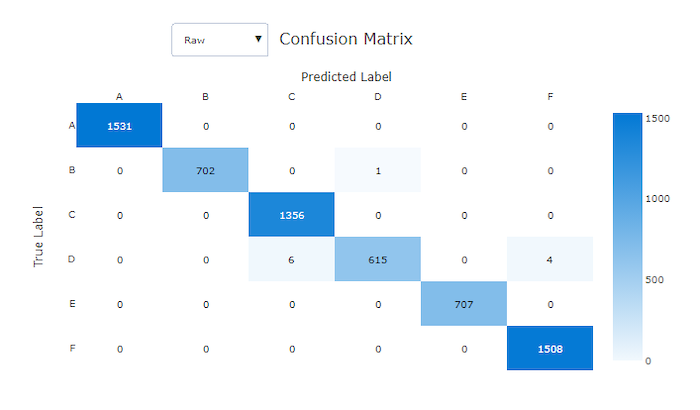
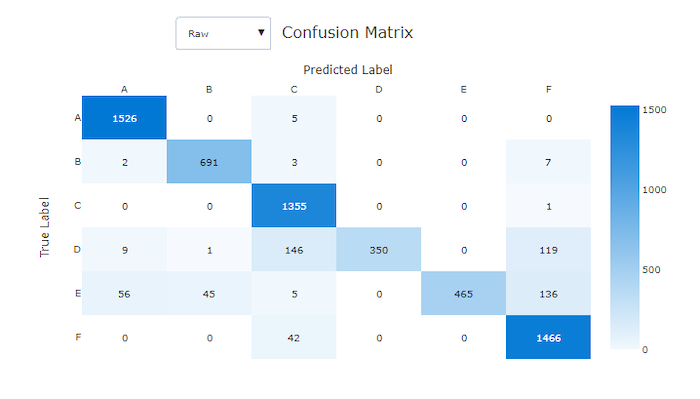
混淆矩阵提供了机器学习模型如何在分类模型的预测中产生系统性误差的直观信息。 名称中的“混淆”一词来自模型“混淆”或错误标记样本。 混淆矩阵中第i 行和第 j 列的单元格包含评估数据集中属于类 C_i 且由模型分类为类 C_j 的样本数。
在工作室中,较暗的单元格表示样本数较多。 在下拉列表中选择规范化的视图将对每个矩阵行进行规范化,以显示预测为类 C_j 的类 C_i 的百分比。 默认 Raw 视图的好处是,可以看到实际类分布的不平衡是否导致模型从少数类中错分类样本,这是不平衡数据集的常见问题。
良好模型的混淆矩阵沿对角线方向的样本最多。
良好模型的混淆矩阵
不良模型的混淆矩阵
ROC 曲线
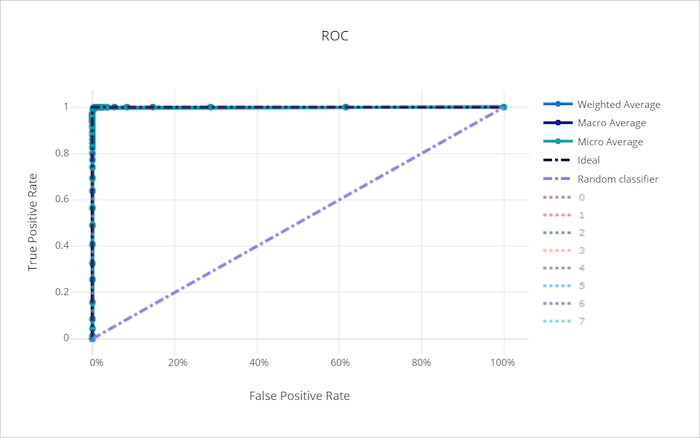
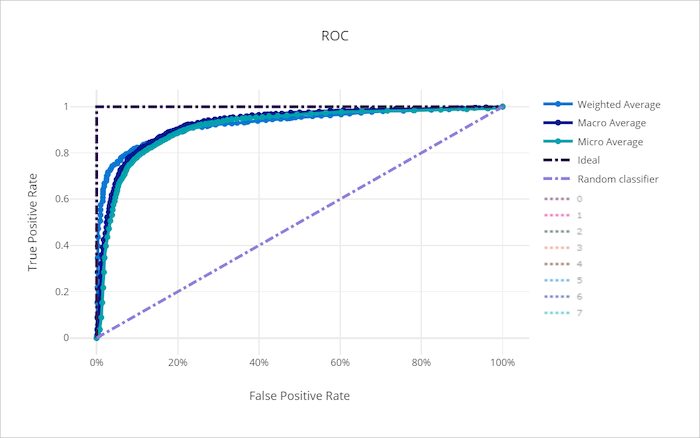
接收方操作特征 (ROC) 曲线描绘了真正率 (TPR) 和假正率 (FPR) 随决策阈值变化的关系。 在类失衡严重的情况下基于数据集训练模型时,ROC 曲线提供的信息可能较少,因为多数类可能会掩盖少数类的贡献。
曲线下区域 (AUC) 可以解释为正确分类样本的比例。 更准确地说,AUC 是分类器对随机选择的正样本的排名高于随机选择的负样本的概率。 曲线的形状直观地表明 TPR 和 FPR 之间的关系是分类阈值或决策边界的函数。
接近图表左上角的曲线接近 100% TPR 和 0% FPR,这是最佳模型。 随机模型会沿着 y = x 线从左下角到右上角生成一条 ROC 曲线。 比随机模型更糟糕的模型,其 ROC 曲线会下降到 y = x 线以下。
提示
对于分类实验,为自动化 ML 模型生成的每个折线图都可以用于评估每个类的模型或所有类的平均值。 通过单击图表右侧图例中的类标签,可以在这些不同的视图之间切换。
良好模型的 ROC 曲线
不良模型的 ROC 曲线
精度-召回率曲线
精准率-召回率曲线描绘了精准率与召回率之间随决策阈值变化的关系。 召回率是模型检测所有正样本的能力,精准率是模型避免将负样本标记为正样本的能力。 某些业务问题可能需要更高的召回率和更高的精准率,这取决于避免假负和假正的相对重要性。
提示
对于分类实验,为自动化 ML 模型生成的每个折线图都可以用于评估每个类的模型或所有类的平均值。 通过单击图表右侧图例中的类标签,可以在这些不同的视图之间切换。
良好模型的精准率-召回率曲线
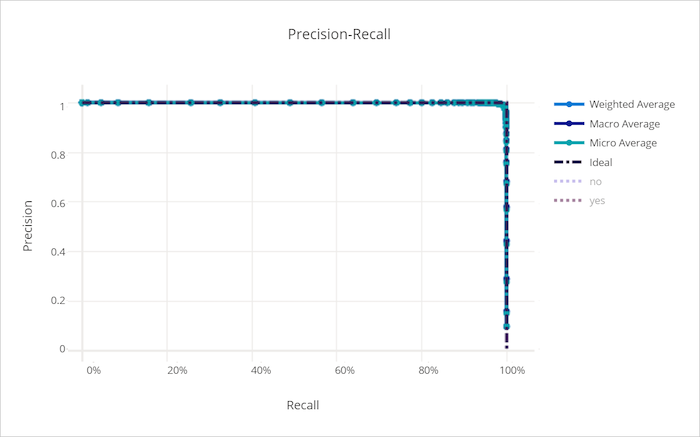
不良模型的精准率-召回率曲线
