置信度分数通过衡量正确检测到提取结果的统计确定度来指示概率。 估计准确度的计算方式是运行训练数据的几种不同组合来预测标记的值。 本文介绍如何解释准确度和置信度评分,并提供有关使用这些评分改善准确度和置信度结果的最佳做法。
置信度分数
注意
- 字段级别的置信度包括自定义模型使用的 2024-11-30 (GA) API 版本中的单词置信度分数。
- 从自定义模型的 2024-11-30 (GA) API 版本开始,可提供表、表行和表单元格的置信度分数。
文档智能分析结果返回预测字词、键值对、选择标记、区域和签名的估计置信度。 目前,并非所有文档字段都返回置信度评分。
字段置信度表示预测正确的估计概率,值介于 0 和 1 之间。 例如,置信度值为 0.95 (95%) 表示预测 20 次可能有 19 次正确。 对于准确度至关重要的方案,可以使用置信度来确定是要自动接受预测,还是标记该预测以供人工评审。
Document Intelligence Studio
经分析的发票预生成发票模型
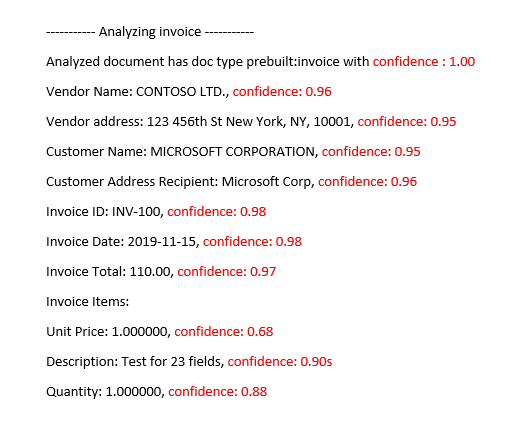
提高置信度分数
在完成分析操作后,查看 JSON 输出。 请检查 confidence 节点下每个键/值结果的 pageResults 值。 还应查看 readResults 节点中对应于文本读取操作的置信度评分。 读取结果的置信度不影响键/值提取结果的置信度,因此应检查此两者。 以下是一些提示:
如果
readResults对象的置信度评分较低,请改善输入文档的质量。如果
pageResults对象的置信度评分较低,请确保正在分析的文档属于同一类型。考虑将人工评审整合到工作流中。
使用每个字段具有不同值的表单。
对于自定义模型,请使用一组较大的训练文档。 较大的训练集将指导模型以更高的准确度识别字段。
自定义模型的准确性分数
build (v3.0 及更高版本) 或 train (v2.1) 自定义模型操作的输出包括估算的准确度评分。 此评分代表模型准确预测视觉上相似的文档中已标记值的能力。 测得的准确度是 0%(低)到 100%(高)范围内的百分比值。 最好将目标定为 80% 或更高的评分。 对于更敏感的案例,例如财务或医疗记录,建议设定接近 100% 的评分。 还可以添加人工审核阶段,以验证更关键的自动化工作流。
Document Intelligence Studio
经训练的自定义模型(发票)
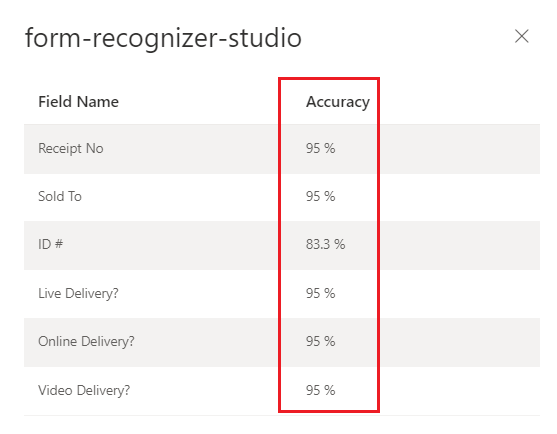
解释自定义模型的准确度与置信度分数
自定义模板模型在训练时会生成估计的准确度分数。 使用自定义模型分析的文档为提取的字段生成置信度评分。 解释自定义模型的置信度分数时,应考虑从模型返回的所有置信度分数。 让我们从所有置信度分数的列表开始。
文档类型置信度分数:文档类型置信度是分析的文档与训练数据集中的文档相似程度的指标。 文档类型置信度较低时,表示所分析文档存在模板或结构变化。 若要提高文档类型置信度,请标记具有该特定变化的文档并将其添加到训练数据集。 重新训练模型后,应更适合处理该类变化。
字段级别置信度:提取的每个标记字段都有关联的置信度分数。 此分数反映了模型对提取的值的位置的置信度。 在评估置信度时,还应查看基础提取置信度,以便为提取的结果生成综合置信度。 根据字段类型评估文本提取或选择标记的
OCR结果,以生成字段的复合置信度分数。单词置信度分数:文档中提取的每个单词都有关联的置信度分数。 分数表示听录的置信度。 页面数组包含一组单词,并且每个单词都有关联的范围和置信度分数。 自定义字段提取值的跨度将与提取的单词的跨度匹配。
选择标记置信度分数:页面数组中还包含一个选择标记数组。 每个选择标记都有一个置信度分数,表示选择标记和选择状态检测的置信度。 当标记字段具有选择标记时,与选择标记置信度相结合的自定义字段选择是整体置信度准确性的准确表示形式。
下表演示了如何解释准确度和置信度评分,以衡量自定义模型的性能。
| 精确度 | 置信度 | 结果 |
|---|---|---|
| 高 | 高 | • 在使用标记的键和文档格式时,该模型表现良好。 您有一个平衡的训练数据集。 |
