此内容适用于:![]() v4.0 (GA) | 以前的版本:
v4.0 (GA) | 以前的版本:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Azure 文档智能布局模型是基于机器学习的高级文档分析 API。 该模型在文档智能云中可用。 可以使用它以各种格式获取文档,并返回文档的结构化数据表示形式。 该模型将增强版强大的 光学字符识别(OCR) 功能与深度学习模型相结合,以提取文本、表格、选择标记和文档结构。
文档结构布局分析
文档结构布局分析是分析文档以提取感兴趣的区域及其相互关系的过程。 目标是从页面中提取文本和结构元素,以构建更好的语义理解模型。 文档布局中有两种类型的角色:
- 几何角色:文本、表、图形和选择标记是几何角色的示例。
- 逻辑角色:标题、标头和页脚是文本逻辑角色的示例。
下图显示了示例页图像中的典型组件。

开发选项
文档智能 v4.0:2024-11-30(GA)支持以下工具、应用程序和库。
| 功能 | 资源 | 模型 ID |
|---|---|---|
| 布局模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
支持的语言
有关支持语言的完整列表,请参阅 语言支持:文档分析模型。
支持的文件类型
文档智能 v4.0:2024-11-30 (GA) 布局模型支持以下文件格式:
| 型号 | 图片: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Office: Word(DOCX)、Excel(XLS)、PowerPoint(PPTX)、HTML |
|
|---|---|---|---|
| 版式 | ✔ | ✔ | ✔ |
输入要求
- 照片和扫描:为获得最佳结果,请为每个文档提供一张清晰的照片或高质量的扫描。
- PDF 和 TIFF:对于 PDF 和 TIFF,最多可以处理 2,000 页。 (使用免费层订阅时,只处理前两个页面。
- 密码锁:如果 PDF 是密码锁定的,则必须在提交之前删除该锁。
- 文件大小:用于分析文档的文件大小是付费层 (S0) 层的 500 MB,免费层为 4 MB(F0) 层。
- 图像尺寸:图像尺寸必须介于 50 像素 x 50 像素和 10,000 像素 x 10,000 像素之间。
- 文本高度:要提取的文本的最小高度为 1024 x 768 像素图像的 12 像素。 此尺寸对应于 8 点大约文本,即每英寸 150 点。
- 自定义模型训练:自定义模板模型的最大训练页数为 500,自定义神经模型为 50,000。
- 自定义提取模型训练:模板模型的总训练大小为 50 MB,神经网络模型为 1 GB。
- 自定义分类模型训练:训练数据的总大小为 1 GB,最大为 10,000 页。 对于 2024-11-30(GA),训练数据的总大小为 2 GB,最大为 10,000 页。
- Office 文件类型(DOCX、XLSX、PPTX):最大字符串长度限制为 800 万个字符。
有关模型使用、配额和服务限制的详细信息,请参阅 服务限制。
布局模型入门
了解如何使用文档智能从文档中提取数据,包括文本、表头、选择标记和结构信息。 需要以下资源:
检索密钥和终结点后,使用以下开发选项生成和部署文档智能应用程序。
数据提取
布局模型从文档中提取结构元素。 本文的其余部分介绍了以下结构元素,以及有关如何从文档输入中提取它们的指南:
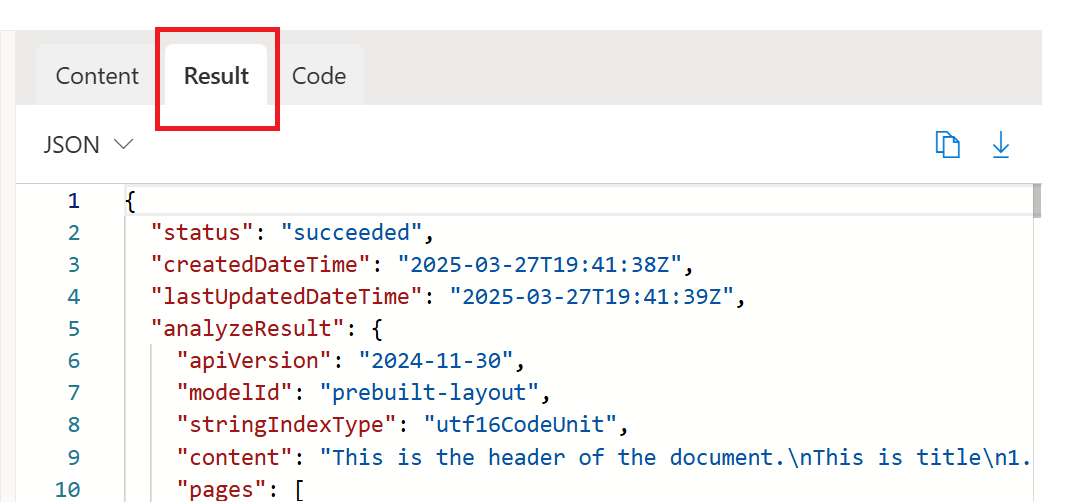
在 Document Intelligence Studio 中运行示例布局文档分析。 然后转到“结果”选项卡并访问完整的 JSON 输出。
页面
集合 pages 是文档内页面的列表。 每个页面在文档中按顺序表示,并包括方向角度,指示页面是否旋转,以及宽度和高度(以像素为单位)。 模型输出中的页面单位的计算如下表所示。
| 文件格式 | 计算页单位 | 总页数 |
|---|---|---|
| 图片(JPEG/JPG、PNG、BMP、HEIF) | 每个图像 = 1 页单位。 | 图像总数 |
| PDF 中的每个页面 = 1 页单位。 | PDF 中的总页数 | |
| TIFF | TIFF 中的每个图像 = 1 页单元。 | TIFF 中的图像总数 |
| Word(DOCX) | 最多 3,000 个字符 = 1 页单位。 不支持嵌入或链接的图像。 | 每页最多 3,000 个字符的总页数 |