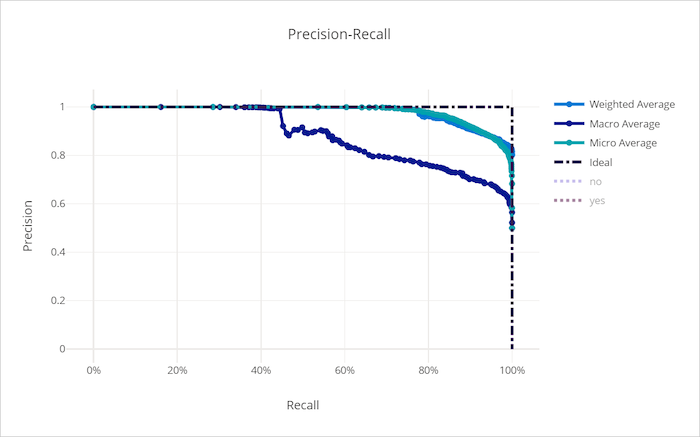
累积增益曲线
累积增益曲线绘制了正确分类的正样本百分比,作为我们按预测概率顺序考虑样本所占百分比的函数。
若要计算增益,首先从模型预测的最高概率到最低概率对所有样本进行排序。 然后取 x% 的最高置信度预测值。 将在该 x% 中检测到的正样本数除以正样本总数得到增益。 累积增益是我们在考虑最有可能属于正类别的某些数据百分比时检测到的正样本百分比。
理想的模型将所有正样本的排名高于所有负样本,给出由两个直线段组成的累积增益曲线。 第一条是斜率为 1 / x 的线,从 (0, 0) 到 (x, 1),其中 x 是属于正类的样本分数(如果类是平衡的,则为 1 / num_classes)。 第二条是从 (x, 1) 到 (1, 1) 的水平线。 在第一段中,所有正样本都已正确分类,累积增益在考虑的样本的第一个 x% 内到达 100%。
基线随机模型在 y = x 之后有一个累积增益曲线,其中在所考虑的 x% 的样本中仅检测到 x% 的总正样本。 均衡数据集的完美模型包含一条微平均曲线和一条斜率 num_classes 的宏平均线,直到累积增益达到 100%,然后水平延伸,直到数据百分比达到 100。
提示
对于分类实验,为自动化 ML 模型生成的每个折线图都可以用于评估每个类的模型或所有类的平均值。 通过单击图表右侧图例中的类标签,可以在这些不同的视图之间切换。
良好模型的累积增益曲线
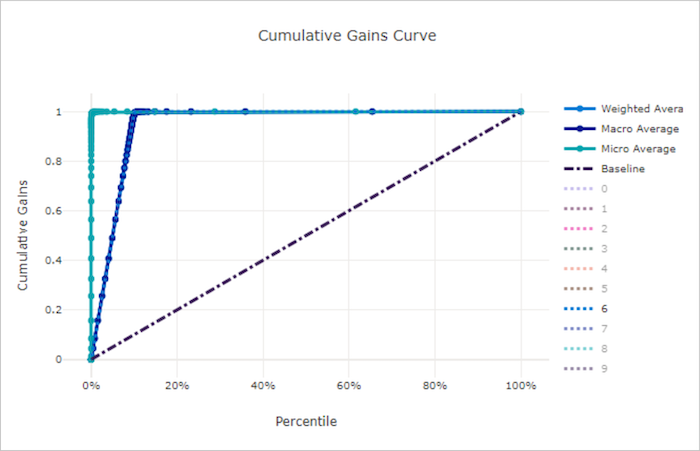
不良模型的累积增益曲线
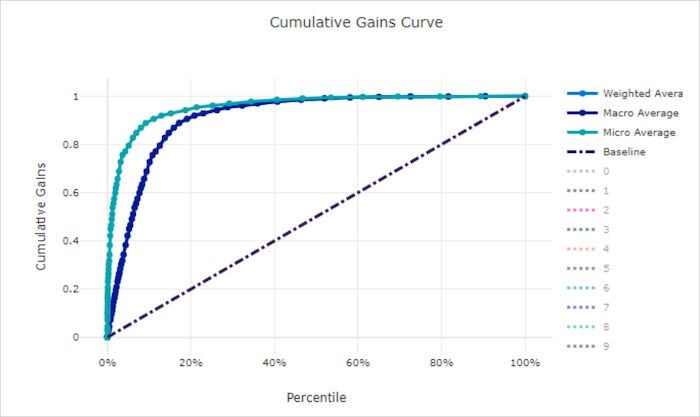
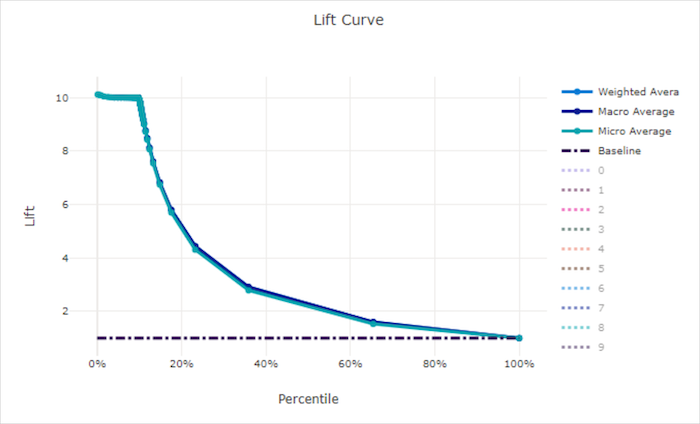
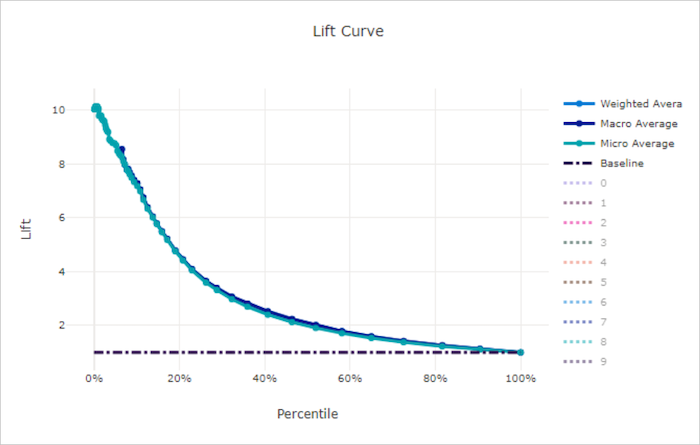
提升曲线
提升曲线显示某个模型的表现优于随机模型的次数。 提升定义为随机模型的累积增益与累积增益之比(应始终为 1)。
这种相对表现考虑到类的数量越多,分类越困难。 (与具有两个类的数据集相比,随机模型对具有 10 个类的数据集中的样本进行预测时,错误率更高)
基线提升曲线是模型性能与随机模型性能一致的 y = 1 线。 通常,良好模型的提升曲线在图表上会更高,离 x 轴更远,这表明当模型对其预测最有信心时,它的表现会比随机猜测好很多倍。
提示
对于分类实验,为自动化 ML 模型生成的每个折线图都可以用于评估每个类的模型或所有类的平均值。 通过单击图表右侧图例中的类标签,可以在这些不同的视图之间切换。
良好模型的提升曲线
不良模型的提升曲线
校准曲线
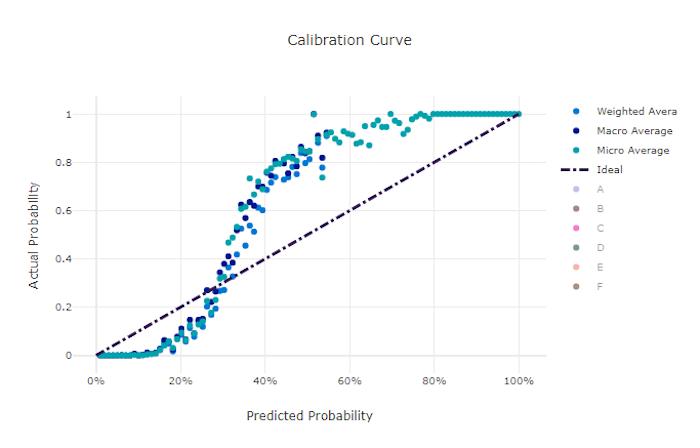
