文档处理模型
此内容适用于:![]() v2.1
v2.1
Azure AI 文档智能支持多种模型,让你能够向应用和流添加智能文档处理。 你可以使用预生成的特定于域的模型,或者训练根据特定业务需求和用例定制的自定义模型。 文档智能可与 REST API 或 Python、C#、Java 和 JavaScript 客户端库一起使用。
注意
- 涉及财务数据、受保护健康信息数据、个人身份数据或高度敏感数据的文档处理项目需要认真考虑。
- 确保遵守所有国家/地区和行业特定的要求。
模型概述
下表显示了每个当前预览版和稳定 API 的可用模型:
| 模型类型 | 型号 | • 2024-02-29-preview • 2023-10-31-preview |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| 文档分析模型 | 读取 | ✔️ | ✔️ | ✔️ | 不适用 |
| 文档分析模型 | 布局 | ✔️ | ✔️ | ✔️ | ✔️ |
| 文档分析模型 | 常规文档 | 已移动到布局** | ✔️ | ✔️ | 不适用 |
| 预生成的模型 | 合约 | ✔️ | ✔️ | 不适用 | 不适用 |
| 预生成的模型 | 医疗保险卡 | ✔️ | ✔️ | ✔️ | 不适用 |
| 预生成的模型 | ID 文档 | ✔️ | ✔️ | ✔️ | ✔️ |
| 预生成的模型 | 发票 | ✔️ | ✔️ | ✔️ | ✔️ |
| 预生成的模型 | 回执 | ✔️ | ✔️ | ✔️ | ✔️ |
| 预生成的模型 | 美国统一税* | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 美国税务 1040* | ✔️ | ✔️ | 不适用 | 不适用 |
| 预生成的模型 | 美国税务 1098* | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 美国税务 1099* | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 美国税务 W2 | ✔️ | ✔️ | ✔️ | 不适用 |
| 预生成的模型 | 美国抵押贷款 1003 URLA | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 美国抵押贷款 1004 URAR | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 美国抵押贷款 1005 | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 美国抵押贷款 1008 摘要 | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 美国按揭过户信息披露 | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 结婚证 | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 信用卡 | ✔️ | 不适用 | 不适用 | 不适用 |