| Excel (XLSX) | 每个工作表 = 1 页单位。 不支持嵌入或链接的图像。 | 工作表总数 |
| PowerPoint (PPTX) | 每张幻灯片 = 1 页单位。 不支持嵌入或链接的图像。 | 幻灯片总数 |
| HTML | 最多 3,000 个字符 = 1 页单位。 不支持嵌入或链接的图像。 | 每页最多 3,000 个字符的总页数 |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
提取所选页面
对于大型多页文档,请使用 pages 查询参数指示用于文本提取的特定页码或页范围。
段落
在 paragraphs 集合中识别的所有文本块将被布局模型提取为 analyzeResults 下的顶级对象。 此集合中的每个条目代表一个文本块,并包括提取的文本以及 content 边界 polygon 坐标。
spans 信息指向包含文档全文的顶级 content 属性中的文本片段。
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
段落角色
基于机器学习的新页面对象检测提取了诸如标题、节标题、页眉、页脚等逻辑角色。 文档智能布局模型使用模型预测的专用角色或类型分配集合中的 paragraphs 某些文本块。
对于非结构化文档,最好使用段落角色来帮助了解所提取内容的布局,从而进行更丰富的语义分析。 支持以下段落角色。
| 预测角色 | Description | 支持的文件类型 |
|---|---|---|
title |
页面上的主标题 | PDF、Image、DOCX、PPTX、XLSX、HTML |
sectionHeading |
页面上的一个或多个子标题 | PDF、Image、DOCX、XLSX、HTML |
footnote |
页面底部附近的文本 | PDF、图像 |
pageHeader |
页面顶部边缘附近的文本 | PDF、Image、DOCX |
pageFooter |
页面底部边缘附近的文本 | PDF、Image、DOCX、PPTX、HTML |
pageNumber |
页码 | PDF、图像 |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
文本、行、字词
文档智能中的文档布局模型将打印和手写样式的文本分别提取为lines和words。 该 styles 集合包括行的任何手写样式(如果检测到)以及指向关联文本的跨度。 此功能适用于受支持的手写语言。
对于 Microsoft Word、Excel、PowerPoint 和 HTML,文档智能 v4.0 2024-11-30 (GA) 布局模型按原样提取所有嵌入文本。 文本被提取为字词和段落。 不支持嵌入图像。
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
文本行的手写风格
响应包括每个文本行是否采用手写样式以及置信度分数。 有关详细信息,请参阅 手写语言支持。 以下示例演示了一个示例 JSON 片段。
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
如果启用 字体/样式加载项功能,则还会获取作为对象的一部分的 styles 字体/样式结果。
选择标记
布局模型还会从文档中提取选择标记。 提取的选定标记显示在每个页面的 pages 集合中。 它们包括边界polygon、confidence和选择项state (selected/unselected)。 "文本表示形式(即:selected:和:unselected)也被包含为起始索引(offset),并且length引用了包含文档全文的顶级content属性。"
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
表
提取表是处理包含通常格式化为表的大量数据的文档的关键要求。 布局模型提取 JSON 输出部分中的表 pageResults 。 提取的表信息包括列数和行数、行范围和列范围。
每个单元格及其边界多边形都会输出,并包含该区域是否被识别为 columnHeader 的信息。 该模型支持提取已旋转的表格。 每个表格单元格都包含行和列的索引以及界限多边形坐标。 对于单元格文本,模型输出 span 包含起始索引的信息(offset)。 该模型还在包含文档全文的顶级内容中输出length。
使用“文档智能”提取功能时,需要考虑以下几个因素:
- 要提取的数据是否以表的形式呈现,该表的结构是否有意义?
