本文介绍作为 AnalyzeDocument 响应的一部分返回的不同对象,以及如何在应用程序中使用文档分析 API 响应。
分析文档请求
文档智能 API 可分析图像、PDF 和其他文档文件,以提取和检测各种内容、布局、样式和语义元素。
Analyze 操作是一个异步 API。 提交文档会返回一个 Operation-Location 标头,其中包含用于轮询完成状态的 URL。 成功完成分析请求时,响应包含模型数据提取中所述的元素。
响应元素
内容元素是从文档中提取的基本文本元素。
布局元素将内容元素分组为结构单位。
样式元素描述内容元素的字体和语言。
语义元素为指定的内容元素赋予意义。
所有内容元素都按页面分组,页面由页码(索引从 1 开始)指定。 它们还按照阅读顺序进行排序,以语义连续的方式将元素排列在一起,即使它们跨越行或列边界。 当段落和其他布局元素之间的读取顺序不明确时,服务通常以从左到右、从上到下的顺序返回内容。
注意
目前,文档智能不支持跨页面边界的阅读顺序。 选择标记未定位在周围单词之间。
顶级内容属性包含按读取顺序排列的所有内容元素的串联形式。 所有元素通过此内容字符串中的跨度指定它们在阅读顺序中的位置。 某些元素的内容并不总是连续的。
分析响应
每个 API 的 Analyze 响应返回不同的对象。 API 响应包含组件模型中的元素(如果适用)。
| 响应内容 | 描述 | API |
|---|---|---|
| 页面 | 从输入文档的每一页面识别出的单词、行和范围。 | 读取、布局、通用文档、预生成和自定义模型 |
| 段落 | 识别为段落的内容。 | 读取、布局、通用文档、预生成和自定义模型 |
| styles | 识别的文本元素的属性。 | 读取、布局、通用文档、预生成和自定义模型 |
| 语言 | 已识别与提取文本每部分相关联的语言 | 读取 |
| 表格 | 从文档中识别和提取的表格内容。 表与由预先训练的布局模型识别的表相关。 标记为“表格”的内容会被提取为文档对象中的结构化字段。 | 布局、通用文档、发票和自定义模型 |
| 数据 | 从文档中识别和提取的图(图表、图像),提供了有助于理解复杂信息的视觉表示形式。 | 布局模型 |
| 部分 | 从文档中标识和提取的分层文档结构。 附有相应元素(段落、表格、图)的部分或子部分。 | 布局模型 |
| keyValuePairs | 由预先训练的模型识别的键值对。 键是文档中具有关联值的文本范围。 | 常规文档和发票模型 |
| 文档 | 识别的字段返回到文档列表中的 fields 字典中 |
预生成的模型、自定义模型。 |
有关每个 API 返回的对象的详细信息,请参阅模型数据提取。
元素属性
跨度
范围指定每个元素在整体读取顺序中的逻辑位置,每个范围指定一个字符偏移量和到顶级内容字符串属性的长度。 默认情况下,字符偏移量和长度以用户感知的字符(也称为 grapheme clusters 或文本元素)为单位返回。 若要适应使用不同字符单位的不同开发环境,用户可以指定 stringIndexIndex 查询参数以便以 Unicode 代码点 (Python 3) 或 UTF16 代码单位(Java、JavaScript、.NET)返回范围偏移量和长度。 有关详细信息,请参阅多语言/表情符号支持。
边界区域
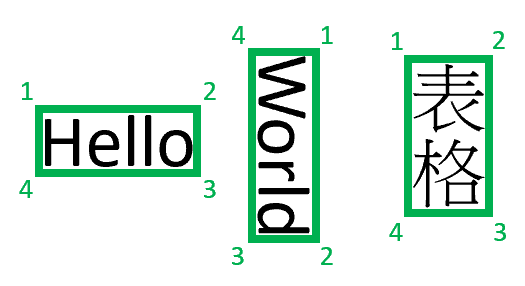
边界区域描述文件中每个元素的视觉上的位置。 当元素在视觉上不连续或跨页面(表)时,大多数元素的位置通过边界区域数组来描述。 每个区域指定页码(索引从 1 开始)和边界多边形。 边界多边形被描述为一系列点,根据元素的自然方位,从左侧顺时针排列。 对于四边形,绘图点是左上角、右上角、右下角和左下角。 每个点按 unit 属性指定的页面单位以 x、y 坐标表示。 通常,图像的度量单位是像素,而 PDF 使用英寸。
注意
目前,文档智能系统仅返回 4-vertex 四边形作为边界多边形。 将来的版本可能会返回不同的点数来描述更复杂的形状,例如曲线线或非矩形图像。 边界区域仅应用于已渲染的文件,如果文件未渲染,则不会返回边界区域。 目前不会呈现 docx/xlsx/pptx/html 格式的文件。
内容元素
单词
单词是由一系列字符组成的内容元素。 在文档智能中,词定义为一系列相邻字符,词之间用空格分隔。 对于不在单词之间使用空格分隔符的语言,每个字符将作为单独的单词返回,即使它不代表语义单词单位。

