快速入门:使用 Synapse Analytics 库中的示例笔记本
在此快速入门中,你将学习如何将 Synapse Analytics 库中的示例机器学习笔记本复制到工作区中,修改并运行它。
先决条件
- Azure Synapse Analytics 工作区,其中 Azure Data Lake Storage Gen2 存储帐户配置为默认存储。 你需要成为所使用的 Data Lake Storage Gen2 文件系统的存储 Blob 数据参与者。
- Azure Synapse Analytics 工作区中的 Spark 池。
将笔记本复制到工作区
打开工作区,然后从主页中选择“学习”。
在“知识中心”,选择“浏览库”。
在库中,选择“笔记本”。
从库中找到并选择笔记本。
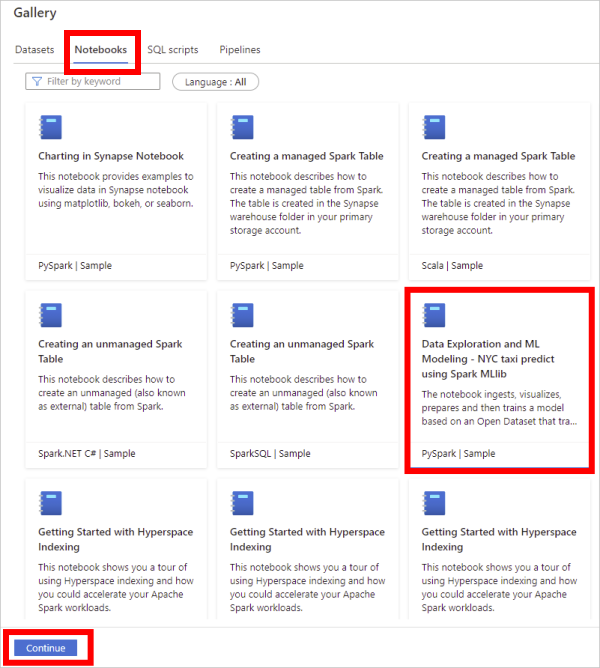
选择“继续”。
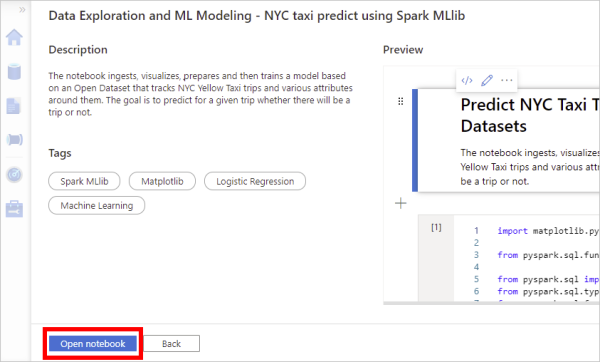
在笔记本预览页上,选择“打开笔记本”。 示例笔记本将复制到工作区并打开。
在打开的笔记本中的“附加到”菜单中,选择 Apache Spark 池。
保存笔记本
若要保存笔记本,请选择工作区命令栏上的“发布”。
复制示例笔记本
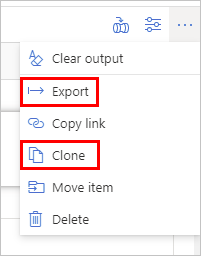
若要创建此笔记本的副本,请单击顶部命令栏中的省略号,然后选择“克隆”以在工作区中创建副本,或选择“导出”以下载笔记本 (.ipynb) 文件的副本。
清理资源
为了确保 Spark 实例在完成操作后关闭,请结束所有已连接的会话(笔记本)。 达到 Apache Spark 池中指定的空闲时间时,池将会关闭。 也可以从笔记本右上角的状态栏中选择“停止会话”。