- 如果数据不采用表格式,数据是否适合放入二维网格?
- 表格是否跨越多个页面? 如果是这样,为了避免必须标记所有页面,请将 PDF 拆分为页面,然后再将其发送到文档智能。 分析后,将页面后处理为单个表。
- 如果创建自定义模型,请参阅 表格字段 。 对于每个列,动态表包含可变数量的行。 对于每个列,固定表包含恒定数量的行。
注意
如果输入文件为 XLSX,则不支持表分析。 对于 2024-11-30(GA),图表和表的边界区域仅涵盖核心内容,并排除关联的标题和脚注。
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
将响应输出为 Markdown 格式
布局 API 可以输出 Markdown 格式的提取文本。 使用 outputContentFormat=markdown 在 Markdown 中指定输出格式。 Markdown 内容作为 content 部分输出。
注意
对于 v4.0 2024-11-30(GA),表的表示形式更改为 HTML 表,以便呈现合并单元格和多行标头等项。 另一个相关的更改是使用 Unicode 复选框字符☒和☐选择标记而不是 :selected: 和 :unselected:。 此更新意味着,选择标记字段的内容包含 :selected:,即使它们的范围引用了顶级范围中的 Unicode 字符。 有关 Markdown 元素的完整定义,请参阅 Markdown 输出格式。
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
图表
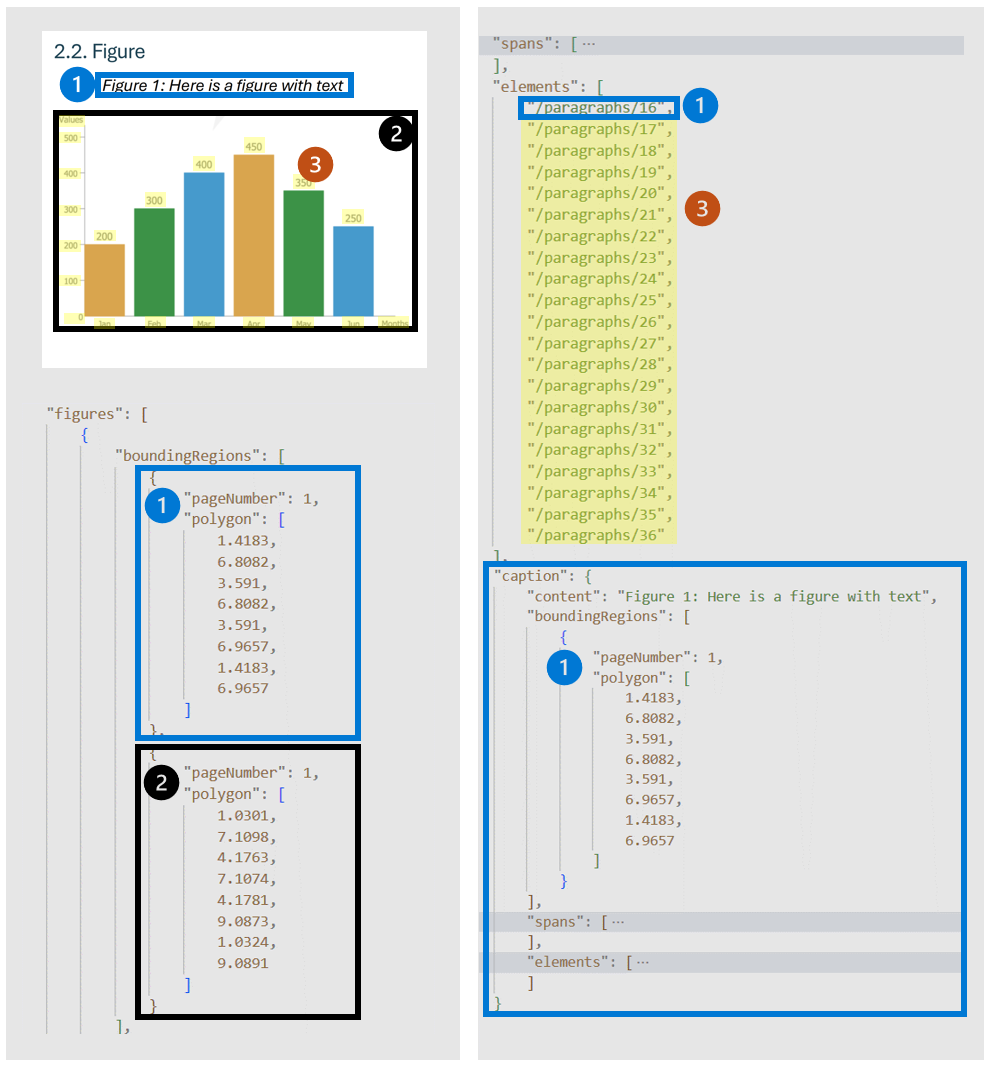
文档中的图表(图表和图像)在补充和增强文本内容方面发挥了重要作用。 它们提供视觉表示形式,有助于理解复杂信息。
figures布局模型检测到的对象具有键属性,例如:
-
boundingRegions:文档页上图形的空间位置,包括显示图形边界的页码和多边形坐标。 -
spans:与指定文档文本中的偏移量和长度的图形相关的文本跨度。 此连接有助于将图形与其相关的文本上下文相关联。 -
elements:与图形相关的文档内文本元素或段落的标识符。 -
caption:如果有说明。
在初始分析操作期间指定了output=figures时,该服务会生成裁剪的图像,供通过/analyeResults/{resultId}/figures/{figureId}访问的所有检测到的图像使用。
FigureId 值是每个图对象中包含的 ID,遵循一个未记录的惯例 {pageNumber}.{figureIndex},figureIndex 每页重置为1。
对于 v4.0 2024-11-30(GA),图表和表的边界区域仅涵盖核心内容,并排除关联的标题和脚注。
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
章节
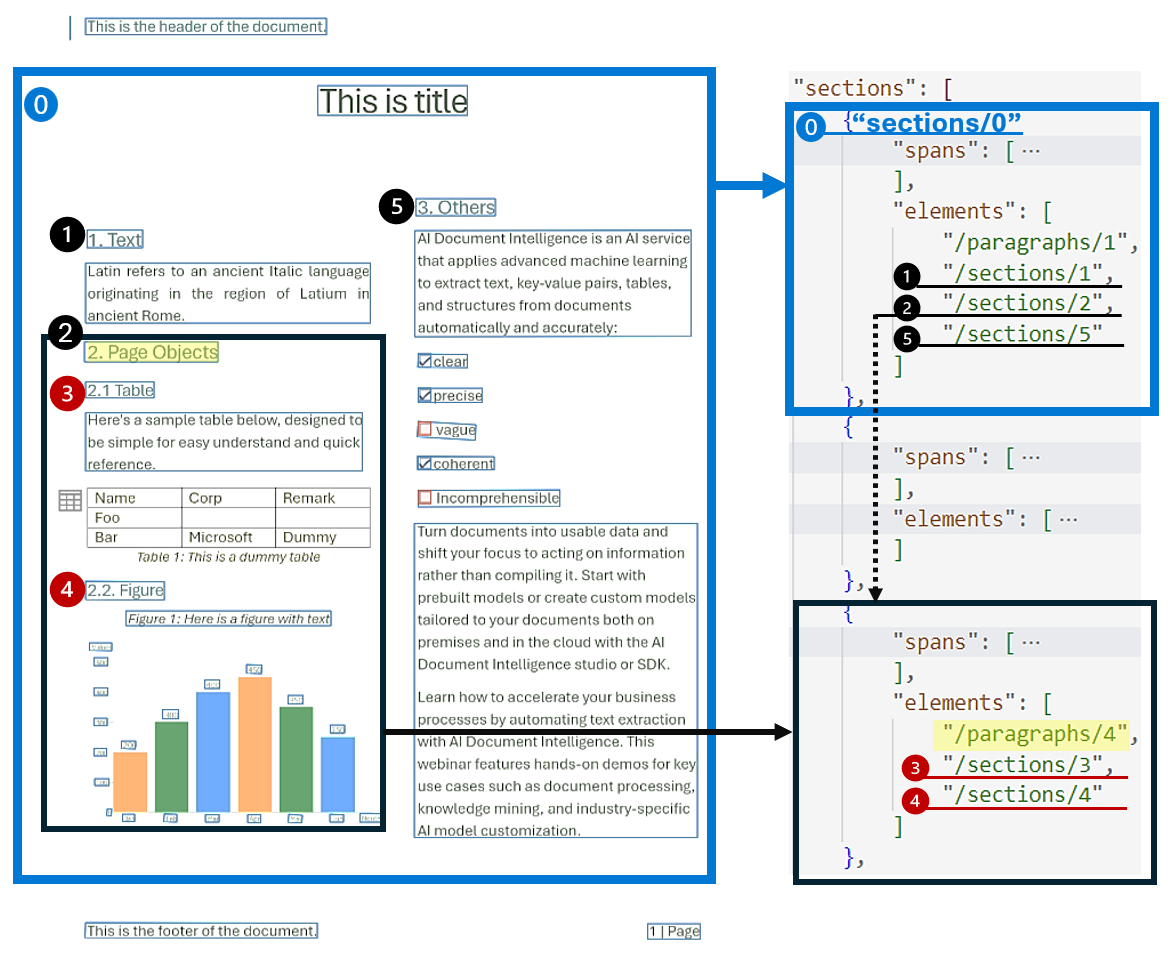
分层文档结构分析对于组织、理解和处理大量文档至关重要。 此方法对于对长文档进行语义分段以增强理解、促进导航和改进信息检索至关重要。 文档生成AI中的RAG(检索增强生成)的出现突显了分析分层文档结构的重要性。
布局模型支持在输出中定义节和子节,明确标识每个节内的节和对象的关系。 分层结构在每个节中由elements维护。 可以使用 输出响应为 Markdown 格式 以便于轻松获取 Markdown 中的节和子节。
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
此内容适用于:checkmarkv2.1blue-checkmarkv4.0 (GA)
文档智能布局模型是一个高级文档分析 API。 该模型基于机器学习,可在文档智能云中使用。 可以使用它以各种格式获取文档,并返回文档的结构化数据表示形式。 它将增强版强大的 OCR 功能与深度学习模型相结合。 可以使用它提取文本、表格、选择标记和文档结构。
文档布局分析
文档结构布局分析是分析文档以提取感兴趣的区域及其相互关系的过程。 目标是从页面中提取文本和结构元素,以构建更好的语义理解模型。 文档布局中有两种类型的角色:
- 几何角色:文本、表、图形和选择标记是几何角色的示例。
- 逻辑角色:标题、标头和页脚是文本逻辑角色的示例。
下图显示了示例页图像中的典型组件。
支持的语言和区域设置
有关支持语言的完整列表,请参阅 语言支持:文档分析模型。
Document Intelligence v2.1 支持以下工具、应用程序和库。