| 高 | 低 | • 分析的文档看起来与训练数据集不同。• 模型将受益于再训练,其中至少包含五个标记的文档。 • 这些结果还可能表明训练数据集与分析的文档之间存在格式差异。
考虑添加一个新模型。 |
| 低 | 高 | • 此结果不太可能。• 对于准确度较低的分数,请将更多标记的数据添加或将视觉上不同的文档拆分到多个模型中。 |
| 低 | 低 | • 添加更多标记的数据。• 将视觉上不同的文档拆分为多个模型。 |
确保自定义模型的高模型准确性
文档视觉结构差异会影响模型的准确度。 如果分析的文档与训练中使用的文档不同,报告的准确度评分可能不一致。 请记住,文档集在人类看来可能相似,但对于 AI 模型而言并非如此。 下面列出了有关以最高准确度训练模型的最佳做法。 遵循这些指导原则应该可以在分析过程中生成准确度和置信度评分较高的模型,并减少要标记的供人工评审的文档数。
确保在训练数据集中包含文档的所有差异。 差异包括不同的格式,例如,数字格式与扫描的 PDF 格式。
如果你预期模型会分析这两种类型的 PDF 文档,请将每种类型的至少五个样本添加到训练数据集中。
将视觉上不同的文档类型分隔开,以训练不同的自定义模版模型和神经网络模型。
- 一般法则是,如果删除用户输入的所有值并且文档看起来相似,则需要将更多训练数据添加到现有模型。
- 如果文档不相似,请将训练数据拆分到不同的文件夹中,并为每个变体训练一个模型。 然后,可将不同的变体组合到单个模型中。
确保没有任何多余的标签。
确保签名和区域标记不包含周围的文本。
表、行和单元格置信度
下面是一些有助于解释表、行和单元格分数的常见问题:
单元格是否可以具有较高的置信度分数,而行的置信度分数较低?
不同层次的表格置信度(单元格、行和表)旨在捕捉该特定层次上预测的正确性。 属于存在其他可能遗漏情况的行的正确预测单元格将具有较高的单元格置信度,但该行的置信度应该较低。 类似地,表中的正确行如果与其他行存在挑战,则其行置信度较高,而表的整体置信度较低。
鉴于标识列数的变化,合并单元格如何影响置信度分数?
无论表的类型如何,合并单元格的期望值都应较低。 此外,缺少的单元格(因为与相邻单元格合并)应该具有 NULL 值,其置信度也较低。 这些值低多少取决于训练数据集,合并单元格和缺失单元格评分较低的总体趋势应该保持不变。
可选值的置信度分数是什么? 是否应预期具有“NULL”值的单元格具有较高的置信度分数,因为该值不存在?
如果你的训练数据集能体现单元格选项的变化性,它可以帮助模型了解值在训练集中出现的频率,从而在推理过程中预测可能出现的情况。 在计算预测的置信度或根本不进行预测 (NULL) 时,会使用此功能。 对于训练集中同样在大部分情况下为空的缺失值,预期会出现一个置信度较高的空字段。
如果缺少可选字段,置信度分数是否会改变? 置信度分数是否反映此更改?
当行中缺少值时,该单元格分配有一个 NULL 值和置信度。 此处的高置信度评分应该意味着模型预测(没有值)更有可能是正确的。 相反,低评分应该表明模型存在更多的不确定性(因此可能会出现错误,例如缺失值)。
提取跨页面拆分行的多页表时,对单元格和行置信度的期望是什么?
预计单元格的置信度会很高,而拆分行的置信度可能低于未拆分行的置信度。 训练数据集中拆分行的比例可能会影响置信度评分。 一般情况下,拆分行看起来与表中的其他行不同(因此,模型不太确定它是正确的)。
对于跨越多页的表格,若行数据在页面边界处完整断开与续接(即无行内数据被截断),是否可默认其置信度评分保持一致?
由于行在形状和内容方面看起来相似,因此无论它们位于文档中的哪个位置(或在哪个页中),它们各自的置信度评分都应该一致。
使用新置信度分数的最佳方式是什么?
查看从上到下方法开始的所有表置信度级别:首先检查表的整体置信度,然后向下钻取到行级别并查看各个行,最后查看单元格级别的置信度。 根据表的类型,需要注意几个事项:
对于固定表,单元格级别置信度已经捕获了大量有关事物正确性的信息。 这意味着,只需检查每个单元格并查看其置信度,可能就足以帮助确定预测的质量。 对于动态表,各个级别依次建立在前一层之上,因此自上而下的顺序更为重要。