选择标记
选择标记是一种内容元素,它表示一个指示选择状态的视觉字形。 复选框是一种常见的选择标记形式。 但是,它们也可以通过单选按钮或图形化形式的带框单元格来表示。 选择标记的状态可以为选中或取消选中,并通过不同的视觉表示形式来指示状态。

布局元素
直线
行是由可视空格分隔的连续内容元素组成的有序序列;对于单词之间没有空格分隔符的语言,这些内容元素是直接相邻且按顺序排列的。 位于同一水平面(行)但被多个可视空格分隔的内容元素通常会分成多行。 虽然此功能有时会将语义上连续的内容拆分为单独的行,但它可以将文本内容表示为拆分成多个列或单元格。 垂直书写的线条将在垂直方向上被检测到。

段落
段落是构成逻辑单元的有序行序列。 通常,线条共享共同的对齐方式和线条之间的间距。 段落通常通过缩进、增加间距或者使用项目符号/编号来分隔。 内容只能分配到单个段落。 选择的段落也可与文档中的功能角色相关联。 目前支持的角色包括页眉、页脚、页码、标题、部分标题和脚注。

页
页面是一组内容,通常对应于一张纸的一面。 呈现的页面通过指定单位的宽度和高度来表征。 通常,图像使用像素,而 PDF 使用英寸。 angle 属性描述可以旋转的页面的整体文本角度(以度为单位)。
注意
对于 Excel 等电子表格,每个工作表映射到一个页面。 对于演示文稿(例如 PowerPoint),每张幻灯片映射到一个页面。 对于不呈现本机页面概念的文件格式(如 HTML 或 Word 文档),整个主内容被视为单页。
表
表将内容组织到网格布局中的一组单元格中。 行和列可以通过网格线、色带或更大的间距在视觉上分隔。 表单元格的位置由其行索引和列索引指定。 一个单元格可以跨越多行和多列。
根据其位置和样式,单元格可分类为常规内容、行标题、列标题、存根头或描述:
行标题单元格通常是一行中的第一个单元格,用于描述该行中的其他单元格。
列标题单元格通常是一列中的第一个单元格,用于描述该列中的其他单元格。
一行或一列可以包含多个标题单元格来描述分层内容。
存根头单元格通常指位于第一行和第一列位置的单元格。 它可为空,或描述同一行/列中标题单元格中的值。
描述单元格通常出现在表的最顶部或底部区域,描述整个表的内容。 但是,它有时可能会出现在表的中间,将表划分为多个部分。 通常,描述单元格跨越一行中的多个单元格。
表标题指定用于解释表的内容。 表还可以有关联的标题和一组脚注。 与描述单元格不同,标题通常位于网格布局之外。 表格内的脚注批注内容,通常用脚注符号标记在表格网格下方。
布局表不同于从表格数据中提取的文档字段。 布局表是从文档中的表格视觉内容中提取的,而不考虑内容的语义。 其实,一些布局表纯粹是为视觉布局而设计的,并不总是包含结构化数据。 从具有不同视觉布局的文档中提取结构化数据的方法,例如收据的逐项详细信息,通常需要大量的后处理。 必须将行或列标题映射到具有规范化字段名称的结构化字段。 根据文档类型,使用预生成的模型或训练自定义模型来提取此类结构化内容。 生成的信息作为文档字段公开。 这种已训练的模型还可以处理没有标题的表格数据和非表格形式的结构化数据,例如简历的工作经验部分。
注意
图形和表格的边界区域仅涵盖核心内容,不包括关联的标题和脚注。

插图
文档中的图形(图表、图像)在补充和增强文本内容方面发挥着至关重要的作用,可提供有助于理解复杂信息的视觉表示形式。 布局模型检测到的图形对象具有如下关键属性:boundingRegions(图形在文档页上的空间位置,包括页码和勾画图形边界的多边形坐标)、spans(详细说明与图形相关的文本范围,指定它们在文档文本中的偏移量和长度。这种联系有助于将图形与其相关文本上下文相关联)、elements(文档中与图形相关的,或描述图形的文本元素或段落的标识符)和 caption(如果有)。
在初始 操作期间指定了 output=figuresAnalyze 时,该服务会为可通过 /analyzeResults/{resultId}/figures/{figureId} 访问的所有检测到的图形生成裁剪的图像。
FigureId 包含在每个图形对象中,遵循一个未记录的约定 {pageNumber}.{figureIndex}(其中,对于每个页面,figureIndex 均重置为 1)。
{
"figures": [
{
"id": "{figureId}",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
表单字段(键值对)
表单域由字段标签(键)和值组成。 字段标签一般是描述字段含义的描述性文本字符串。 它通常出现在值的左侧,不过也可以出现在值的上方或下方。 字段值包含特定字段实例的内容值。 该值可以由单词、选择标记和其他内容元素组成。 对于未填写的表单域,它也可以为空。 一种特殊类型的表单域有一个选择标记值,字段标签位于其右侧。 文档字段是与常规表单域相似但不同的概念。 常规表单域中的字段标签(键)必须出现在文档中。 因此,通常无法捕获收据中的商家名称等信息。 文档字段已被标记,并且不提取键。 文档字段仅将提取的值映射至标签键。 有关详细信息,请参阅文档字段。