| 功能 | 资源 |
|---|---|
| 布局模型 | • 文档智能标记工具 • REST API • 客户端库 SDK • 文档智能 Docker 容器 |
输入指南
支持的文件格式:
| 型号 | 图片: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Office: Word(DOCX)、Excel(XLSX)、PowerPoint(PPTX)、HTML |
|
|---|---|---|---|
| 读取 | ✔ | ✔ | ✔ |
| 版式 | ✔ | ✔ | |
| 常规文档 | ✔ | ✔ | |
| 预制 | ✔ | ✔ | |
| 自定义提取 | ✔ | ✔ | |
| 自定义分类 | ✔ | ✔ | ✔ |
- 照片和扫描:为获得最佳结果,请为每个文档提供一张清晰的照片或高质量的扫描。
- PDF 和 TIFF:对于 PDF 和 TIFF,最多可以使用免费层订阅处理 2,000 页。 仅处理前两页。
- 文件大小:用于分析文档的文件大小是付费层 (S0) 层的 500 MB,免费层为 4 MB(F0) 层。
- 图像尺寸:图像尺寸必须介于 50 像素 x 50 像素和 10,000 像素 x 10,000 像素之间。
- 密码锁:如果 PDF 是密码锁定的,则必须在提交之前删除该锁。
- 文本高度:要提取的文本的最小高度为 1024 x 768 像素图像的 12 像素。 此尺寸对应于 8 点大约文本,即每英寸 150 点。
- 自定义模型训练:自定义模板模型的最大训练页数为 500,自定义神经模型为 50,000。
- 自定义提取模型训练:模板模型的总训练大小为 50 MB,神经网络模型为 1 GB。
- 自定义分类模型训练:训练数据的总大小为 1 GB,最大为 10,000 页。 对于 2024-11-30(GA),训练数据的总大小为 2 GB,最大为 10,000 页。
- Office 文件类型(DOCX、XLSX、PPTX):最大字符串长度限制为 800 万个字符。
输入指南
- 支持的文件格式:JPEG、PNG、PDF 和 TIFF。
- 支持的页数:对于 PDF 和 TIFF,最多处理 2,000 页。 对于免费套餐订阅者,仅处理前两页。
- 支持的文件大小:文件大小必须小于 50 MB,并且尺寸必须至少为 50 x 50 像素,并且最多为 10,000 x 10,000 像素。
开始
可以使用文档智能从文档中提取文本、表头、选择标记和结构信息等数据。 需要以下资源:
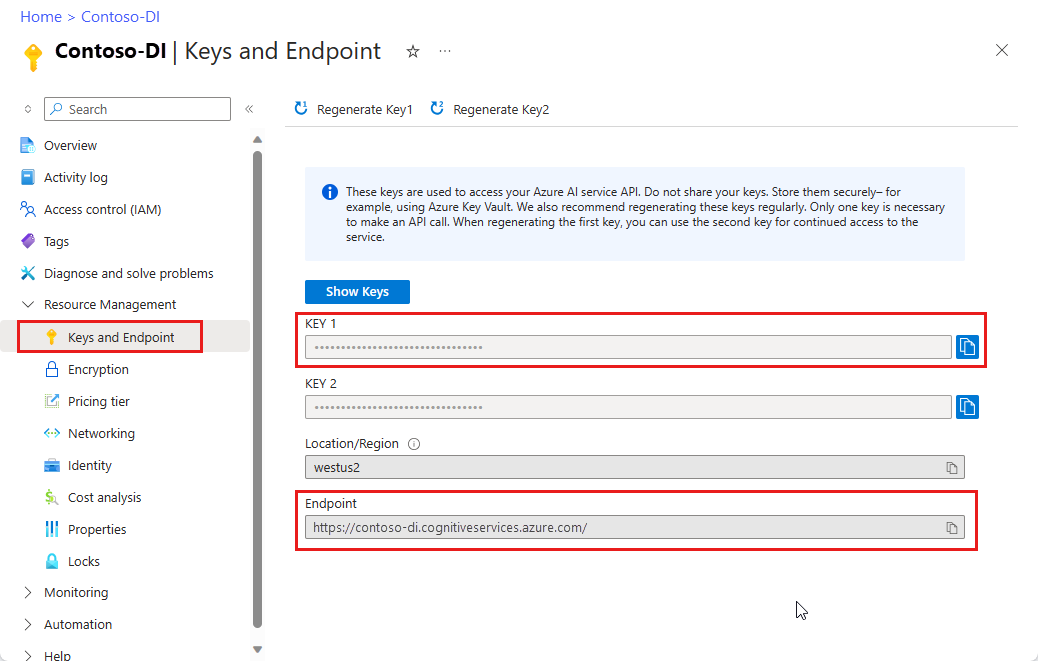
检索密钥和终结点后,可以使用以下开发选项来生成和部署文档智能应用程序。
注意
文档智能工作室提供 v3.0 API 及更高版本。
REST API
文档智能示例标记工具
转到 “文档智能示例标记”工具。
在示例工具主页上,选择“使用布局获取文本、表和选择标记”。
在“文档智能服务终结点”字段中,粘贴使用文档智能订阅获得的终结点。
在 密钥 字段中,粘贴从文档智能资源获取的密钥。
在 “源 ”字段中,从下拉菜单中选择 URL 。 可以使用示例文档:
示例文档。
选择 提取。
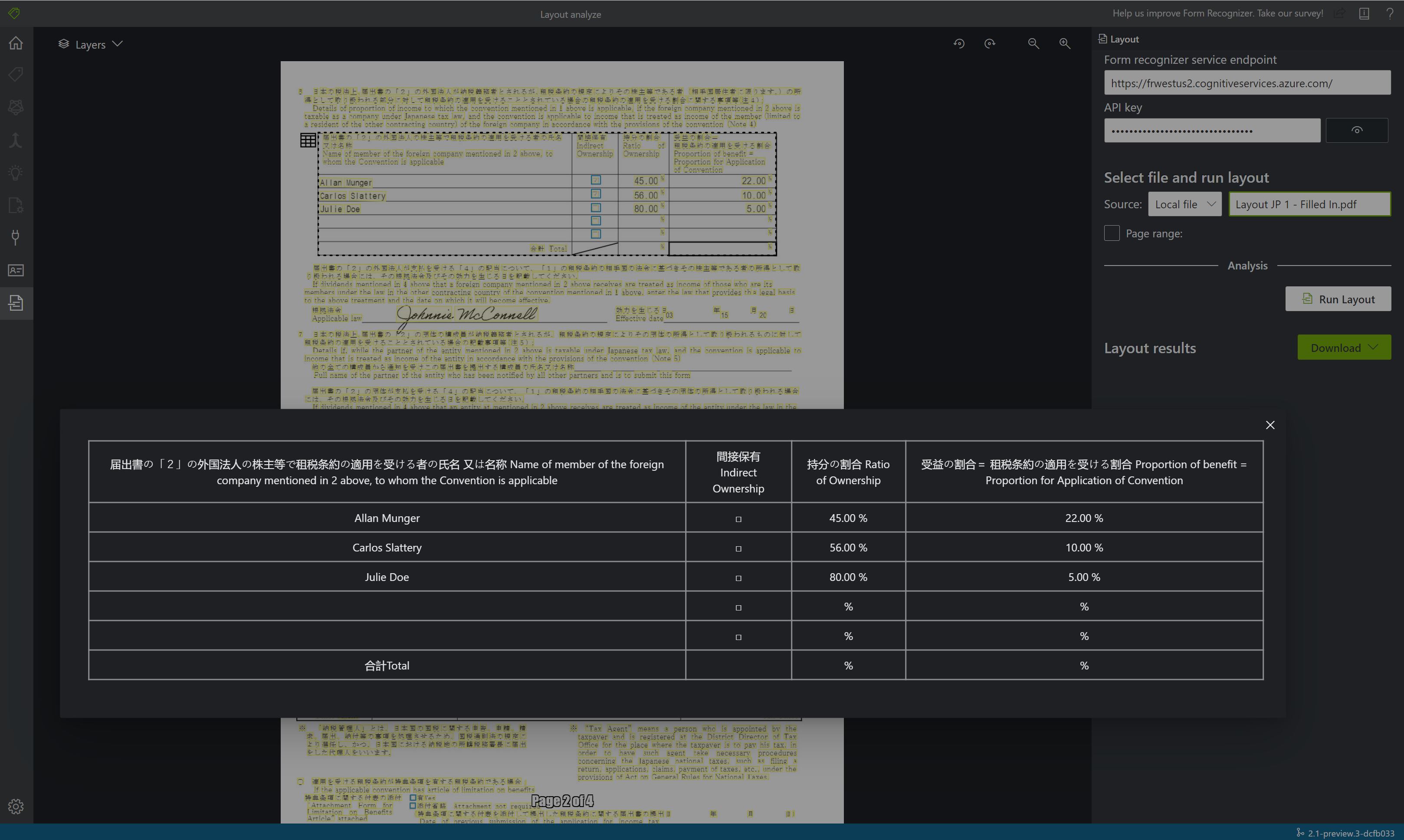
选择“运行布局”。 文档智能示例标记工具调用分析布局 API 来分析文档。
查看结果。 查看突出显示的提取文本、检测到的选择标记和检测到的表。
{kind=link}
Document Intelligence v2.1 支持以下工具、应用程序和库。
| 功能 | 资源 |
|---|---|
| 布局 API | • 文档智能标记工具 • REST API • 客户端库 SDK • 文档智能 Docker 容器 |
页
集合 pages 是文档内页面的列表。 每个页面在文档中按顺序表示,并包括方向角度,指示页面是否旋转以及宽度和高度(尺寸(以像素为单位)。 模型输出中的页面单位的计算如下表所示。
| 文件格式 | 计算页单位 | 总页数 |
|---|---|---|
| 图片(JPEG/JPG、PNG、BMP、HEIF) | 每个图像 = 1 页单位。 | 图像总数 |
| PDF 中的每个页面 = 1 页单位。 | PDF 中的总页数 | |
| TIFF | TIFF 中的每个图像 = 1 页单元。 | TIFF 中的图像总数 |
| Word(DOCX) | 最多 3,000 个字符 = 1 页单位。 不支持嵌入或链接的图像。 | 每页最多 3,000 个字符的总页数 |
| Excel (XLSX) | 每个工作表 = 1 页单位。 不支持嵌入或链接的图像。 | 工作表总数 |
| PowerPoint (PPTX) | 每张幻灯片 = 1 页单位。 不支持嵌入或链接的图像。 | 幻灯片总数 |
| HTML | 最多 3,000 个字符 = 1 页单位。 不支持嵌入或链接的图像。 | 每页最多 3,000 个字符的总页数 |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
从文档中提取所选页面
对于大型多页文档,请使用 pages 查询参数指示用于文本提取的特定页码或页范围。
段落
在 paragraphs 集合中识别的所有文本块将被布局模型提取为 analyzeResults 下的顶级对象。 此集合中的每个条目代表一个文本块,其中包括提取的文本以及边界contentpolygon坐标。
span 信息指向包含文档全文的顶级 content 属性中的文本片段。
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
段落角色
基于机器学习的新页面对象检测提取了诸如标题、节标题、页眉、页脚等逻辑角色。 文档智能布局模型使用模型预测的专用角色或类型分配集合中的 paragraphs 某些文本块。 对于非结构化文档,最好使用段落角色来帮助了解所提取内容的布局,从而进行更丰富的语义分析。 支持以下段落角色。
| 预测角色 | Description | 支持的文件类型 |
|---|---|---|
title |
页面中的主标题 | PDF、Image、DOCX、PPTX、XLSX、HTML |
sectionHeading |
页面上的一个或多个子标题 | PDF、Image、DOCX、XLSX、HTML |
footnote |
页面底部附近的文本 | PDF、图像 |
pageHeader |
页面顶部边缘附近的文本 | PDF、Image、DOCX |
pageFooter |
页面底部边缘附近的文本 | PDF、Image、DOCX、PPTX、HTML |
pageNumber |
页码 | PDF、图像 |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
文本、行和单词
文档智能中的文档布局模型将打印和手写样式的文本提取为线条和单词。 当检测到行的任何手写样式时,styles 集合会包含这些手写样式以及用于指向关联文本的跨度。 此功能适用于受支持的手写语言。
对于 Word、Excel、PowerPoint 和 HTML,文档智能 v4.0 2024-11-30 (GA) 布局模型按原样提取所有嵌入文本。 文本被提取为字词和段落。 不支持嵌入图像。
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
手写风格
响应将分类说明每个文本行是否为手写体,同时包括置信度评分。 有关详细信息,请参阅 手写语言支持。 以下示例演示了一个示例 JSON 片段。
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
如果启用 字体/样式加载项功能,则还会获取作为对象的一部分的 styles 字体/样式结果。
选择标记
布局模型还会从文档中提取选择标记。 提取的选定标记显示在每个页面的 pages 集合中。 它们包括边界polygon、confidence和选择项state (selected/unselected)。 "文本表示形式(即:selected:和:unselected)也被包含为起始索引(offset),并且length引用了包含文档全文的顶级content属性。"
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
表
提取表是处理包含通常格式化为表的大量数据的文档的关键要求。 布局模型提取 JSON 输出部分中的表 pageResults 。 提取的表信息包括列数和行数、行范围和列范围。 每个单元格及其边界多边形都会输出,并包含该区域是否被识别为 columnHeader 的信息。
该模型支持提取已旋转的表格。 每个表格单元格都包含行和列的索引以及界限多边形坐标。 对于单元格文本,模型输出 span 包含起始索引的信息(offset)。 该模型还在包含文档全文的顶级内容中输出length。
使用“文档智能”提取功能时,需要考虑以下几个因素:
- 要提取的数据是否以表的形式呈现,该表的结构是否有意义?