| 预生成的模型 | 名片 | 已弃用 | ✔️ | ✔️ | ✔️ |
| 自定义分类模型 | 自定义分类器 | ✔️ | ✔️ | 不适用 | n/a |
| Customextraction 模型 | 自定义模板 | ✔️ | ✔️ | ✔️ | ✔️ |
| 自定义提取模型 | 自定义组合 | ✔️ | ✔️ | ✔️ | ✔️ |
| 所有模型 | 附加功能 | ✔️ | ✔️ | 不适用 | n/a |
* - 包含子模型。 有关支持的变体和子类型,请参阅模型特定的信息。
延迟
延迟是 API 服务器处理传入请求并将传出响应传递给客户端所需的时间。 分析文档的时间取决于文档的大小(例如,页数)和每一页上的关联内容。 文档智能是一项多租户的服务,其中类似文档的延迟差不多,但并不总是相同。 在大规模处理图像和大型文档的任何基于微服务的无状态异步服务中,延迟和性能的偶尔变化都是固有的。 虽然我们在不断扩展硬件和容量以及扩展功能,但你可能仍会在运行时遇到延迟问题。
| 加载项功能 | 加载项/免费 | • 2024-02-29-preview &bullet [2023-10-31-preview](https://learn.microsoft.com/rest/api/aiservices/operation-groups?view=rest-aiservices-v4.0%20(2024-07-31-preview)&preserve-view=true|[`2023-07-31` (GA)](https://learn.microsoft.com/rest/api/aiservices/document-models/analyze-document?view=rest-aiservices-2023-07-31&preserve-view=true&tabs=HTTP) |
2022-08-31(正式发布) |
v2.1 (GA) | |
|---|---|---|---|---|---|
| 字体属性提取 | 附加功能 | ✔️ | ✔️ | 不适用 | 不适用 |
| 公式提取 | 附加功能 | ✔️ | ✔️ | 不适用 | 不适用 |
| 高分辨率提取 | 附加功能 | ✔️ | ✔️ | 不适用 | 不适用 |
| 条形码提取 | 免费 | ✔️ | ✔️ | 不适用 | 不适用 |
| 语言检测 | 免费 | ✔️ | ✔️ | 不适用 | 不适用 |
| 键值对 | 免费 | ✔️ | 不适用 | 不适用 | 不适用 |
| 查询字段 | 附加功能* | ✔️ | 不适用 | 不适用 | n/a |
| 可搜索 pdf | 附加功能* | ✔️ | 不适用 | 不适用 | 不适用 |