样式元素
样式
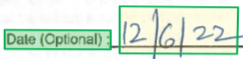
style 元素描述应用于文本内容的字体样式。 内容通过片段配置到全局内容属性中。 目前,唯一检测的字体样式是文本是否为手写。 随着其他样式的添加,文本可以通过多个不冲突的样式对象描述。 为简洁起见,所有共享特定字体样式(具有相同置信度)的文本都通过单个样式对象进行描述。
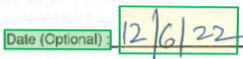
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
语言
language 元素描述通过范围指定到全局内容属性中的内容的检测语言。 检测到的语言是通过 BCP-47 语言标记指定的,指示主要语言和可选的脚本和区域信息。 例如,英文和繁体中文分别被识别为“en”和“zh-Hant”。 英国英语的地区拼写差异可能导致文本被检测为 en-GB。 语言元素不包含没有主要语言(例如数字)的文本。
语义元素
注意
提到的语义元素适用于文档智能预生成模型。 自定义模型可能会返回不同的数据表示形式。 例如,自定义模型返回的日期和时间的表示模式可能与标准 ISO 8601 格式不同。
文档
文档是语义上完整的单元。 一个文件可以包含多个文档,例如 PDF 文件中的多个税务表单,或单个页面中的多个收据。 文件中各文档的顺序不会对其传达的信息产生根本影响。
注意
目前,文档智能不支持单个页面上的多个文档。
文档类型描述共享一组公共语义字段的文档,由结构化架构表示,独立于其视觉模板或布局。 例如,所有“收据”类型的文档都可以包含商家名称、交易日期和交易总额,不过餐馆和旅馆的收据通常在外观上有所不同。
文档元素包括在检测到的文档类型的语义架构中指定的字段中,识别出的字段列表:
可以提取或推断文档字段。 提取的字段由提取的内容和可选的规范化值(如果可解释)表示。
推理字段没有 content 属性,仅由其值表示。
数组字段不包含内容属性。 内容可以从数组元素的内容中串联起来。
对象字段包含一个 content 属性,该属性指定表示对象(可以是提取的子字段的超集)的完整内容。
文档类型的语义架构通过它可以包含的字段描述。 每个字段架构由其规范名称和值类型指定。 字段值类型包括基本(例如字符串)、复合(例如地址)和结构化(例如数组、对象)类型。 字段值类型还指定执行的语义规范化,以将检测到的内容转换为规范化表示形式。 规范化可能与区域设置相关。
基本类型
| 字段值类型 | 描述 | 规范化表示形式 | 示例(字段内容 -> 值) |
|---|---|---|---|
| 字符串 | 纯文本 | 与内容相同 | MerchantName:"Contoso" → "Contoso" |
| 日期 | 日期 | ISO 8601 - YYY-MM-DD | InvoiceDate:"5/7/2022" → "2022-05-07" |
| 时间 | 时间 | ISO 8601 - hh:mm:ss | TransactionTime:"9:45 PM" → "21:45:00" |
| 电话号码 | 电话号码 | E.164 - +{CountryCode}{SubscriberNumber} | 工作电话:"(800) 555-7676" → "+1 800 555 7676" |
| 国家/地区 | 国家/地区 | ISO 3166-1 alpha-3 | CountryRegion:"United States" → "USA" |
| 选择标记 | 已选择 | 「有符号 (signed)」或「无符号 (unsigned)」 | AcceptEula:☑ → “已选择” |
| 签名 | 已签名 | 与内容相同 | LendeeSignature:{signature} → “已签署” |
| 数字 | 浮点数 | 浮点数 | Quantity:"1.20" → 1.2 |
| 整数 | 整数 | 64 位有符号整数 | Count:"123" → 123 |
| 布尔 | 布尔值 | 真/假 | IsStatutoryEmployee:☑ → true |
复合类型
货币:带有可选货币单位的货币金额。 一个值,例如:
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }地址:分析的地址。 例如:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
结构化类型
数组:相同类型的字段列表
"Items": { "type": "array", "valueArray": [ ] }对象:可能具有不同类型的子字段的命名列表
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }