为适用于大数据的 Azure AI 服务设置环境
为数据生成管道的第一步是设置环境。 环境准备就绪后,可以快速轻松地运行示例。
在本文中,你将执行以下步骤来开始使用:
创建 Azure AI 服务资源
若要在 Azure AI 服务中使用大数据,请先为工作流创建 Azure AI 服务资源。
云服务
基于云的 Azure AI 服务是托管在 Azure 中的智能算法。 这些服务无需培训即可使用,只需要 Internet 连接。 可以在 Azure 门户中为 Azure AI 服务创建资源,也可以使用 Azure CLI 进行创建。
创建 Apache Spark 群集
Apache Spark™ 是为进行大数据数据处理而设计的分布式计算框架。 用户可以通过 Azure Databricks、Azure Synapse Analytics、HDInsight 和 Azure Kubernetes 服务等服务在 Azure 中使用 Apache Spark。 若要使用大数据 Azure AI 服务,必须先创建群集。 如果已有 Spark 群集,请尝试一个示例。
Azure Databricks
Azure Databricks 是一种基于 Apache Spark 的分析平台,其中包含一个一键式设置、简化的工作流和一个交互式工作区。 它通常用于在数据科学家、工程师和业务分析师之间进行协作。 要在 Azure Databricks 上使用大数据 Azure AI 服务,请执行以下步骤:
安装 SynapseML 开源库(或者,如果要支持旧版应用程序,请安装 MMLSpark 库):
在 Databricks 工作区中创建新库
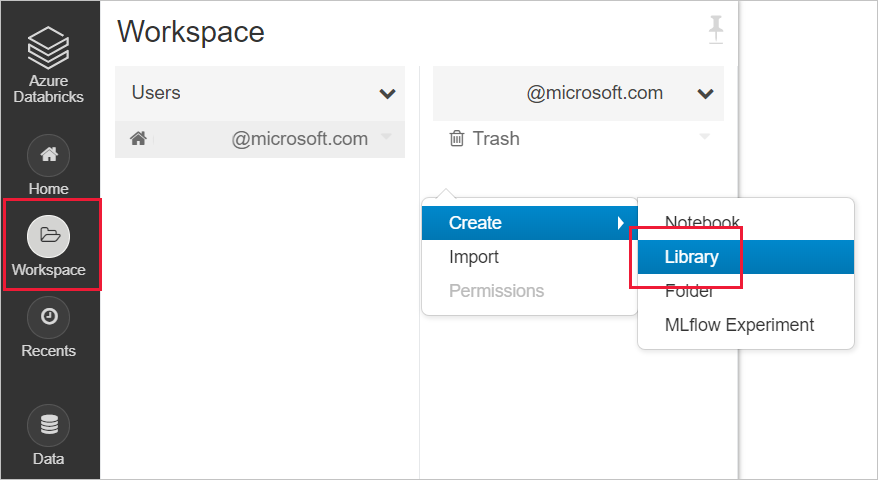
对于 SynapseML:输入以下 maven 坐标的坐标值:
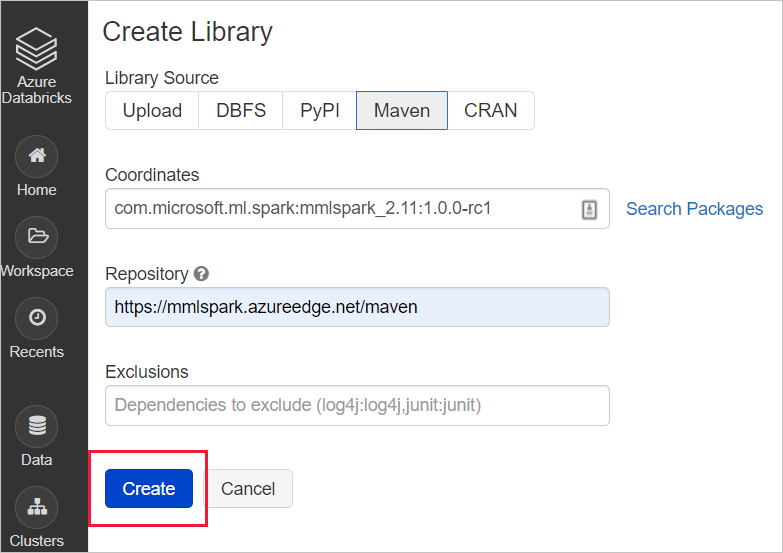
com.microsoft.azure:synapseml_2.12:0.10.0存储库:默认值对于 MMLSpark(旧版):输入以下 maven 坐标的坐标值:
com.microsoft.ml.spark:mmlspark_2.11:1.0.0-rc3存储库:https://mmlspark.azureedge.net/maven
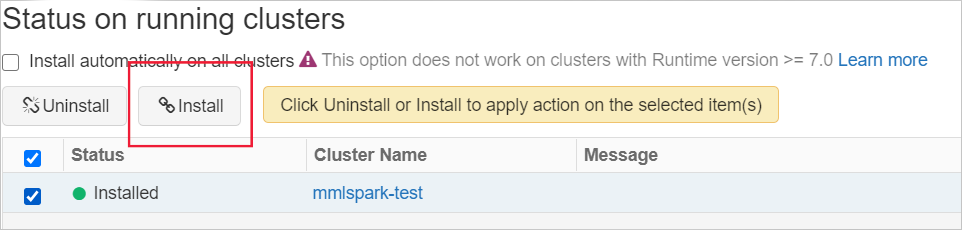
将库安装到群集上
Azure Synapse Analytics(可选)
(可选)你可以使用 Synapse Analytics 来创建 spark 群集。 Azure Synapse Analytics 将企业数据仓库和大数据分析结合在一起。 借助它可以使用无服务器的按需资源或预配资源,任意执行自己定义的大规模数据查询。 若要开始使用 Azure Synapse Analytics,请执行以下步骤:
在 Azure Synapse Analytics 中,会默认安装用于 Azure AI 服务的大数据。
尝试示例