模型分析功能
| 模型 ID | 内容提取 | 查询字段 | 段落 | 段落角色 | 选择标记 | 表 | 键值对 | 语言 | 条形码 | 文档分析 | 公式* | 字体样式* | 高分辨率* | 可搜索 PDF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| prebuilt-read | ✓ | O | O | O | O | O | ✓ | |||||||
| 预生成布局 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |||
| 预生成文档 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| prebuilt-businessCard | ✓ | ✓ | ✓ | |||||||||||
| prebuilt-contract | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| 预生成的发票 | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
| prebuilt-receipt | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-check.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-payStub.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-bankStatement | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1004 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1005 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099(变体) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1040(variations) | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - 已启用
O - 可选
* - 高级功能会产生额外费用
附加功能* - 查询字段的定价与其他附加功能不同。 有关详细信息,请参阅定价。
边界框和多边形坐标
边界框(v3.0 及更高版本中的 polygon)是一个抽象的矩形,在文档中环绕文本元素,用作物体检测的参考点。
边界框使用包含四个数值对的数组中的 x 和 y 坐标平面指定位置。 每对按以下顺序代表框的一个角:左上、右上、右下、左下。
图像坐标以像素来表示。 对于 PDF,坐标以英寸来表示。
对于除业务卡模型以外的所有模型,文档智能现在都支持附加功能,以便进行更复杂的分析。 根据文档提取方案,可以启用和禁用这些可选功能。 2023-07-31 (GA) 及更高版本的 API 有七项附加功能:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview、2023-10-31-preview)queryFields(2024-02-29-preview、2023-10-31-preview)Not available with the US.Tax modelssearchablePDF(2024-07-31-preview)Only available for Read Model
语言支持
文档智能中基于深度学习的通用模型支持许多语言,可以从图像和文档中提取多语言文本,包括用几种语言的文本行。 语言支持因文档智能服务的功能而异。 有关完整列表,请参阅以下文章:
区域可用性
文档智能已在 Azure 全球基础结构区域中的许多区域中正式发布。
模型详细信息
本部分描述每个模型的预期输出。 可以使用附加功能扩展大多数模型的输出。
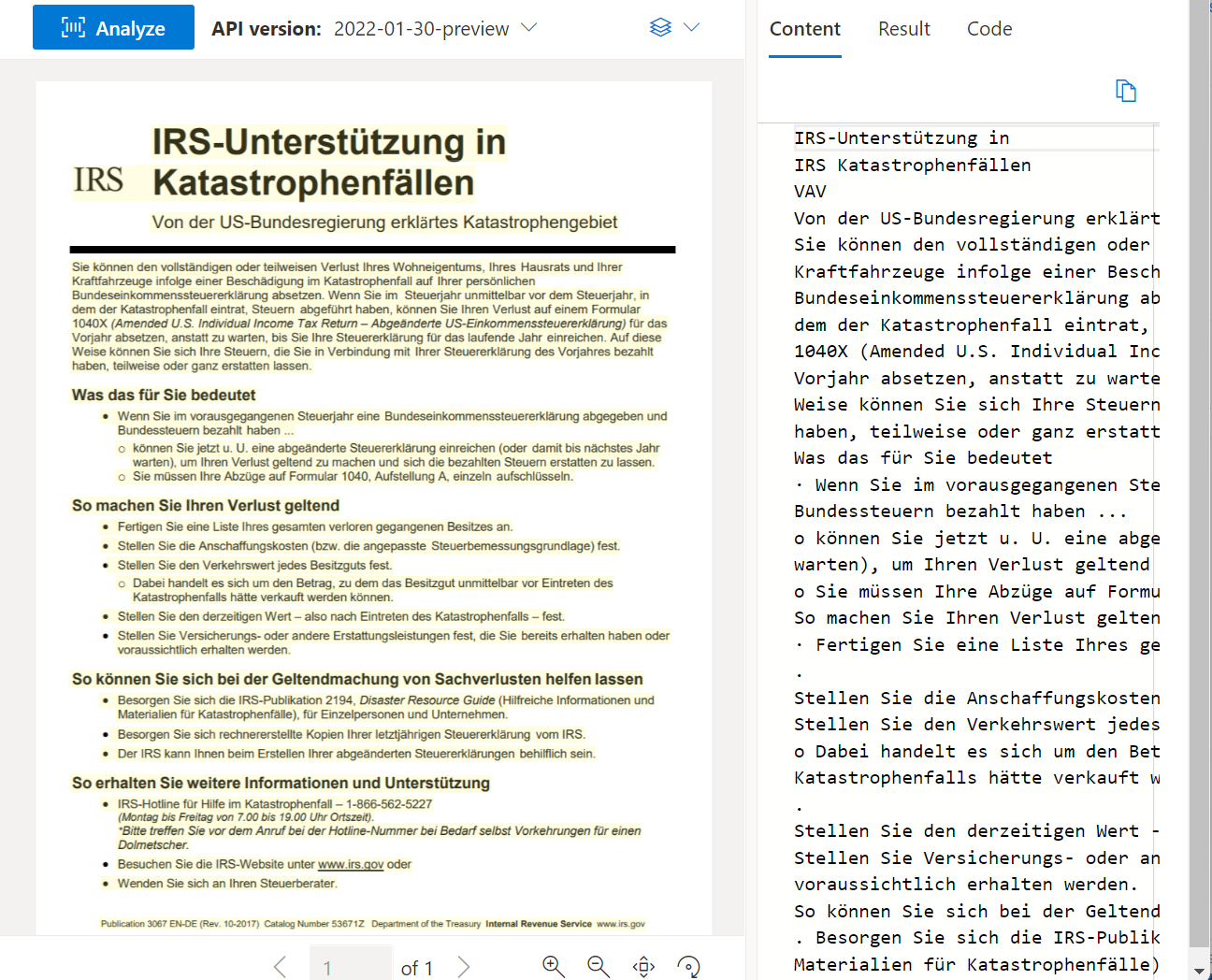
读取 OCR

该读取 API分析并提取行、字词、其位置、检测到的语言以及手写样式(如果检测到)。
使用文档智能工作室处理的示例文档:
布局分析
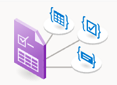
布局分析模型分析和提取文本、表、选择标记和其他结构元素,如标题、章节标题、页眉、页脚。
使用文档智能工作室处理的示例文档:
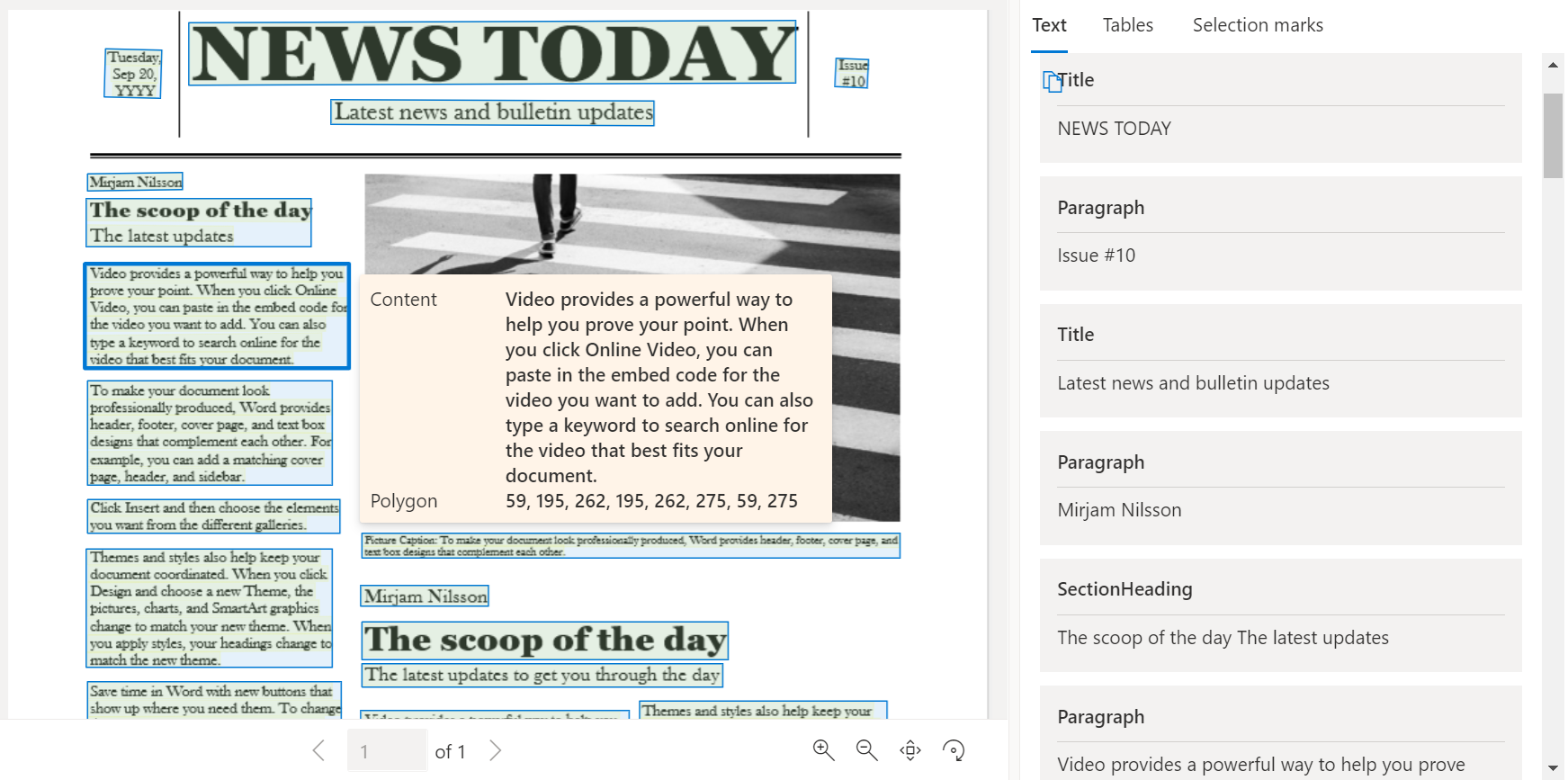
医疗保险卡
![]()
医疗保险卡模型将强大的光学字符识别 (OCR) 功能与深度学习模型相结合,可从美国医疗保险卡中分析和提取关键信息。
使用文档智能工作室处理的美国医疗保险卡示例:

美国税务文档

美国税务文件模型可从一组选定的税务文件中分析和提取关键字段和细列项目。 API 支持分析各种格式和质量的英语美国税务文档,包括手机捕获的图像、扫描的文档和数字 PDF。 当前支持以下模型:
| 型号 | 说明 | ModelID |
|---|---|---|
| 美国税务 W-2 | 提取应纳税所得详细信息。 | prebuilt-tax.us.W-2 |
| 美国税务 1040 | 提取抵押贷款利息详细信息。 | prebuilt-tax.us.1040(variations) |
| 美国税务 1098 | 提取抵押贷款利息详细信息。 | prebuilt-tax.us.1098(variations) |
| 美国税务 1099 | 提取从雇主以外的来源获得的收入。 | prebuilt-tax.us.1099(变体) |
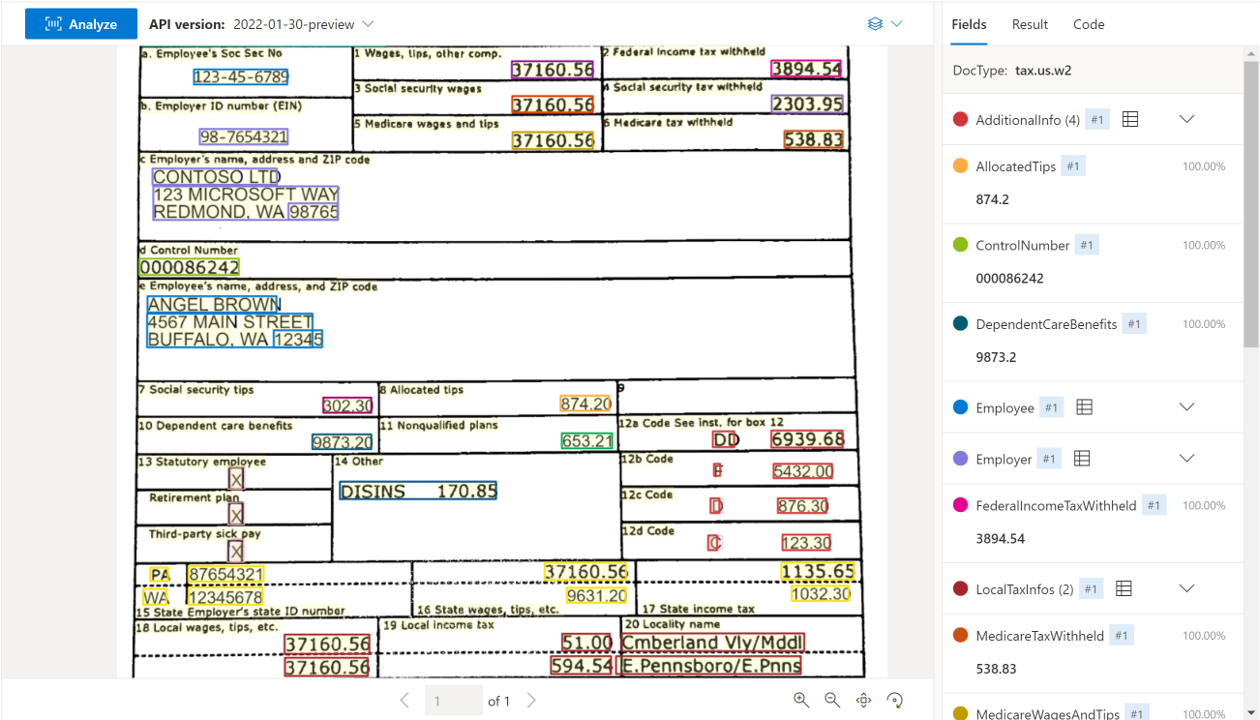
使用文档智能工作室处理的示例 W-2 文档:
美国抵押贷款文档