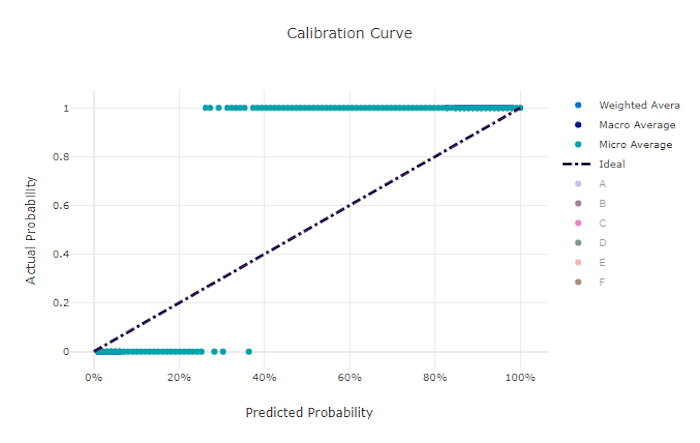
校准曲线根据每个置信度水平的正样本比例绘制模型预测的置信度。 经过良好校准的模型将正确地对 100% 的预测进行分类,其中 100% 的预测将赋予 100% 的置信度,50% 的预测降赋予 50% 的置信度,20% 的预测将赋予 20% 的置信度,依此类推。 完全校准的模型将有一条校准曲线,沿着 y = x 线,模型完美地预测样本属于每个类别的概率。
置信度过高的模型在预测接近零和一的概率时会出现高估的情况,但很少出现无法确定每个样本的类的情况,并且校准曲线会类似于倒着的“S”。 置信度过低的模型将为其预测的类别平均分配较低的概率,相关的校准曲线将类似于“S”。 校准曲线并不能说明一个模型是否能正确分类,而是说明它是否能正确向预测分配置信度。 如果模型正确地分配了低置信度和高不确定性,则不良模型仍然可具有好的校准曲线。
注意
校准曲线对样本数量非常敏感,因此小型验证集可能会产生难以解释的干扰结果。 这并不一定意味着模型没有进行正确校准。
良好模型的校准曲线
不良模型的校准曲线
回归/预测指标
自动化 ML 为生成的每个模型计算相同的性能指标,不管它是回归试验还是预测试验。 这些指标也经过规范化处理,以便在不同范围的数据上训练的模型之间进行比较。 若要了解详细信息,请参阅指标规范化。
下表总结了为回归和预测试验生成的模型性能指标。 与分类指标一样,这些指标也基于 scikit learn 实现。 相应的 scikit learn 文档在“计算”字段中链接。
| 指标 | 说明 | 计算 |
|---|---|---|
| explained_variance | 解释的方差衡量模型对目标变量变化的解释程度。 它是原始数据方差与误差方差之间的递减百分比。 当误差的平均值为 0 时,它等于确定系数(请参见下面的 r2_score)。 目标:越接近 1 越好 范围: (-inf, 1] |
计算 |
| mean_absolute_error | 平均绝对误差是目标与预测之间的差的预期绝对值。 目标:越接近 0 越好 范围:[0, inf) 类型: mean_absolute_error normalized_mean_absolute_error,mean_absolute_error 除以数据范围。 |
计算 |
| mean_absolute_percentage_error | 平均绝对百分比误差 (MAPE) 是预测值和实际值之间平均差值的度量值。 目标:越接近 0 越好 范围: [0, inf) |
|