在设置 Spark 群集和环境后,可以运行一个简短示例。 此示例假定 Azure Databricks 和 mmlspark.cognitive 包。 有关使用 synapseml.cognitive 的示例,请参阅使用 SynapseML 从 Apache Spark 向 AI 扩充的数据添加搜索。
首先,可以在 Azure Databricks 中创建笔记本。 对于其他 Spark 群集提供程序,请使用其笔记本或 Spark Submit。
通过从“Azure Databricks”菜单中选择“新建笔记本”,创建新的 Databricks 笔记本 。

在“创建笔记本”中输入一个名称,选择“Python”作为语言,并选择前面创建的 Spark 群集。
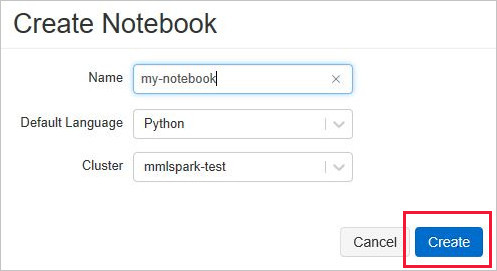
选择创建。
将此代码片段粘贴到新的笔记本中。
from mmlspark.cognitive import * from pyspark.sql.functions import col df = spark.createDataFrame([ ("I am so happy today, its sunny!", "en-US"), ("I am frustrated by this rush hour traffic", "en-US"), ("The Azure AI services on spark aint bad", "en-US"), ], ["text", "language"]) # Add your region and subscription key from the Language service sentiment = (TextSentiment() .setTextCol("text") .setUrl("https://<service_region>.api.cognitive.azure.cn/text/analytics/v3.0/sentiment")setLocation(service_region) .setSubscriptionKey(<service_key>) .setOutputCol("sentiment") .setErrorCol("error") .setLanguageCol("language")) results = sentiment.transform(df) # Show the results in a table display(results.select("text", col("sentiment")[0].getItem("score").alias("sentiment")))从 Azure 门户中的语言资源的“密钥和终结点”菜单中获取你的区域和订阅密钥。
将 Databricks 笔记本代码中的区域和订阅密钥占位符替换为对资源有效的值。
选择笔记本单元格右上角的“播放”或“三角形”符号以运行该示例。 (可选)选择笔记本顶部的“运行所有”以运行所有单元格。 答案将显示在表中的单元格下方。
预期结果
| text | 情绪 |
|---|---|
| 今天天气晴朗,我真高兴! | 0.978959 |
| 交通高峰期让我很郁闷 | 0.0237956 |
| Spark 上的 Azure AI 服务还不错 | 0.888896 |