- 如果数据不采用表格式,数据是否适合放入二维网格?
- 表格是否跨越多个页面? 如果是这样,为了避免必须标记所有页面,请将 PDF 拆分为页面,然后再将其发送到文档智能。 分析后,将页面后处理为单个表。
- 如果创建自定义模型,请参阅 表格字段 。 对于每个列,动态表包含可变数量的行。 对于每个列,固定表包含恒定数量的行。
注意
如果输入文件为 XLSX,则不支持表分析。 文档智能 v4.0 2024-11-30 (GA) 支持仅涵盖核心内容的图形和表的边界区域,并排除关联的标题和脚注。
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
批注
布局模型提取文档中的批注,例如勾号和叉号。 响应中包括批注类型、置信度分数和边框多边形。
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
自然读取顺序输出(仅限拉丁语)
你可以使用 readingOrder 查询参数指定文本行的输出顺序。 使用 natural 提供更符合人类习惯的阅读顺序输出,如以下示例所示。 此功能仅支持拉丁语言。

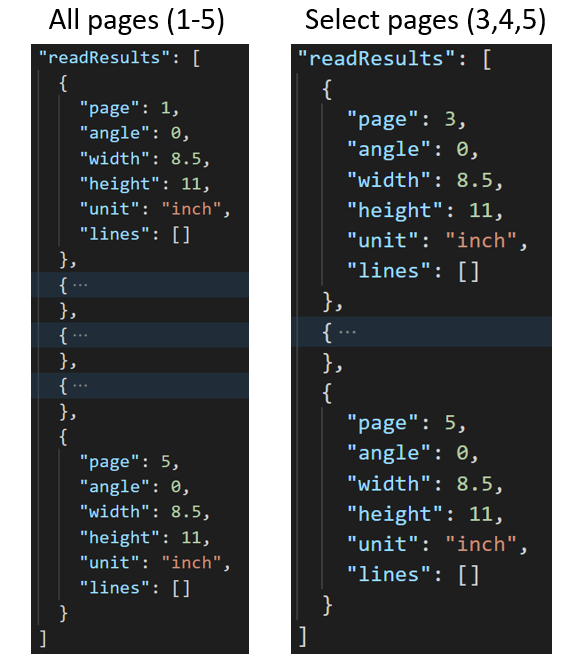
选择用于文本提取的页码或范围
对于大型多页文档,请使用 pages 查询参数指示用于文本提取的特定页码或页范围。 以下示例显示了一个文档,其中包含 10 页,为两种情况提取文本、所有页面(1-10 页)和所选页面(3-6)。
获取分析布局结果操作
第二步是调用 Get Analyze Layout Result 操作。 此操作使用Analyze Layout 操作创建的结果 ID 作为输入。 此操作返回一个 JSON 响应,其中包含具有以下可能值的 status 字段。