| median_absolute_error | 平均绝对误差是目标与预测之间的所有绝对差的中间值。 此损失值可靠地反映离群值。 目标:越接近 0 越好 范围: [0, inf) 类型: median_absolute_errornormalized_median_absolute_errormedian_absolute_error 除以数据范围。 |
计算 |
| r2_score | R2(决定系数)衡量均方误差 (MSE) 相对于观察到的数据的总方差的按比例的降低程度。 目标:越接近 1 越好 范围: [-1, 1] 注意:R2 的范围通常为 (-inf, 1]。 MSE 可以大于观察到的方差,因此 R2 可以有任意大的负值,具体取决于数据和模型预测。 自动化 ML 剪辑报告的 R2 分数为 -1,因此 R2 的值为 -1 可能表示实际的 R2 分数小于 -1。 在解释负 R2 分数时,请考虑其他指标值和数据的属性。 |
计算 |
| root_mean_squared_error | 均方根误差 (RMSE) 是目标与预测之间的预期平方差的平方根。 对于无偏差估算器,RMSE 等于标准偏差。 目标:越接近 0 越好 范围: [0, inf) 类型: root_mean_squared_error normalized_root_mean_squared_error:root_mean_squared_error 除以数据范围。 |
计算 |
| root_mean_squared_log_error | 均方根对数误差是预期平方对数误差的平方根。 目标:越接近 0 越好 范围:[0, inf) 类型: root_mean_squared_log_error normalized_root_mean_squared_log_error,root_mean_squared_log_error 除以数据范围。 |
计算 |
| spearman_correlation | 斯皮尔曼相关是两个数据集之间的关系单一性的非参数测量法。 与皮尔逊相关不同,斯皮尔曼相关不假设两个数据集呈正态分布。 与其他相关系数一样,斯皮尔曼在 -1 和 +1 之间变化,0 表示不相关。 -1 或 1 相关表示确切的单一关系。 斯皮尔曼是一个秩相关指标,这意味着,如果预测值或实际值的变化不改变预测值或实际值的秩序,则不会改变斯皮尔曼结果。 目标:越接近 1 越好 范围: [-1, 1] |
计算 |
指标规范化
自动化 ML 规范化回归和预测指标,使得在不同范围的数据上训练的模型之间能够进行比较。 在较大范围的数据上训练的模型比在较小范围的数据上训练的模型具有更高的误差,除非该误差已规范化。
虽然没有规范化误差指标的方法,但是自动化 ML 采用的是将误差除以数据范围的通用方法:normalized_error = error / (y_max - y_min)
注意
数据范围不会随模型一起保存。 如果基于维持数据测试集使用同一模型执行推理,则 y_min 和 y_max 可能会根据测试数据发生变化,并且规范化指标不可直接用于比较模型在处理训练集和测试集时的性能。 可以从训练集传入 y_min 和 y_max 的值,以进行公平比较。
预测指标:规范化和聚合
当数据包含多个时序时,计算用于预测模型评估的指标需要考虑一些特殊注意事项。 对于在多个序列上聚合指标,可以采用两种自然选择:
- 宏平均值,其中每个序列的评估指标被赋予相等的权重,
- 微平均值,其中每个预测的评估指标具有相等的权重。
这些用例可直接类比多类分类中的宏平均值和微平均值。
在选择模型选择的主要指标时,宏平均值和微平均值之间的区别可能非常重要。 例如,考虑一个你希望预测所选消费产品需求的零售方案。 有些产品的销量比其他产品高得多。 如果选择微平均 RMSE 作为主要指标,则高销量产品可能会造成大部分建模错误,从而主导该指标。 然后,模型选择算法可能倾向于高销量产品的准确度高于低销量产品的模型。 相比之下,宏平均且规范化的 RMSE 会为低销量产品赋予与高销量产品大致相等的权重。
下表显示了哪些 AutoML 预测指标使用宏与微平均值:
| 宏平均 | 微平均 |
|---|---|
normalized_mean_absolute_error、normalized_median_absolute_error、normalized_root_mean_squared_error、normalized_root_mean_squared_log_error |
mean_absolute_error、median_absolute_error、root_mean_squared_error、root_mean_squared_log_error、r2_score、explained_variance、spearman_correlation、mean_absolute_percentage_error |
请注意,宏平均指标会单独规范化每个序列。 然后对每个序列中的规范化指标求平均值,以得出最终结果。 宏与微的正确选择取决于业务方案,但我们通常建议使用 normalized_root_mean_squared_error。
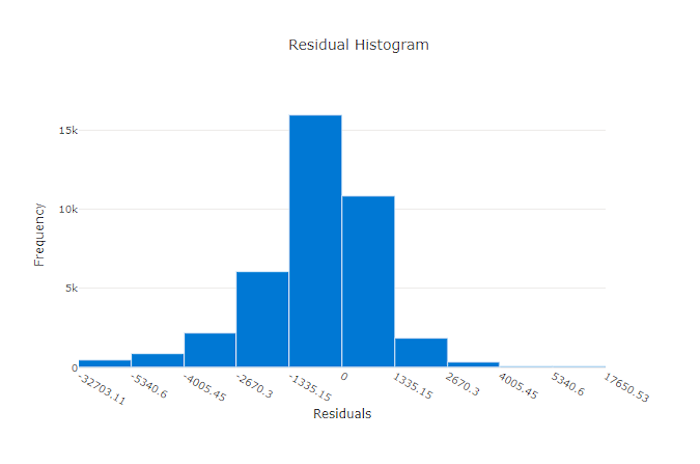
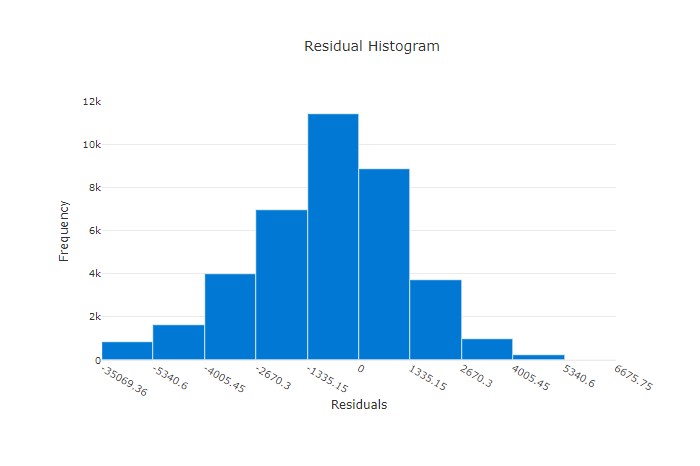
残差
残差图是为回归和预测试验生成的预测误差(残差)的直方图。 所有样本的残差计算为 y_predicted - y_true,然后显示为直方图以显示模型偏差。
