重要
从文档智能v4.0开始,名片模型 (prebuilt-businessCard) 已被弃用。 若要从名片格式中提取数据,请使用以下内容:
| 功能 | 版本 | 模型 ID |
|---|---|---|
| 名片模型 | • v3.1:2023-07-31 (GA) • v3.0:2022-08-31 (GA) • v2.1 (GA) |
prebuilt-businessCard |
[!INCLUDE [适用于 v2.1]../(includes/applies-to-v21.md)]
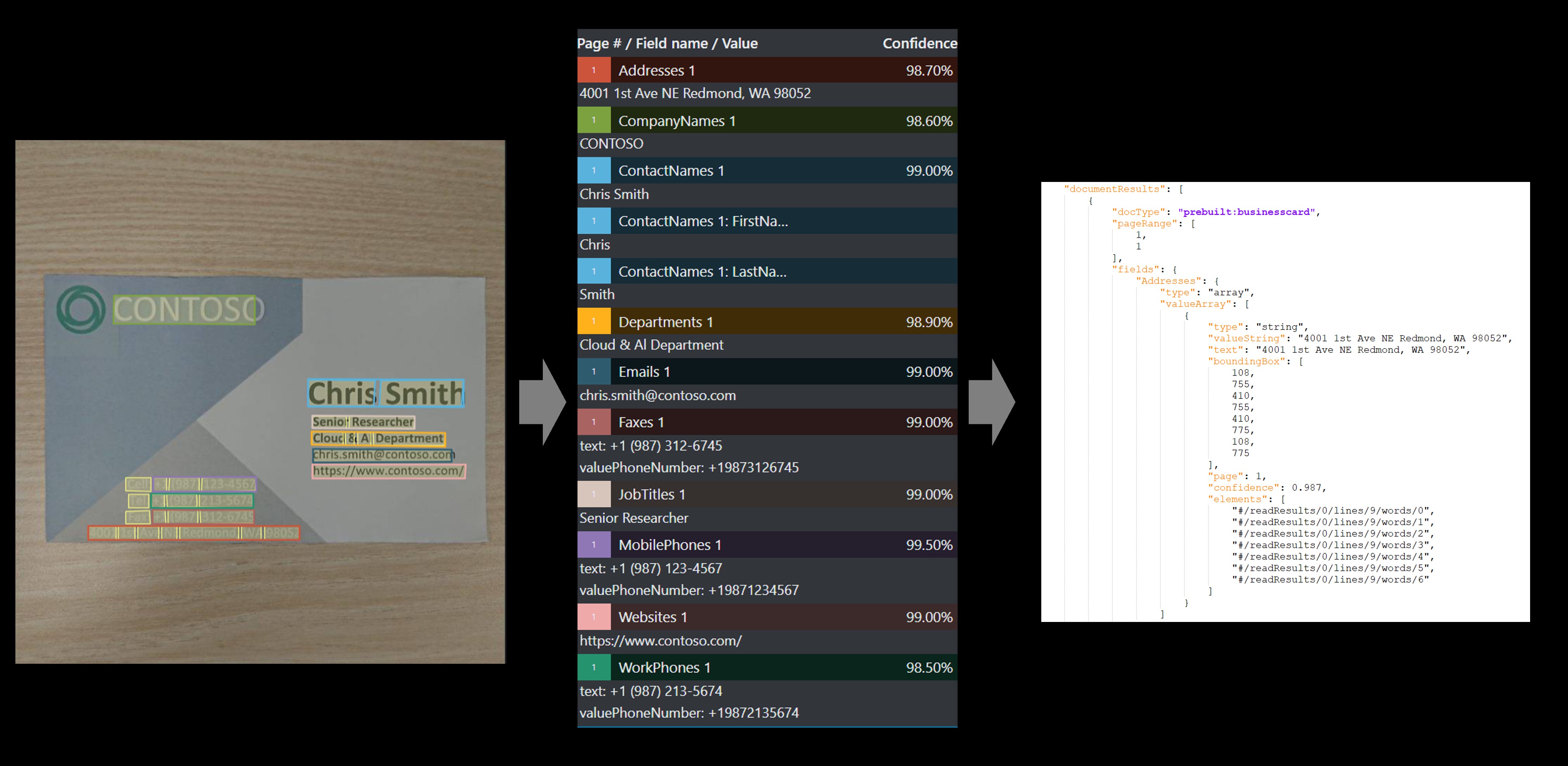
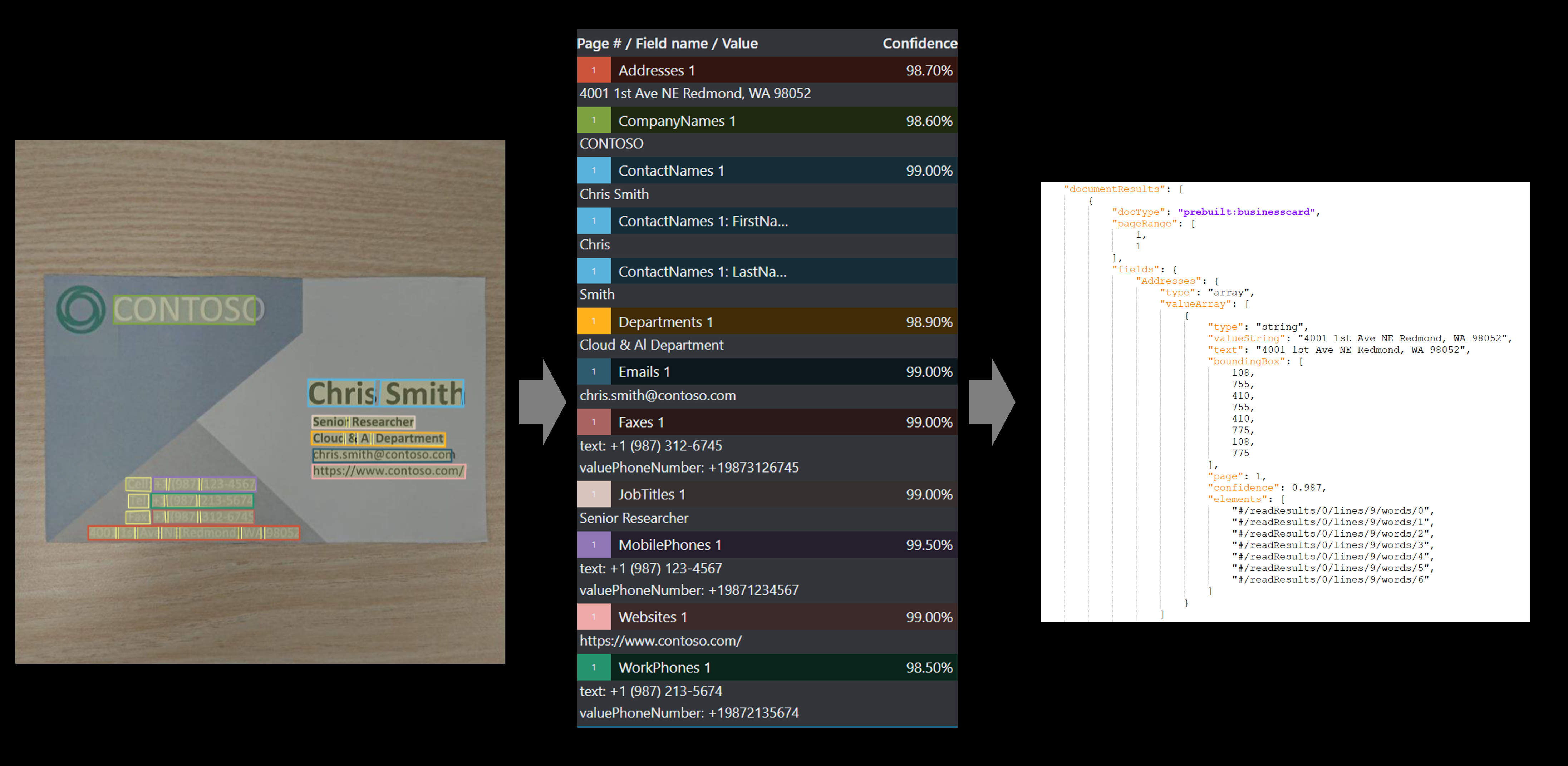
文档智能名片模型将强大的光学字符识别 (OCR) 功能与深度学习模型相结合,可从名片图像中分析和提取数据。 该 API 可分析打印的名片,提取名字、姓氏、公司名称、电子邮件地址和电话号码等关键信息,并返回结构化的 JSON 数据表示形式。
名片数据提取
名片是代表企业或专业人士的好方法。 在名片中找到的公司徽标、字体和背景图像有助于推广公司品牌,并将其与其他品牌区分开来。 应用基于 OCR 和机器学习的技术来自动扫描名片是常见的图像处理方案。 销售和营销团队使用的企业系统通常将名片数据提取功能集成到其中,以便为用户提供方便。
使用Document Intelligence Studio处理的示例名片

使用文档智能示例标记工具处理的示例业务:
开发选项
文档智能 v3.1:2023-07-31 (GA) 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| 名片模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-businessCard |
文档智能 v3.0:2022-08-31 (GA) 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| 名片模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-businessCard |
文档智能 v2.1 (GA) 支持以下工具、应用程序和库:
| 功能 | 资源 |
|---|---|
| 名片模型 | • 文档智能标记工具 • REST API • 客户端库 SDK • 文档智能 Docker 容器 |
试用名片数据提取功能
查看如何从名片中提取数据,包括姓名、职务、地址、电子邮件和公司名称。 需要以下资源:
文档智能工作室
注意
文件智能工作室可以在 v3.1 和 v3.0 API 中使用。
在文档智能工作室主页上,选择“名片”。
可以分析示例名片或上传自己的文件。
选择“运行分析”按钮,并根据需要配置“分析选项”:

文档智能示例标记工具
导航到“文档智能示例工具”。
在示例工具主页上,选择“使用预构建模型获取数据”图块。
从下拉菜单中选择要分析的“表单类型”。
从以下选项中选择要分析的文件的 URL:
- 发票示例文档。
- 身份证示例文档。
- 收据示例图像。
- 名片示例图像。
从“源”字段的下拉菜单中选择“URL”,粘贴所选 URL,然后选择“提取”按钮。
在“文档智能服务终结点”字段中,粘贴使用文档智能订阅获得的终结点。
在“密钥”字段中,粘贴从文档智能资源中获取的密钥。
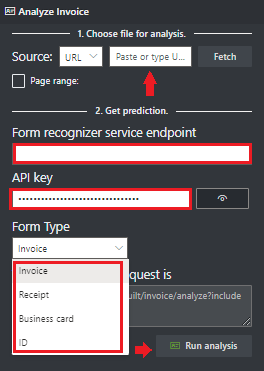
选择“运行分析”。 文档智能示例标记工具可调用分析预生成 API 并分析文档。
查看结果 - 查看提取的键值对、提取的明细项目、已提取的高亮文本和检测到的表格。
{kind=link}
注意
示例标记工具不支持 BMP 文件格式。 这是工具的一项限制,而不是文档智能服务的限制。
输入要求
支持以下文件格式。
| 型号 | 图片: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Office: Word(DOCX)、Excel(XLSX)、PowerPoint(PPTX)、HTML |
|
|---|---|---|---|
| 读取 | ✔ | ✔ | ✔ |
| 版式 | ✔ | ✔ | ✔ |
| 常规文档 | ✔ | ✔ | |
| 预制 | ✔ | ✔ | |
| 自定义提取 | ✔ | ✔ | |
| 自定义分类 | ✔ | ✔ | ✔ |
- 照片和扫描:为获得最佳结果,请为每个文档提供一张清晰的照片或高质量的扫描。
- PDF 和 TIFF:对于 PDF 和 TIFF,最多可以处理 2,000 页。 (使用免费层订阅时,只处理前两个页面。
- 文件大小:用于分析文档的文件大小是付费层 (S0) 层的 500 MB,免费层为 4 MB(F0) 层。
- 图像尺寸:尺寸必须介于 50 像素 x 50 像素和 10,000 像素 x 10,000 像素之间。
- 密码锁:如果 PDF 是密码锁定的,则必须在提交之前删除该锁。
- 文本高度:要提取的文本的最小高度是 1024 x 768 像素图像的 12 像素。 此尺寸对应于 8 点大约文本,即每英寸 150 点。
- 自定义模型训练:自定义模板模型的最大训练页数为 500,自定义神经模型为 50,000。
- 自定义提取模型训练:对于模板模型,训练数据的总大小为 50 MB,神经网络模型为 1 GB。
- 自定义分类模型训练:训练数据的总大小为 1 GB,最大为 10,000 页。 对于 2024-11-30(GA),训练数据的总大小为 2 GB,最大为 10,000 页。
- Office 文件类型(DOCX、XLSX、PPTX):最大字符串长度限制为 800 万个字符。
- 支持的文件格式:JPEG、PNG、PDF 和 TIFF
- 对于 PDF 和 TIFF,最多处理 2000 页。 对于免费套餐订阅者,仅处理前两页。
- 文件大小必须小于 50 MB,且尺寸介于 50 x 50 和 10,000 x 10,000 像素之间。
提取的字段
| 名称 | 类型 | 说明 | 文本 |
|---|---|---|---|
| 联系人名称 | 对象数组 | 从名片提取的联系人姓名 | [{ “FirstName”: “John”, “LastName”: “Doe” }] |
| 名字 | 字符串 | 联系人的名字 | "John" |
| 姓 | 字符串 | 联系人的姓氏 | Doe |
| 公司名称 | 字符串数组 | 从名片提取的公司名称 | [“Contoso”] |
| 部门 | 字符串数组 | 联系人的部门或组织 | [“R&D”] |
| 职位名称 | 字符串数组 | 列出的联系人职称 | 软件工程师 |
| 电子邮件 | 字符串数组 | 从名片提取的联系人电子邮件 | [“”johndoe@contoso.com] |
| 网站 | 字符串数组 | 从名片提取的网站地址 | [“https://www.contoso.com"] |
| 地址 | 字符串数组 | 从名片提取的地址 | [“123 Main Street, Redmond, Washington 98052”] |
| 手机 | 电话号码数组 | 从名片提取的移动电话号码 | [“+19876543210”] |
| 传真 | 电话号码数组 | 从名片提取的传真电话号码 | [“+19876543211”] |
| WorkPhones | 电话号码数组 | 从名片提取的工作电话号码 | [“+19876543231”] |
| OtherPhones | 电话号码数组 | 从名片提取的其他电话号码 | [“+19876543233”] |
支持的区域设置
预生成名片 v2.1 支持以下区域设置:
- zh-cn
- en-au
- en-ca
- en-gb
- en-in
迁移指南和 REST API v3.1
- 请参阅我们的文档智能 v3.1 迁移指南,了解如何在应用程序和工作流中使用 v3.0。
后续步骤
尝试使用 Document Intelligence Studio 来处理你自己的表单和文档
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。
尝试使用文档智能示例标记工具来处理你自己的表单和文档
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。