教程:开始在 Azure 机器学习中使用 Python 脚本(SDK v1,第 1 部分,共 3 部分)

在本教程中,你将使用 Azure 机器学习在云中运行第一个 Python 脚本。 本教程是由三个部分构成的教程系列的第 1 部分。
本教程避免了训练机器学习模型的复杂性。 你将在云中运行“Hello World”Python 脚本。 你将了解如何使用控制脚本在 Azure 机器学习中配置和创建某个运行。
在本教程中,将:
- 创建并运行“Hello World!”Python 脚本。
- 创建一个 Python 控制脚本,将“Hello world!”提交到 Azure 机器学习。
- 了解控制脚本中的 Azure 机器学习概念。
- 提交并运行“Hello world!”脚本。
- 在云中查看代码输出。
先决条件
- 完成创建入门所需的资源,创建工作区和计算实例以在本教程系列中使用。
-
- 创建基于云的计算群集。 将其命名为“cpu-cluster”,以匹配本教程中的代码。
创建并运行一个 Python 脚本
本教程将使用计算实例作为开发计算机。 首先创建几个文件夹和脚本:
- 登录 Azure 机器学习工作室,然后选择工作区(如果出现提示)。
- 在左侧选择“笔记本”
- 在“文件”工具栏中,选择“+”,然后选择“创建新文件夹”。
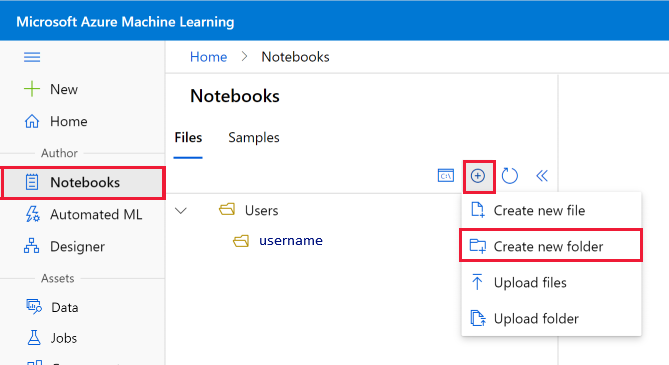
- 将文件夹命名为“get-started”。
- 在文件夹名称的右侧,使用“...”在 get-started 下创建另一个文件夹 。
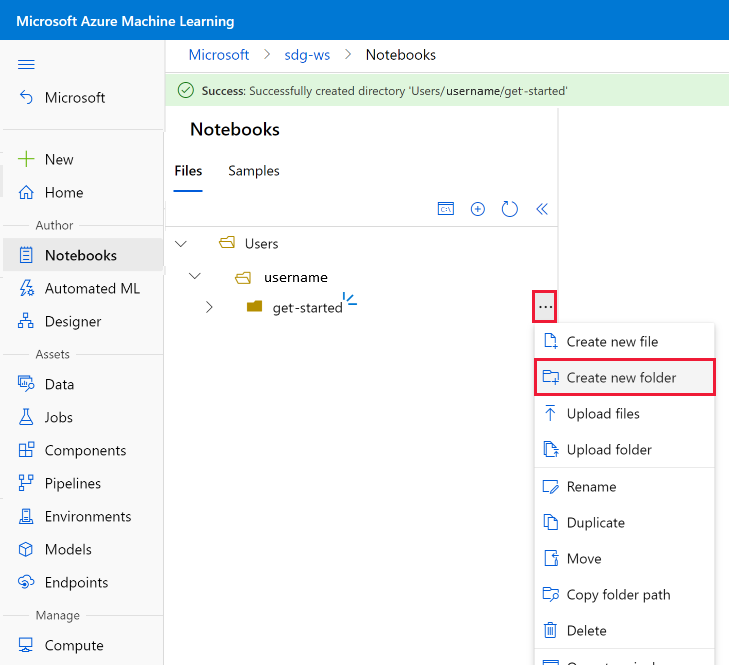
- 将新文件夹命名为“src”。 如果文件位置不正确,请使用“编辑位置”链接。
- 在 src 文件夹的右侧,使用“...”在 src 文件夹中创建新文件 。
- 将文件命名为“hello.py”。 将“文件类型”切换为 Python (.py)*。
将以下代码复制到文件中:
# src/hello.py
print("Hello world!")
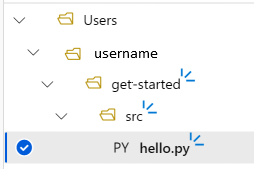
你的项目文件夹结构现在将如下所示:
测试你的脚本
可以在本地运行代码,在本例中意味着在计算实例上运行。 在本地运行代码具有可对代码进行交互式调试的好处。
如果之前已停止计算实例,现在使用计算下拉列表右侧“开始计算”工具启动它。 等待大约一分钟,状态更改为“正在运行”。

选择“保存并在终端中运行脚本”来运行脚本。
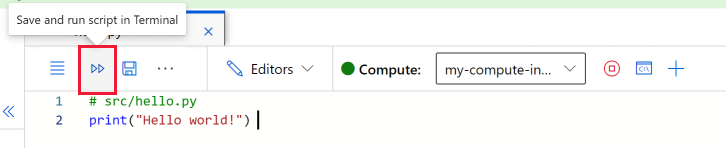
将在打开的终端窗口中看到该脚本的输出。 关闭选项卡,选择“终止”以关闭会话。
创建控制脚本
通过“控制脚本”,你可以在不同的计算资源上运行 hello.py 脚本。 可以使用控制脚本来控制如何运行以及在何处运行机器学习代码。
选择“get-started”文件夹末尾的“...”,创建新文件 。 创建名为 run-hello.py 的新 Python 文件,然后将以下代码复制并粘贴到该文件中:
# get-started/run-hello.py
from azureml.core import Workspace, Experiment, Environment, ScriptRunConfig
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-hello')
config = ScriptRunConfig(source_directory='./src', script='hello.py', compute_target='cpu-cluster')
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
提示
如果在创建计算群集时使用了其他名称,请确保也调整代码中 compute_target='cpu-cluster' 的名称。
了解代码
下面是有关控制脚本工作方式的说明:
ws = Workspace.from_config()
工作区连接到你的 Azure 机器学习工作区,以便你可以与 Azure 机器学习资源通信。
experiment = Experiment( ... )
可以通过试验轻松地将多个作业组织到单个名称下。 稍后,你可以了解如何使用试验轻松地在数十个作业之间比较指标。
config = ScriptRunConfig( ... )
ScriptRunConfig 包装你的 hello.py 代码并将其传递到你的工作区。 顾名思义,你可以使用此类来配置你希望脚本如何在 Azure 机器学习中运行。 此类还会指定该脚本将会在哪个计算目标上运行。 在此代码中,目标是在设置教程中创建的计算群集。
run = experiment.submit(config)
提交脚本。 此提交被称为运行。 在 v2 中,它已重命名为一项作业。 运行/作业会封装代码的单次执行。 可以使用作业来监视脚本进度、捕获输出、分析结果、将指标可视化等。
aml_url = run.get_portal_url()
run 对象提供了一个便于执行你的代码的句柄。 可以使用从 Python 脚本输出的 URL 从 Azure 机器学习工作室中监视代码执行进度。
在云中提交并运行代码
选择“保存并在终端中运行脚本”运行你的控制脚本,该脚本继而会在设置教程中创建的计算群集上运行
hello.py。在终端中,系统可能会要求你登录以进行身份验证。 复制代码,然后访问链接完成此步骤。
经过身份验证后,终端中会显示一个链接。 选择该链接以查看作业。
注意
你可能看到以“加载 azureml_run_type_providers.... 时出错”开头的警告。可以忽略这些警告。 使用这些警告底部的链接查看输出。
查看输出
- 在打开的页面中,你将看到作业状态。
- 作业状态为“已完成”时,选择页面顶部的“输出 + 日志”。
- 选择“std_log.txt”以查看作业的输出。
在工作室的云中监视代码
来自脚本的输出中将包含一个指向工作室的链接,该链接类似于:https://studio.ml.azure.cn/experiments/hello-world/runs/<run-id>?wsid=/subscriptions/<subscription-id>/resourcegroups/<resource-group>/workspaces/<workspace-name>。
访问该链接。 首先,你会看到状态为“已排队”或“正在准备” 。 首次运行将需要 5 - 10 分钟才能完成。 这是因为发生了以下情况:
- docker 映像在云中构建
- 计算群集的大小从 0 个节点调整到 1 个节点
- docker 映像被下载到该计算。
由于 docker 映像已缓存在计算中,因此后续作业要快得多(约 15 秒)。 可以通过在第一次作业完成后重新提交以下代码来进行测试。
请等待大约 10 分钟。 你将看到一条消息,指出作业已完成。 然后使用“刷新”,查看状态更改为“已完成”。 作业完成后,转到“输出 + 日志”选项卡。在那里可以看到 std_log.txt 文件,该文件的内容类似于:
1: [2020-08-04T22:15:44.407305] Entering context manager injector.
2: [context_manager_injector.py] Command line Options: Namespace(inject=['ProjectPythonPath:context_managers.ProjectPythonPath', 'RunHistory:context_managers.RunHistory', 'TrackUserError:context_managers.TrackUserError', 'UserExceptions:context_managers.UserExceptions'], invocation=['hello.py'])
3: Starting the daemon thread to refresh tokens in background for process with pid = 31263
4: Entering Job History Context Manager.
5: Preparing to call script [ hello.py ] with arguments: []
6: After variable expansion, calling script [ hello.py ] with arguments: []
7:
8: Hello world!
9: Starting the daemon thread to refresh tokens in background for process with pid = 31263
10:
11:
12: The experiment completed successfully. Finalizing job...
13: Logging experiment finalizing status in history service.
14: [2020-08-04T22:15:46.541334] TimeoutHandler __init__
15: [2020-08-04T22:15:46.541396] TimeoutHandler __enter__
16: Cleaning up all outstanding Job operations, waiting 300.0 seconds
17: 1 items cleaning up...
18: Cleanup took 0.1812913417816162 seconds
19: [2020-08-04T22:15:47.040203] TimeoutHandler __exit__
在第 8 行,你会看到“Hello world!”输出。
70_driver_log.txt 文件包含来自作业的标准输出。 当你在云中调试远程作业时,此文件会很有用。
后续步骤
在本教程中,你使用了一个简单的“Hello world!”脚本并在 Azure 上运行了它。 你了解了如何连接到 Azure 机器学习工作区、如何创建试验,以及如何将 hello.py 代码提交到云中。
在接下来的教程中,你将在这些知识的基础上通过运行比 print("Hello world!") 更有趣的脚本来进一步学习。
注意
如果你想就此完成本教程系列,不再继续进行下一步,请记得清理你的资源。