在本例中,请注意,两个模型的预测值都略低于实际值。 对于实际目标分布扭曲的数据集来说,这并不罕见,但这表明模型性能较差。 良好的模型会有一个残差分布,在零处达到峰值,而在极值处残差很少。 更糟的模型会有一个分散的残差分布,在零附近有更少的样本。
良好模型的残差图
不良模型的残差图
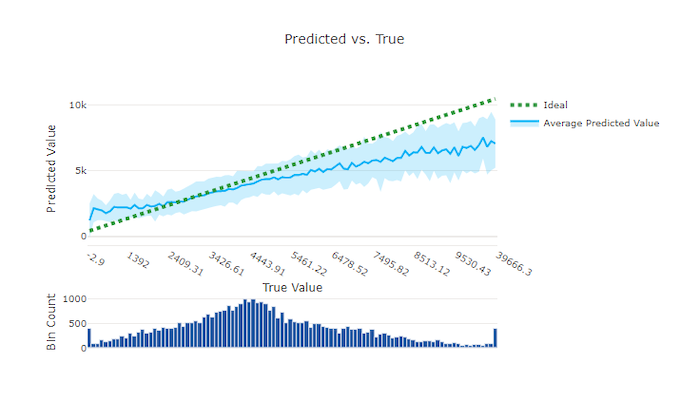
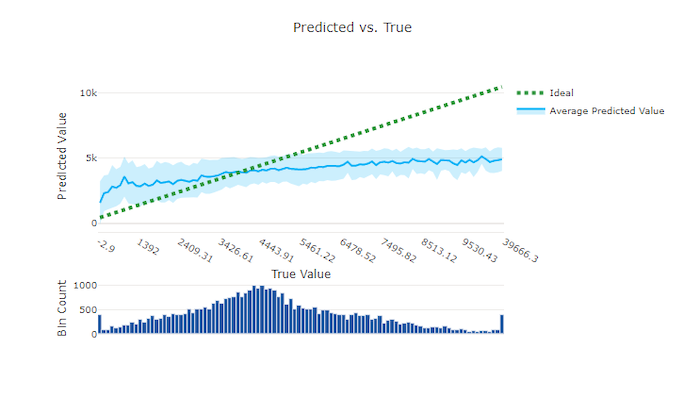
预测值与实际值
对于回归和预测试验,预测与实际图表绘制了目标特征(实际值)与模型预测之间的关系。 实际值沿 x 轴分格,每个分格的平均预测值用误差线绘制。 这允许你查看模型是否偏向于预测某些值。 该行显示平均预测,阴影区域表示围绕该平均值的预测方差。
通常,最常见的实际值将具有最准确的预测和最小的方差。 趋势线与理想 y = x 线之间的距离是一个很好的测量模型在异常值上的表现的方法。 可以使用图表底部的直方图来推断实际的数据分布。 包括更多分布稀疏的数据样本可以提高模型对不可见数据的性能。
在此示例中,请注意,更好的模型有一条更接近理想 y = x 线的预测与实际线。
良好模型的预测与实际图表
不良模型的预测与实际图表
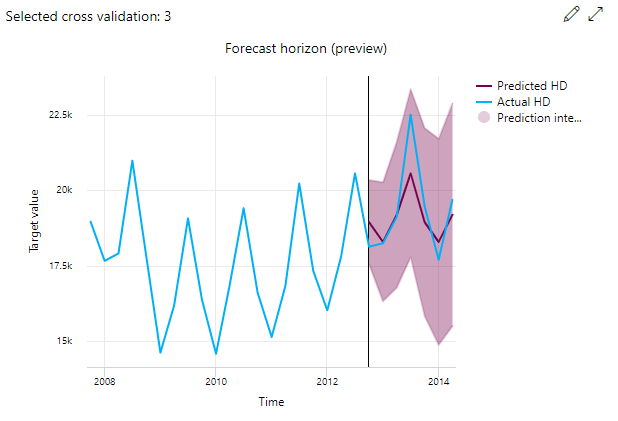
预测边际
对于预测实验,预测范围图表绘制了模型预测值和每次交叉验证逐渐映射的实际值之间的关系,最多可涵盖 5 次交叉验证。 x 轴根据训练设置期间提供的频率映射时间。 图表中的垂直线标记了预测范围点(也称为范围线),即你要开始生成预测的时间段。 在预测范围线左侧,可以查看历史训练数据,以更好地直观呈现过去的趋势。 在预测范围的右侧,可以针对不同的交叉验证折叠和时序标识符,直观呈现预测值(紫线)与实际值(蓝线)。 紫色区域表示围绕该平均值的预测的置信区间或方差。
通过单击图表右上角的编辑铅笔图标,可以选择要显示的交叉验证折叠和时序标识符组合。 从前 5 个交叉验证折叠和最多 20 个不同的时序标识符中进行选择,以直观呈现各种时序的图表。
重要
此图表适用于从训练和验证数据生成的模型的训练运行,以及基于训练数据和测试数据的测试运行。 预测原点之前允许最多 20 个数据点,预测原点之后允许最多 80 个数据点。 对于 DNN 模型,训练运行中的此图表显示上一个时期的数据,即在完全训练模型之后的数据。 如果在训练运行期间显式提供了验证数据,则测试运行中的此图表在边际之前可能存在间隙。 这是因为训练数据和测试数据在测试运行中使用,省去了导致间隙的验证数据。
图像模型的指标(预览版)
自动化 ML 使用验证数据集中的图像来评估模型的性能。 将在循环级别度量模型的性能,以了解训练的进度。 通过神经网络向前和向后传递整个数据集恰好一次后,即表示经过了一次循环。
图像分类指标