| 字段 | 类型 | 可能值 |
|---|---|---|
| 地位 | 字符串 |
notStarted:分析操作未启动。running:正在进行分析操作。failed:分析操作失败。succeeded:分析操作成功。 |
可以不断地以迭代方式调用此操作,直到它返回 succeeded 值为止。 若要避免超过每秒请求数速率,请使用 3 到 5 秒的间隔。
当 状态 字段具有 succeeded 值时,JSON 响应包括提取的布局、文本、表和选择标记。 提取的数据包括提取的文本行和单词、边界框、文本外观(含手写指示)、表格和选择标记(指示已选中/未选中)。
文本行的手写分类(仅限拉丁语)
响应包括对每个文本行是否采用手写样式以及置信度分数进行分类。 此功能仅支持拉丁语言。 示例展示了图像中手写文本的分类。

示例 JSON 输出
对Get Analyze Layout Result操作的响应是文档的结构表示形式,其中包含提取的所有信息。
请参阅 示例文档文件 及其结构化输出 示例布局输出。
JSON 输出分为两个部分:
- 该
readResults节点包含所有已识别的文本和选择标记。 文本呈现层次结构是页面、行和单个单词。 -
pageResults节点包含提取出的表格和单元格,这些元素附带了边界框、置信度,并引用了readResults字段中的行和单词。
示例输出
文本
布局 API 从具有多个文本角度和颜色的文档和图像中提取文本。 它接受文档、传真、印刷和/或手写(仅限英文)文本和混合模式的照片。 提取文本时会提供有关行、词、边界框、置信度评分和样式(手写体或其他样式)的信息。 所有文本信息都包含在 JSON 输出的 readResults 部分中。
包含表头的表
布局 API 从 JSON 输出的 pageResults 段落中提取表。 可以扫描、拍摄或数字化处理文档。 表可能会比较复杂,有的带合并单元格或列,有的带边框,有的不带边框,还有的带奇角。
提取的表信息包括列数和行数、行范围和列范围。 输出带有边界框的每个单元格,并指明该区域是否识别为标头的一部分。 模型预测的标头单元格可以跨越多行,不一定是表中的第一行。 它们也能与旋转的表格一起工作。 每个表格单元格还包括全文,并提供对readResults部分的各个单词的引用。
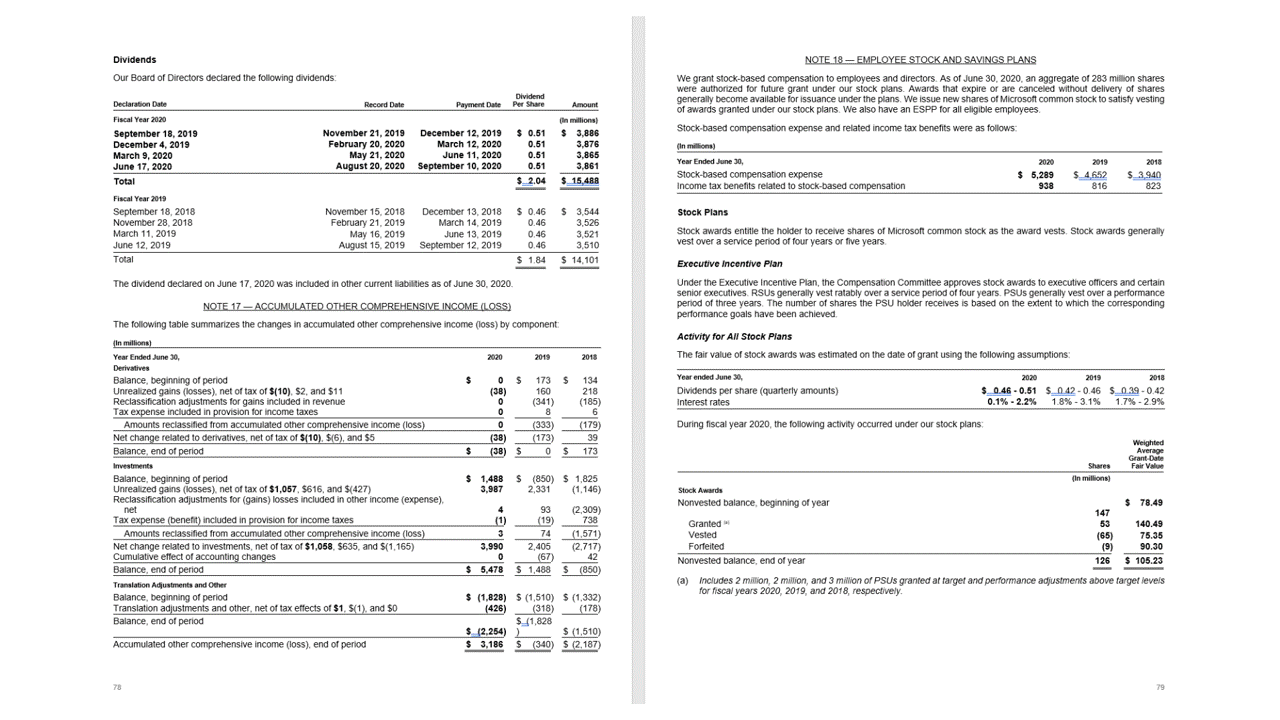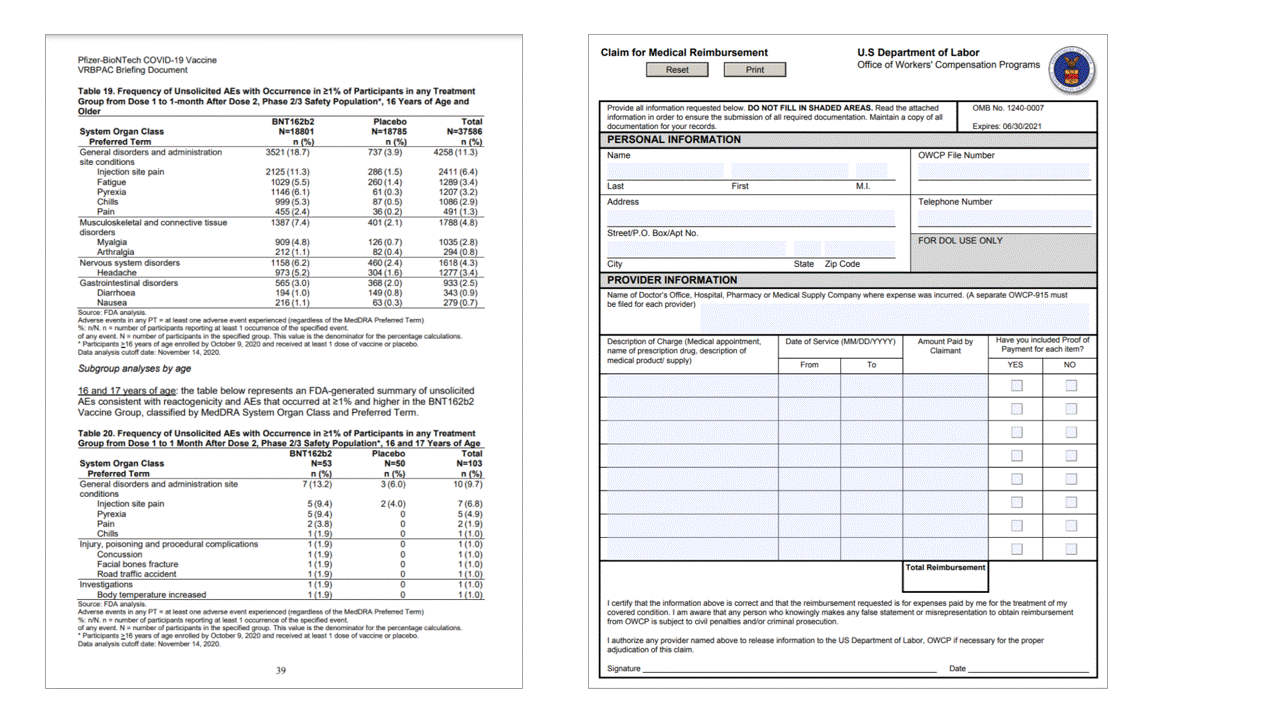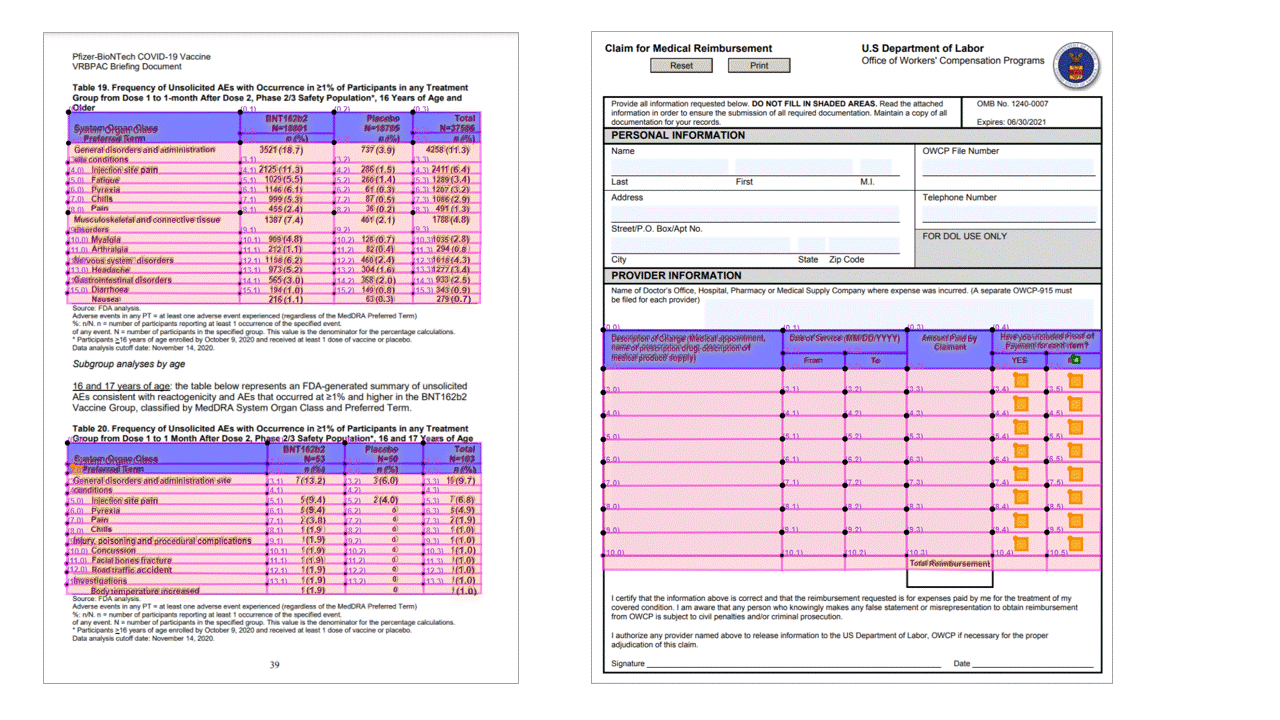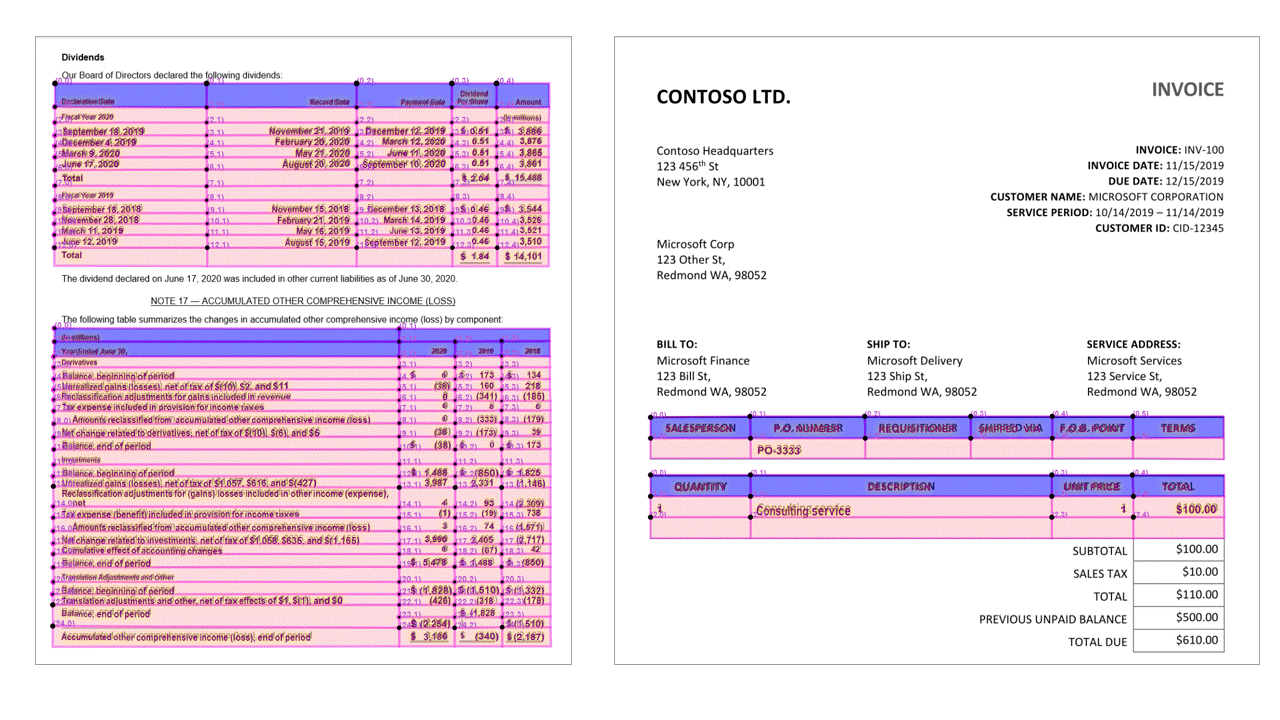
选择标记(文档)
布局 API 还会从文档中提取选择标记。 提取的选择标记包含边界框、置信度和状态(已选择/未选择)。 在 JSON 输出的 readResults 部分提取选择标记信息。
迁移指南
- 若要了解如何在应用程序和工作流中使用 v3.1 版本,请按照 文档智能 v3.1 迁移指南中的步骤进行作。
相关内容
- 了解如何使用文档智能工作室处理自己的表单和文档。
- 完成 文档智能快速入门,并在所选的开发语言中创建文档处理应用。
- 了解如何使用文档智能示例标记工具处理自己的表单和文档。
- 完成 文档智能快速入门,并在所选的开发语言中创建文档处理应用。