美国抵押贷款文档模型从一组选定的抵押贷款文档中分析和提取关键字段,包括借款人、贷款和财产信息。 API 支持分析各种格式和质量的英语美国抵押贷款文档,包括手机捕获的图像、扫描的文档和数字 PDF。 当前支持以下模型:
| 型号 | 说明 | ModelID |
|---|---|---|
| 1003 最终用户许可协议 (EULA) | 提取贷款、借款人、财产详细信息。 | prebuilt-mortgage.us.1003 |
| 1008 摘要文档 | 提取借款人、卖方、财产、抵押贷款和承销详细信息。 | prebuilt-mortgage.us.1008 |
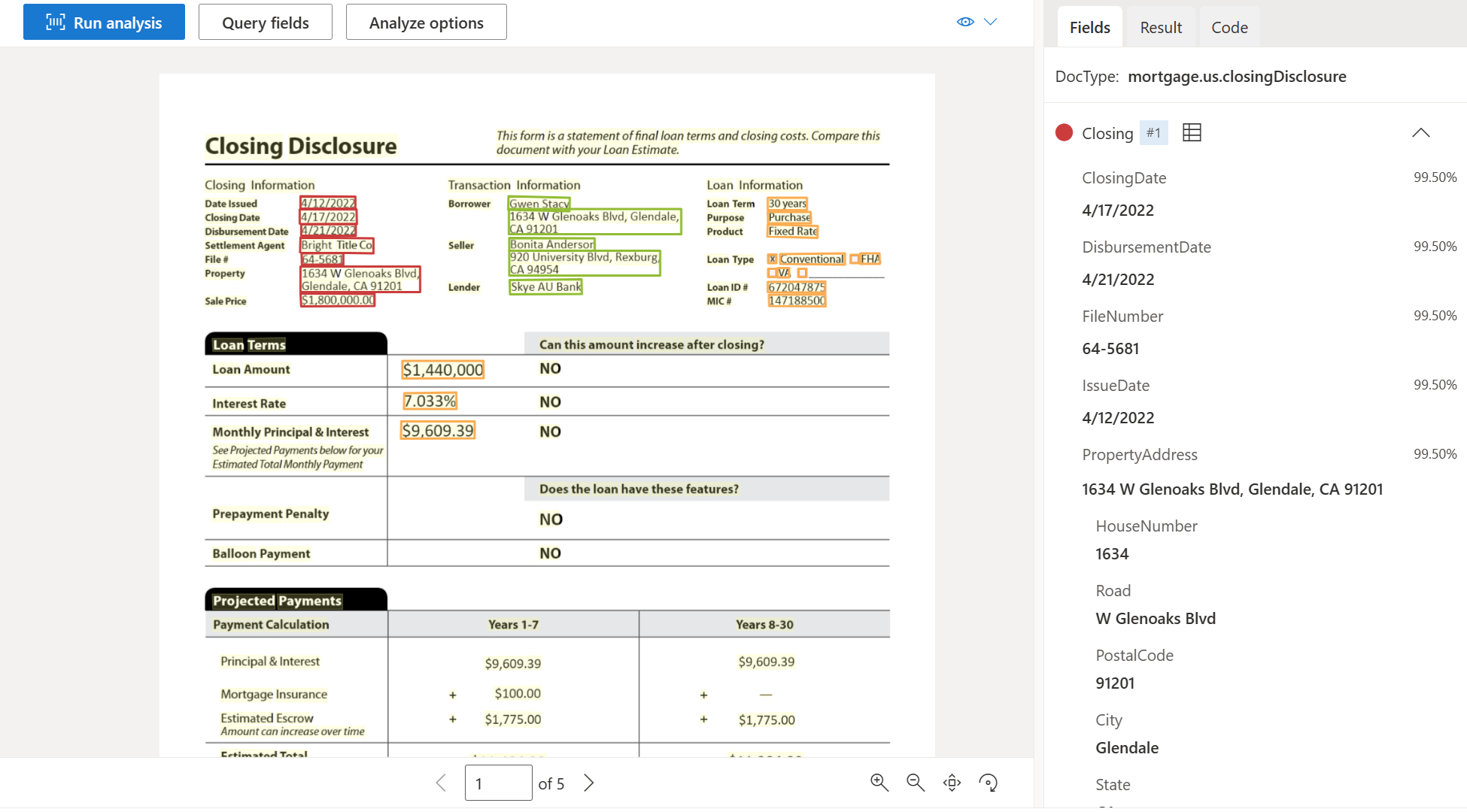
| 核定贷款 | 提取核定贷款、交易成本和贷款详细信息。 | prebuilt-mortgage.us.closingDisclosure |
| 结婚证 | 提取联合贷款申请人的婚姻详细信息。 | prebuilt-marriageCertificate |
| 美国税务 W-2 | 提取应纳税薪酬详细信息进行收入核实。 | prebuilt-tax.us.W-2 |
使用文档智能工作室处理的示例核定贷款文档:
合约
![]()
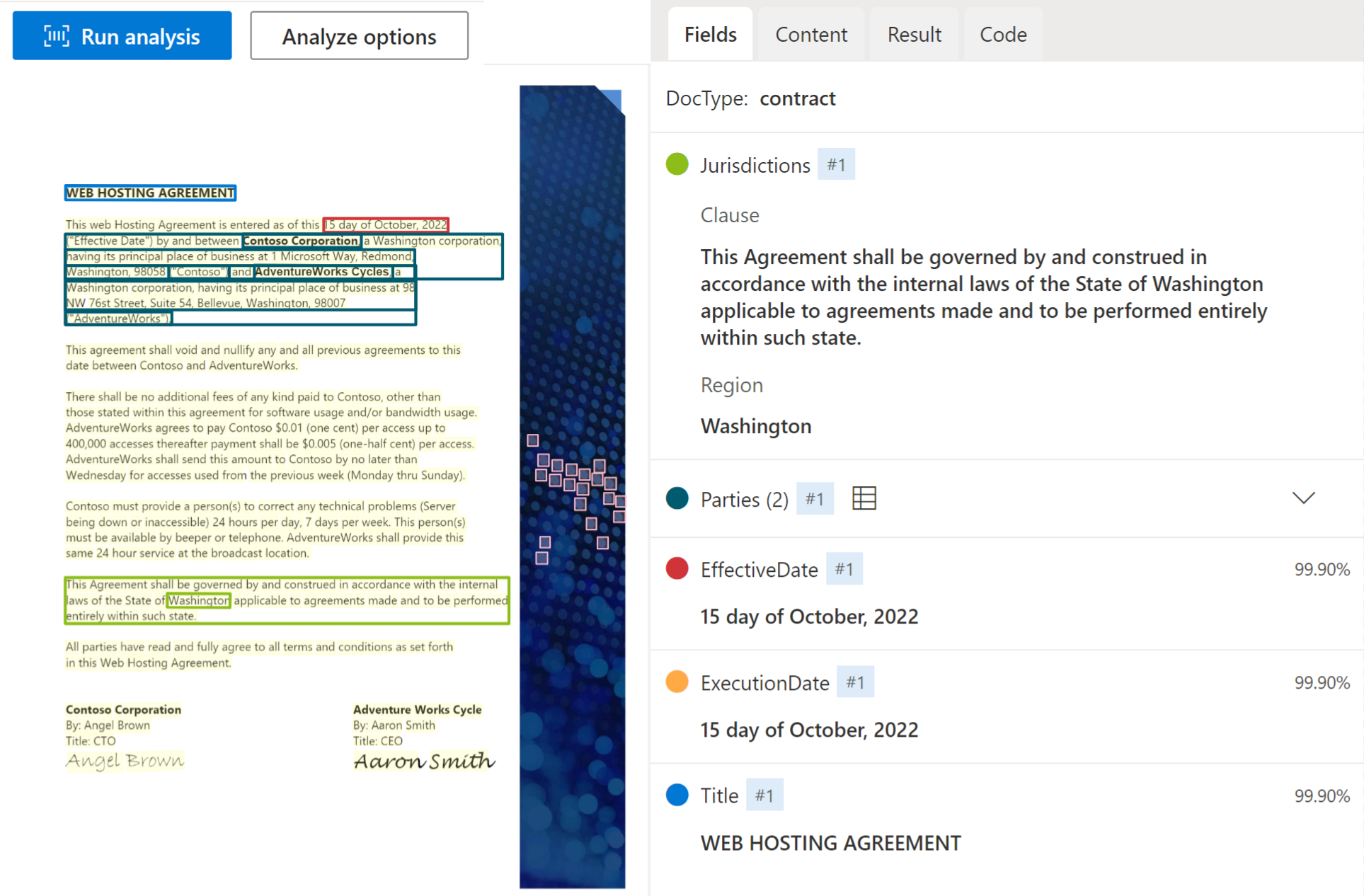
合同模型从合同协议中提取关键字段和行项并进行分析,包括合同各方、司法管辖区、合同 ID 和标题。 该模型当前支持英语合同文档。
使用文档智能工作室处理的示例合同:
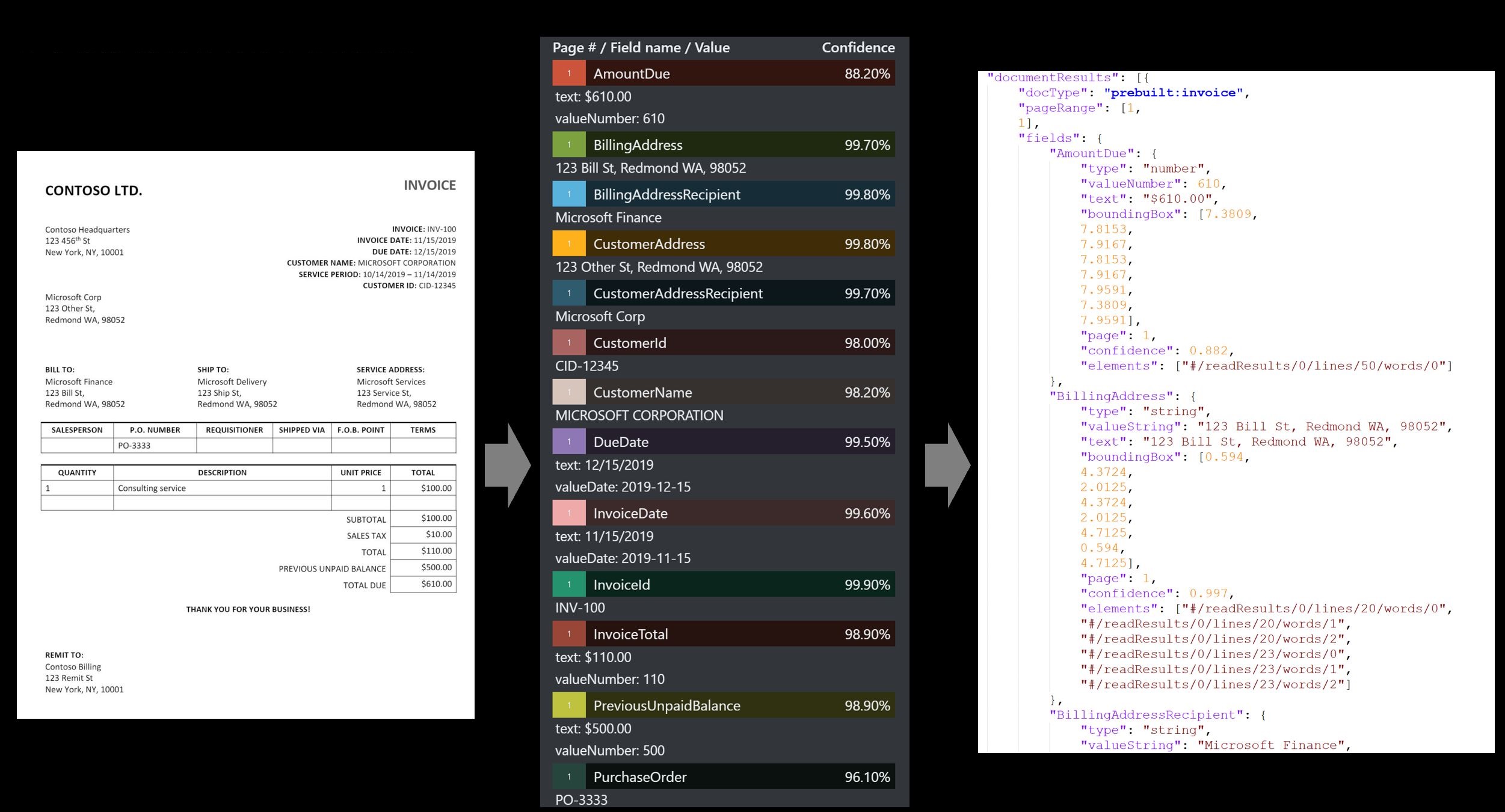
发票
发票模型自动处理发票,以提取客户姓名、帐单邮寄地址、截止日期和到期金额、行项和其他关键数据。 目前,该模型支持英语、西班牙语、德语、法语、意大利语、葡萄牙语和荷兰语发票。
使用文档智能工作室处理的示例发票:

回执
使用收据模型,扫描印刷体和手写体销售收据中的商家名称、日期、行项、数量和总计。 版本 v3.0 还支持单页酒店收据处理。
使用文档智能工作室处理的示例收据:

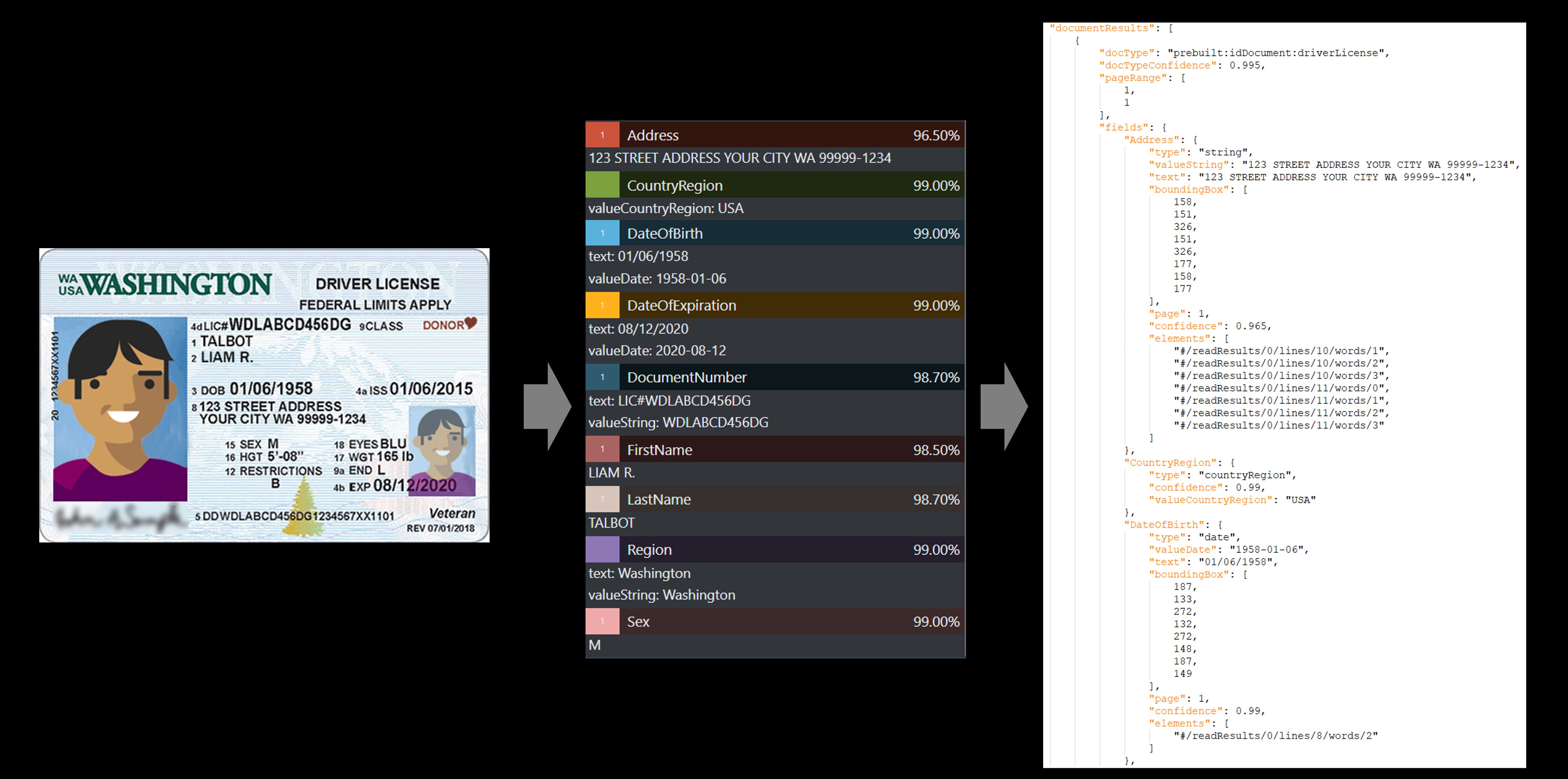
身份文档 (ID)

使用身份文档 (ID) 模型处理美国驾照(所有 50 个州和哥伦比亚特区)和国际护照个人资料页(不包括签证和其他旅行文档),以提取关键字段。
使用文档智能工作室处理的美国驾照示例:

结婚证
![]()
使用结婚证书模型处理美国结婚证以提取关键字段,包括个人、日期和地点。
使用文档智能工作室处理的示例美国结婚证:

信用卡
![]()
使用信用卡模型处理信用卡和借记卡以提取关键字段。
使用文档智能工作室处理的示例信用卡:

自定义模式

自定义模型大致可分为两种类型。 支持“文档类型”分类的自定义分类模型,以及可以从特定文档类型中提取定义的架构的自定义提取模型。
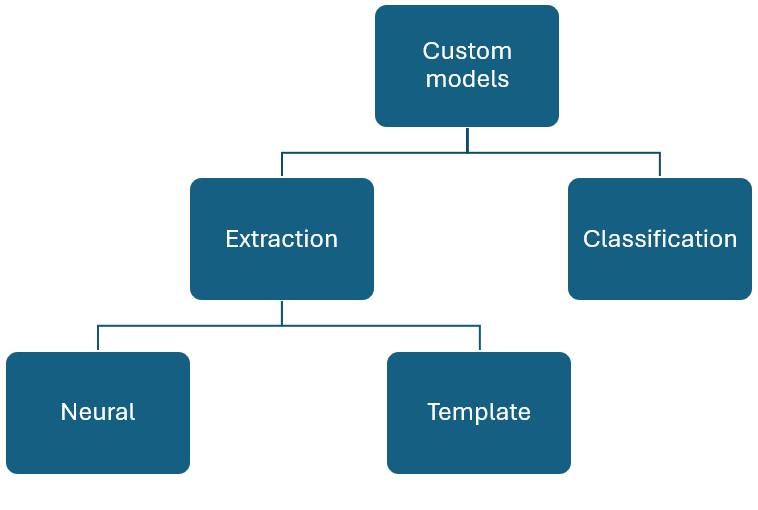