评估的主要指标是二元和多类分类模型的准确度,以及多标签分类模型的 IoU(交并比) 。 图像分类模型的分类指标与分类指标部分中定义的相同。 与循环相关的损失值也会记录下来,这有助于监视训练的进度并确定模型是过拟合还是欠拟合。
分类模型的每项预测都与置信度分数相关联,该分数指示做出预测时所用的置信度。 默认使用 0.5 分数阈值评估多标签图像分类模型,这意味着,只有至少达到了此置信度的预测才被视为关联类的正预测。 多类分类不使用分数阈值,而是将置信度分数最高的类视为预测。
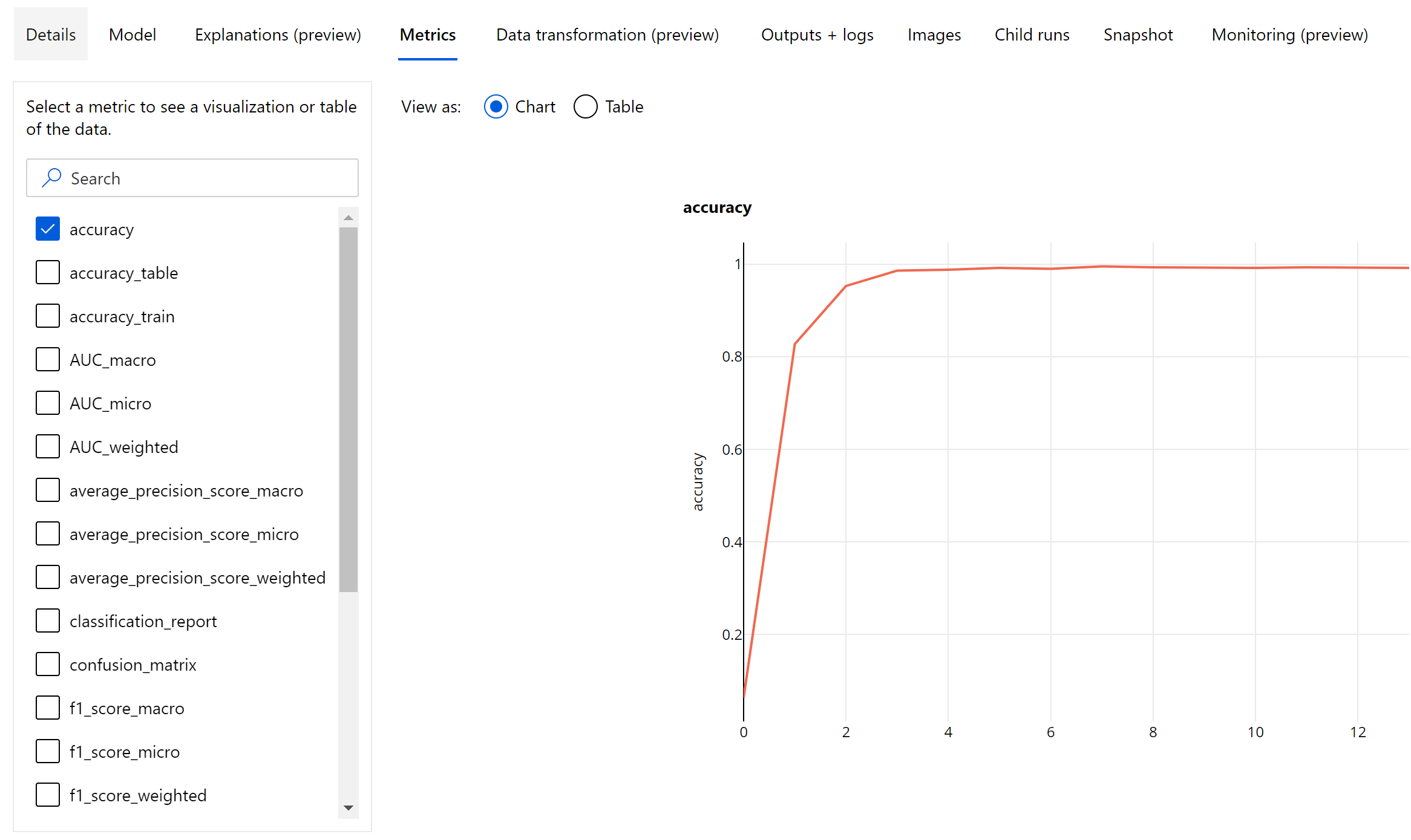
图像分类的循环级别指标
与表格数据集的分类指标不同,图像分类模型在循环级别记录所有分类指标,如下所示。
图像分类的汇总指标
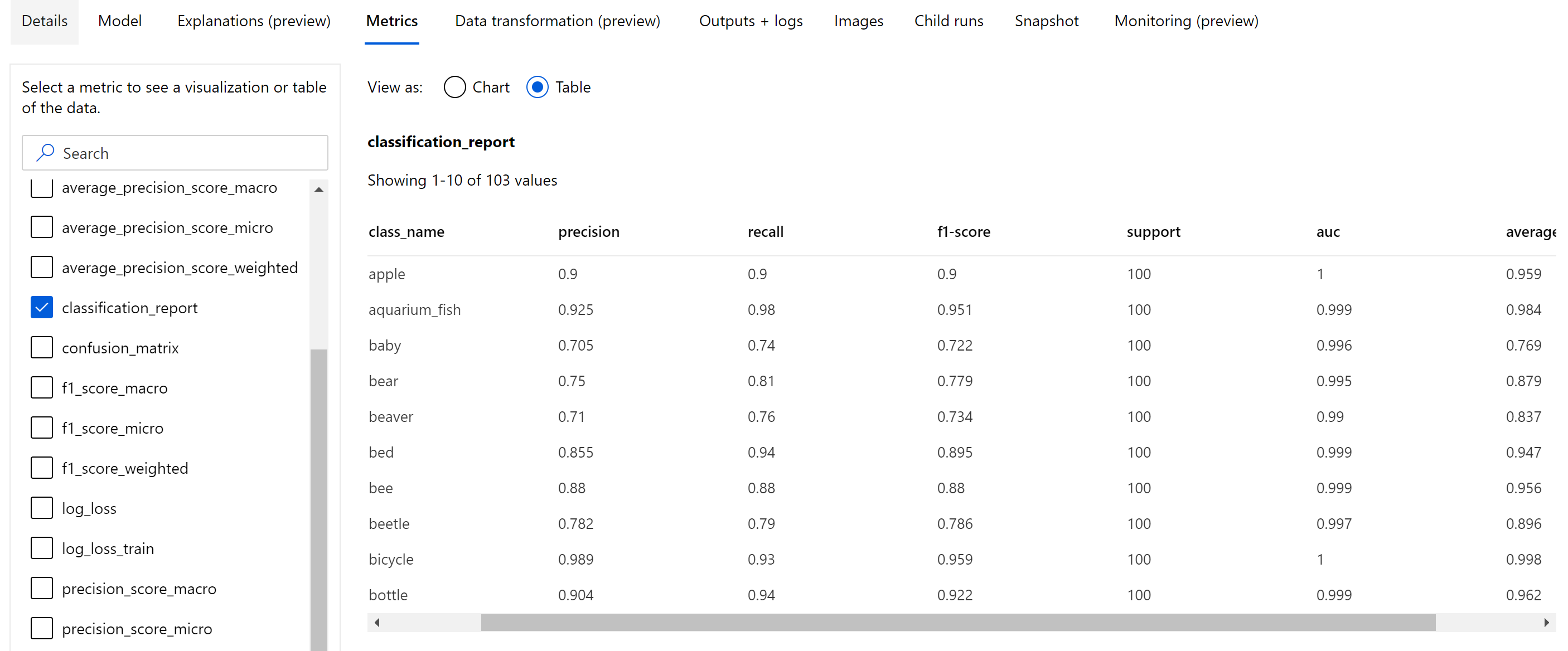
除了在循环级别记录的标量指标外,图像分类模型还会从主要指标(准确度)分数最高的最佳循环记录汇总指标,例如混淆矩阵、分类图表(包括 ROC 曲线、精准率-召回率曲线和模型分类报告)。
分类报告提供精准率、召回率、f1 分数、支持度、auc 和average_precision 等指标的类级别值,以及各种级别的平均值 - 微观、宏观和加权,如下所示。 请参阅分类指标部分中的指标定义。
物体检测和实例分段指标
图像物体检测或实例分段模型的每项预测都与置信度分数相关联。
图像物体检测和实例分段模型的指标计算基于称作 IoU(交并比)的指标所定义的交叠度量。IoU 的计算方式是将真实数据和预测结果之间的交叠面积除以真实数据和预测结果之间的合并面积。 从每项预测计算得出的 IoU 将与称作 IoU 阈值的交叠阈值进行比较。IoU 阈值确定某项预测应与用户批注的真实数据有多大的交叠程度才能被视为正预测。 如果从预测计算得出的 IoU 小于交叠阈值,则不会将该预测视为关联类的正预测。
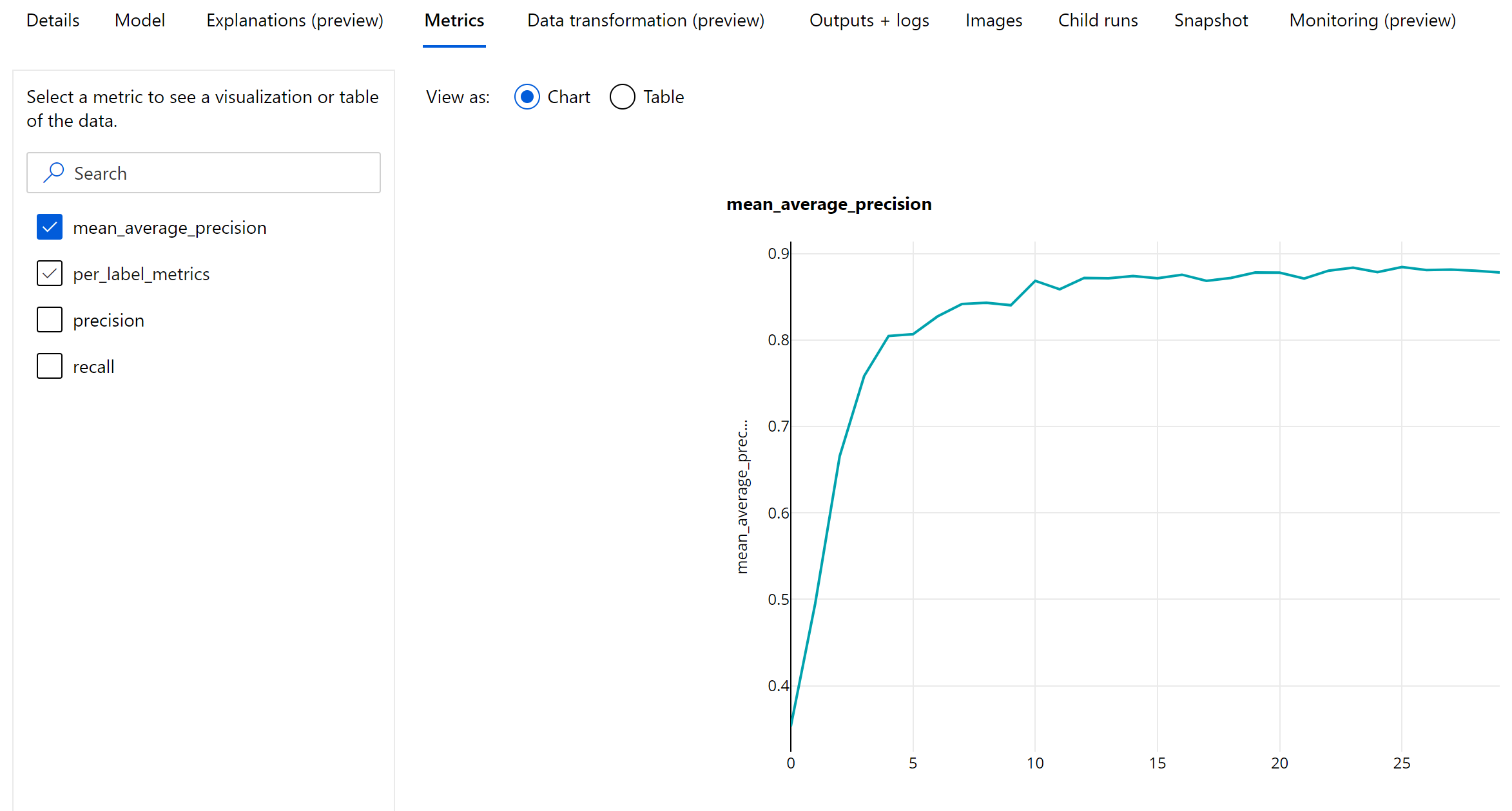
用于评估图像物体检测和实例分段模型的主要指标是平均精准率 (mAP)。 mAP 是所有类的平均精准率 (AP) 的平均值。 自动化 ML 物体检测模型支持使用以下两种常用方法计算 mAP。
Pascal VOC 指标:
Pascal VOC mAP 是物体检测/实例分段模型的默认 mAP 计算方式。 Pascal VOC 式的 mAP 方法计算某个版本的精准率-召回率曲线下的面积。 针对所有唯一召回率值计算第一个 p(rᵢ),即召回率为 i 时的精准率。 然后将 p(rᵢ) 替换为针对 r' >= rᵢ 的任何召回率获取的最大精准率。 在此版本的曲线中,精准率值单调递减。 默认情况下,Pascal VOC mAP 指标是使用 IoU 阈值 0.5 评估的。 此博客中提供了有关此概念的详细说明。
COCO 指标:
COCO 评估方法使用 101 点内插方法进行 AP 计算,并求 10 个以上的 IoU 阈值的平均值。 AP@[.5:.95] 对应于 0.5 到 0.95 范围内的、步长为 0.05 的 IoU 的平均 AP。 自动化 ML 在应用程序日志中记录 COCO 方法定义的所有 12 个指标,包括各个标量的 AP 和 AR(平均召回率),而指标用户界面只显示 IoU 阈值为 0.5 时的 mAP。
用于物体检测和实例分段的循环级别指标
在循环级别记录图像物体检测/实例分段模型的 mAP、精准率和召回值。 还会在类级别记录 mAP、准确率和召回率指标,其日志名称为“per_label_metrics”。 应将“per_label_metrics”视为一个表。
注意
使用“coco”方法时,精准率、召回率和 per_label_metrics 的循环级别指标不可用。
负责任 AI 仪表板,呈现建议的最佳 AutoML 模型(预览)
Azure 机器学习负责任 AI 仪表板提供了统一的界面来帮助你在实践中有效且高效地实现负责任 AI。 负责任 AI 仪表板仅支持使用表格数据,并且仅支持分类和回归模型。 它汇集了多个成熟的负责任 AI 工具用于实现以下方面的需求:
- 模型性能和公平性评估
- 数据研究
- 机器学习可解释性
- 错误分析
虽然模型评估指标和图表适用于衡量模型的总体质量,但检查模型的公平性、查看模型解释(也称为模型用于进行预测的数据集功能)、检查其错误和潜在盲点等操作在践行负责任 AI 方面也是至关重要的。 这就是自动化 ML 提供负责任 AI 仪表板来帮助你观察模型的各种见解的原因。 在 Azure 机器学习工作室中了解如何查看负责任 AI 仪表板。
了解如何通过 UI 或 SDK 生成此仪表板。
模型解释和特征重要性
虽然模型评估指标和图表适用于衡量模型的总体质量,但在践行负责任 AI 时,检查模型用于进行预测的数据集特征也是至关重要的。 这就是自动化 ML 提供模型说明仪表板来测量和报告数据集特征的相对贡献的原因。 请参阅如何在 Azure 机器学习工作室中查看说明仪表板。
注意
可解释性(最佳模型解释)不适用于将以下算法推荐为最佳模型或系综的自动化 ML 预测试验:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- 平均值
- Naive
- Seasonal Average
- Seasonal Naive
后续步骤
- 请参阅自动化机器学习模型解释示例笔记本。
- 对于自动化 ML 特定问题,请联系 askautomatedml@microsoft.com。