自定义文档模型会分析和提取特定于企业的表单和文档中的数据。 它们可识别不同内容中的表单字段并提取键值对和表数据。 只需一个表单类型示例即可开始。
版本 v3.0 及更高版本的自定义模型支持自定义模板(表单)中的签名检测,以及模板模型和神经网络模型中的跨页表。 签名检测检测是否存在某个签名,而不是文档签名者的标识。 如果模型在执行签名检测时返回“未签名”,则表示模型未在定义的字段中找到签名。
使用文档智能工作室处理的自定义模板示例:
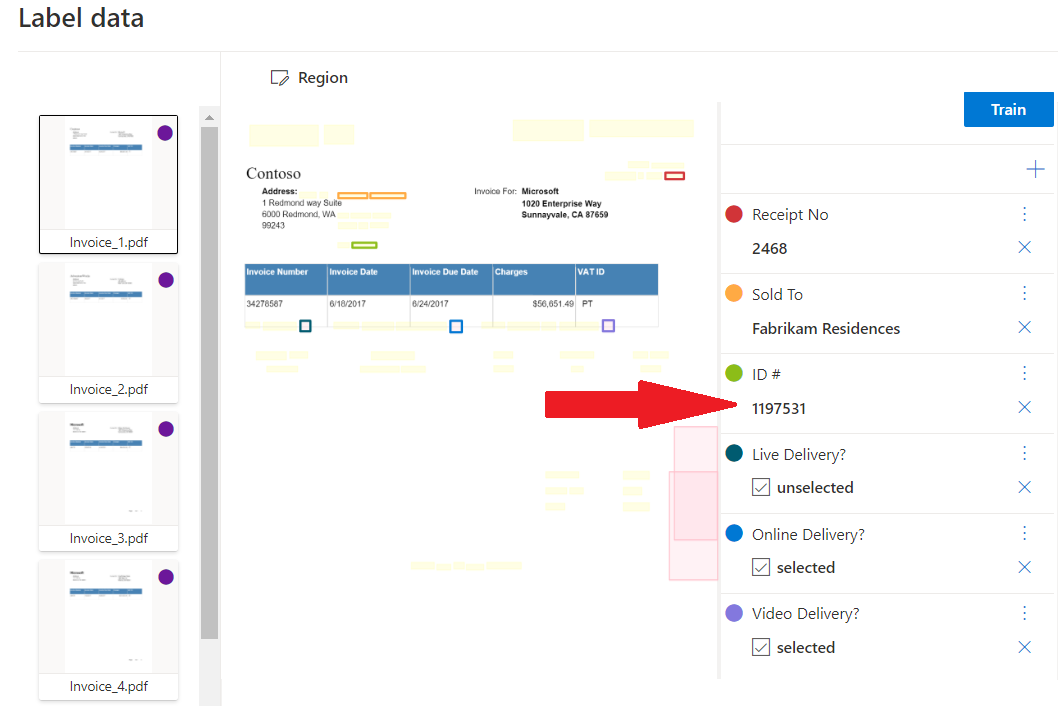
自定义提取

自定义提取模型可以是自定义模板。 若要创建自定义提取模型,请标记包含要提取的值的文档数据集,并基于标记的数据集训练模型。 只需要有五个相同表单或文档类型的示例即可开始。
使用文档智能工作室处理的自定义提取示例:

自定义分类器

自定义分类模型可让你在调用提取模型之前标识文档类型。 该分类模型从 2023-07-31 (GA) API 开始提供。 训练自定义分类模型需要至少两个不同的类,且每个类至少需要五个样本。
组合模型
组合模型的创建方式是采用自定义模型的集合并将其分配到基于你的表单类型构建的单个模型。 可以将多个自定义模型分配给使用单个模型 ID 调用的组合模型。 最多可将 200 个经过训练的自定义模型分配到单个组合模型。
文档智能工作室中的组合模型对话框窗口:
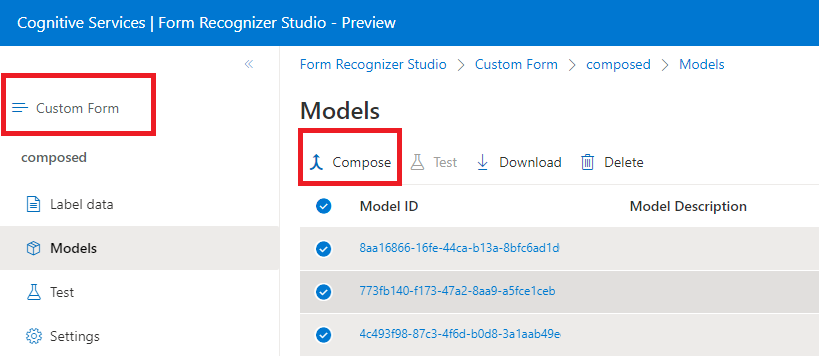
输入要求
支持的文件格式:
型号 PDF 图像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML读取 ✔ ✔ ✔ 布局 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview、2023-10-31-preview) 常规文档 ✔ ✔ 预生成 ✔ ✔ 自定义提取 ✔ ✔ 自定义分类 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview) 为获得最佳结果,请针对每个文档提供一张清晰的照片或高质量的扫描件。
对于 PDF 和 TIFF,最多可处理 2,000 页(对于免费层订阅,仅处理前两页)。
用于分析文档的文件大小对于付费 (S0) 层为 500 MB,对于免费 (F0) 层为
4MB。图像尺寸必须介于 50 像素 x 50 像素与 10,000 像素 x 10,000 像素之间。
如果 PDF 是密码锁定的文件,则必须先删除锁,然后才能提交它们。
对于 1024 x 768 像素的图像,要提取的文本的最小高度为 12 像素。 此尺寸对应于 150 点/英寸 (DPI) 的大约
8号字文本。对于自定义模型训练,自定义模板模型的训练数据最大页数为 500,自定义神经模型的训练数据最大页数为 50,000。
对于自定义提取模型训练,模板模型的训练数据总大小为 50 MB,神经网络模型的训练数据总大小为
1GB。对于自定义分类模型训练,训练数据总大小为
1GB,上限为 10,000 页。 对于 2024-07-31-preview 及更高版本,训练数据总大小为2GB,上限为 10,000 页。
注意
示例标记工具不支持 BMP 文件格式。 这是工具的一项限制,而不是文档智能服务的限制。
版本迁移
若要了解如何在应用程序中使用文档智能 v3.0,请按照我们的文档智能 v3.1 迁移指南操作
| 型号 | 描述 |
|---|---|
| 文档分析 | |
| 布局 | 从文档中提取文本和布局信息。 |
| 预生成 | |
| 发票 | 从英语版发票和西班牙语版发票中提取关键信息。 |
| 回执 | 从英语版收据中提取关键信息。 |
| 身份文档 | 从美国驾照和国际护照中提取关键信息。 |
| 名片 | 从英语版名片中提取关键信息。 |
| 自定义 | |
| 自定义 | 从特定于企业的表单和文档中提取数据。 自定义模型针对不同的数据和用例进行训练。 |
| 组合 | 组合一批自定义模型,并将其分配给基于你的表单类型构建的单个模型。 |
Layout
布局 API 可分析和提取文档中的文本、表、标题、选择标记和结构信息。
使用示例标记工具处理的示例文档:
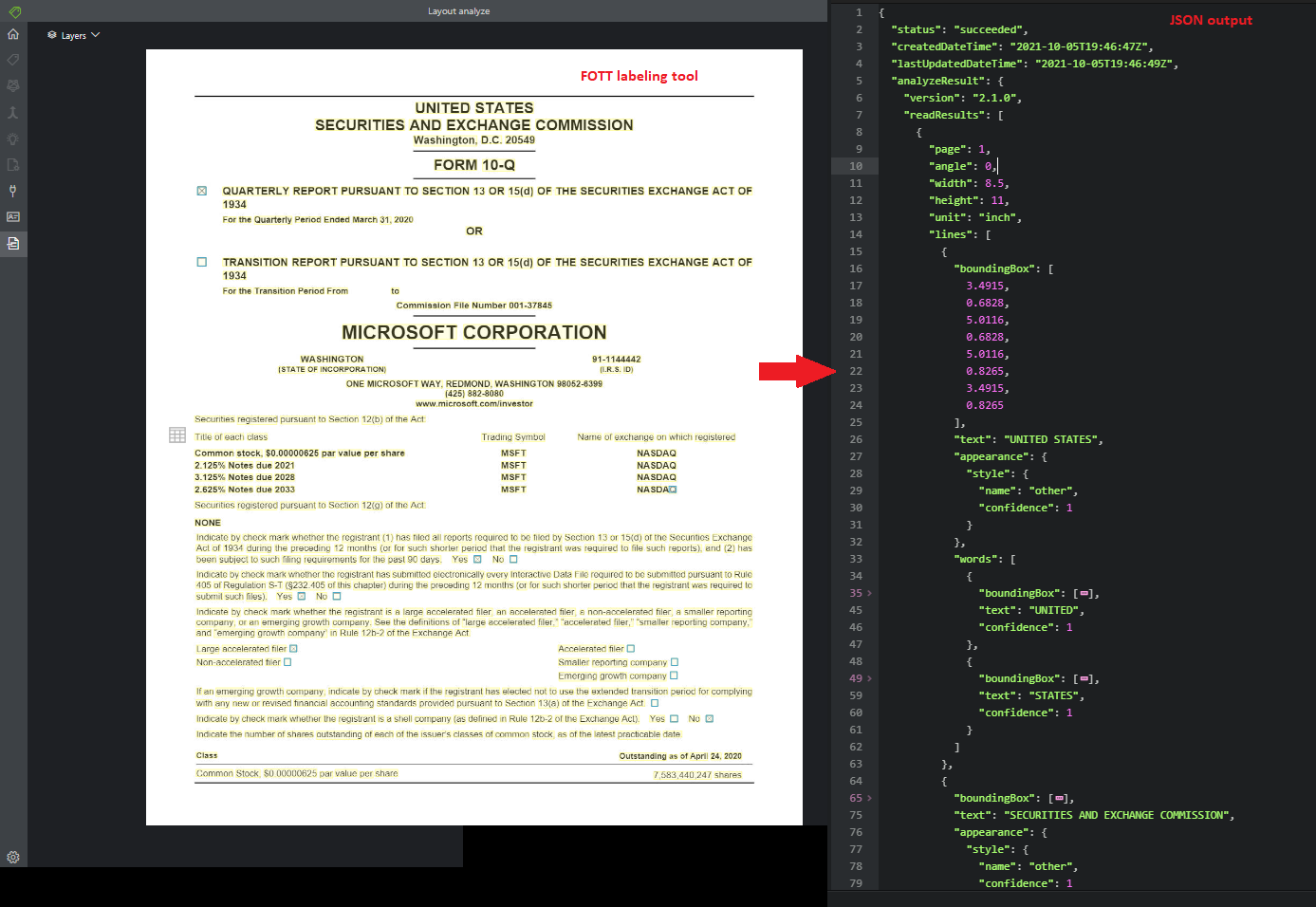
发票
发票模型可以分析和提取销售发票中的关键信息。 该 API 可分析各种格式的发票并提取客户姓名、帐单邮寄地址、截止日期和未付金额等关键信息。
使用示例标记工具处理的示例发票:
回执
- 收据模型可以分析和提取印刷体和手写体销售收据中的关键信息。
使用示例标记工具处理的示例收据:
身份文档
ID 文档模型分析和提取以下文档中的关键信息:
美国驱动程序许可证(50 个州和哥伦比亚特区)
国际护照的个人资料页(不包括签证和其他旅行证件)。 API 分析标识文档并提取
使用示例标记工具处理的示例美国驾照:
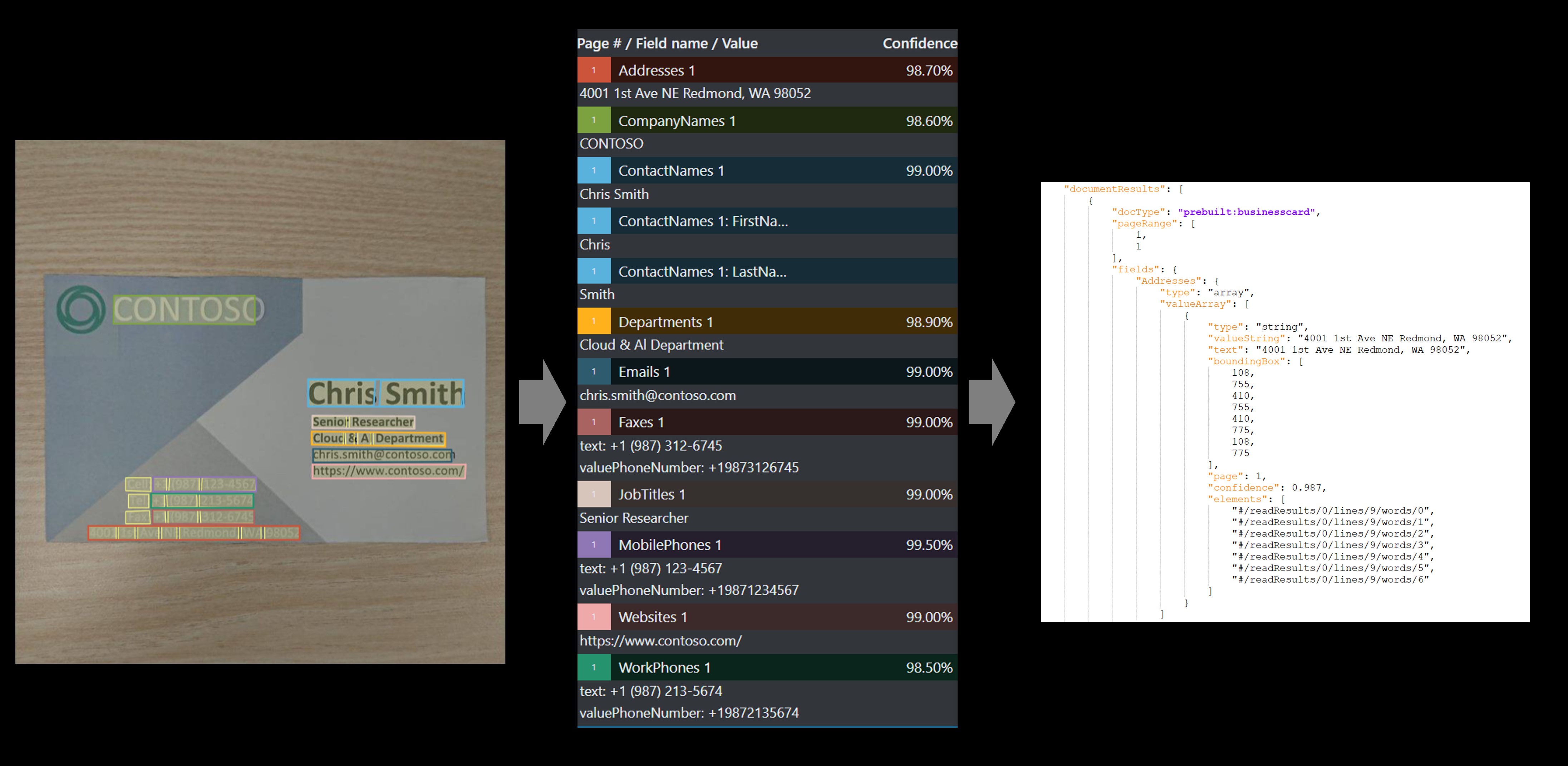
名片
名片模型可分析和提取名片图像中的关键信息。
使用示例标记工具处理的示例名片:
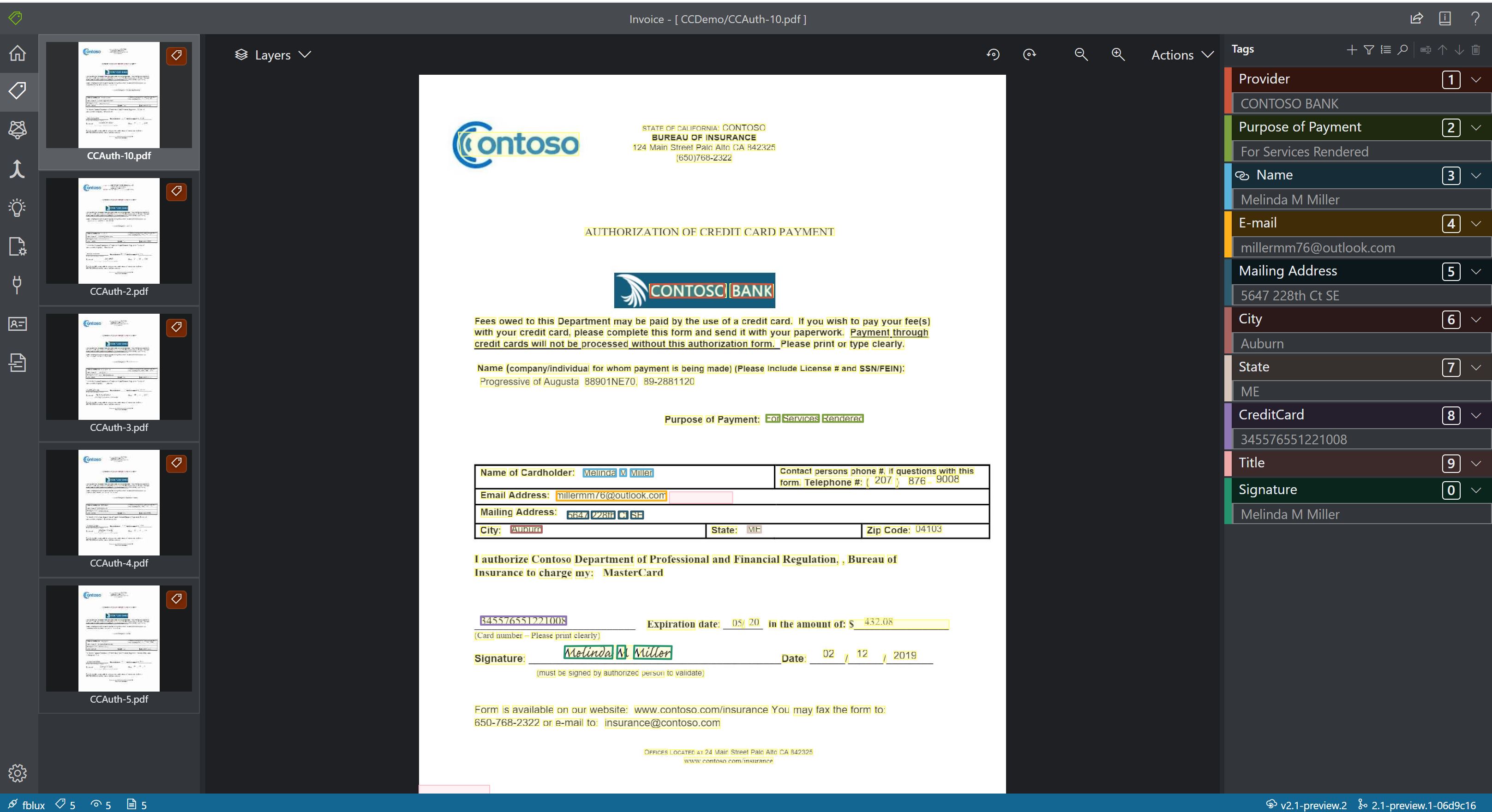
自定义
- 自定义模型会分析和提取特定于企业的表单和文档中的数据。 该 API 是已经过训练的机器学习程序,可识别不同内容中的表单字段并提取键值对和表数据。 你只需要五个相同类型的表单示例即可开始,自定义模型可以使用或不使用标记数据集进行训练。
使用示例标记工具处理的示例自定义模型:
组合自定义模型
组合模型的创建方式是采用自定义模型的集合并将其分配到基于你的表单类型构建的单个模型。 可以将多个自定义模型分配给使用单个模型 ID 调用的组合模型。 最多可将 100 个经过训练的自定义模型分配到单个组合模型。
使用示例标记工具编写的模型对话框窗口:
模型数据提取
| Model | 文本提取 | 语言检测 | 选定标记 | 表 | 段落 | 段落角色 | 键值对 | Fields |
|---|---|---|---|---|---|---|---|---|
| 布局 | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| 发票 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| 回执 | ✓ | ✓ | ✓ | |||||
| ID 文档 | ✓ | ✓ | ✓ | |||||
| 名片 | ✓ | ✓ | ✓ | |||||
| 自定义表单 | ✓ | ✓ | ✓ | ✓ | ✓ |
输入要求
支持的文件格式:
型号 PDF 图像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML读取 ✔ ✔ ✔ 布局 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview、2023-10-31-preview) 常规文档 ✔ ✔ 预生成 ✔ ✔ 自定义提取 ✔ ✔ 自定义分类 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview) 为获得最佳结果,请针对每个文档提供一张清晰的照片或高质量的扫描件。
对于 PDF 和 TIFF,最多可处理 2,000 页(对于免费层订阅,仅处理前两页)。
用于分析文档的文件大小对于付费 (S0) 层为 500 MB,对于免费 (F0) 层为
4MB。图像尺寸必须介于 50 像素 x 50 像素与 10,000 像素 x 10,000 像素之间。
如果 PDF 是密码锁定的文件,则必须先删除锁,然后才能提交它们。
对于 1024 x 768 像素的图像,要提取的文本的最小高度为 12 像素。 此尺寸对应于 150 点/英寸 (DPI) 的大约
8号字文本。对于自定义模型训练,自定义模板模型的训练数据最大页数为 500,自定义神经模型的训练数据最大页数为 50,000。
对于自定义提取模型训练,模板模型的训练数据总大小为 50 MB,神经网络模型的训练数据总大小为
1GB。对于自定义分类模型训练,训练数据总大小为
1GB,上限为 10,000 页。 对于 2024-07-31-preview 及更高版本,训练数据总大小为2GB,上限为 10,000 页。
注意
示例标记工具不支持 BMP 文件格式。 这是工具的一项限制,而不是文档智能服务的限制。
版本迁移
若要了解如何在应用程序中使用文档智能 v3.0,可按照我们的文档智能 v3.1 迁移指南操作
后续步骤
尝试使用 Document Intelligence Studio 来处理你自己的表单和文档。
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。
尝试使用文档智能示例标记工具来处理你自己的表单和文档。
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。