Power BI Desktop 是免费的应用程序,可让你连接、转换和可视化你的数据。 关键短语提取是 Azure 语言的功能之一,提供自然语言处理。 给定原始的非结构化文本,它可以提取最重要的短语、分析情绪和确定已知实体(例如品牌)。 可以综合使用这些工具快速了解客户谈论的内容和客户的感受。
本教程中,您将学习如何:
- 使用 Power BI Desktop 导入和转换数据
- 在 Power BI Desktop 中创建自定义函数
- 将 Power BI Desktop 与语言的关键短语提取功能集成
- 使用关键短语提取功能从客户反馈中获取最重要的短语
- 从客户反馈创建词云
先决条件
- Power BI Desktop。 免费下载。
- 一个 Azure 帐户。 创建试用版或登录。
- 语言资源。 如果没有语言资源,可以创建一个。
- 创建资源时为你生成的语言资源密钥。
- 客户评论。 可以使用我们的示例数据或你自己的数据。 本教程假定你使用我们的示例数据。
加载客户数据
打开 Power BI Desktop 并加载你在先决条件中下载的逗号分隔值 (CSV) 文件即可开始。 此文件代表某个虚构小公司的支持论坛中一天的虚构活动。
注意
Power BI 可以使用各种基于 Web 的源(例如 SQL 数据库)提供的数据。 有关详细信息, 请参阅Power Query 文档。
在 Power BI Desktop 主窗口中,选择“开始”功能区。 在功能区的“外部数据”组中,打开“获取数据”下拉菜单,然后选择“文本/CSV”。
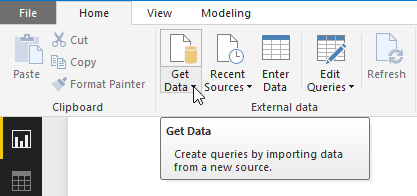
此时会显示“打开”对话框。 导航到“下载”文件夹,或你下载 CSV 文件的文件夹。 选择该文件的名称,然后单击“打开”按钮。 此时会显示 CSV 导入对话框。
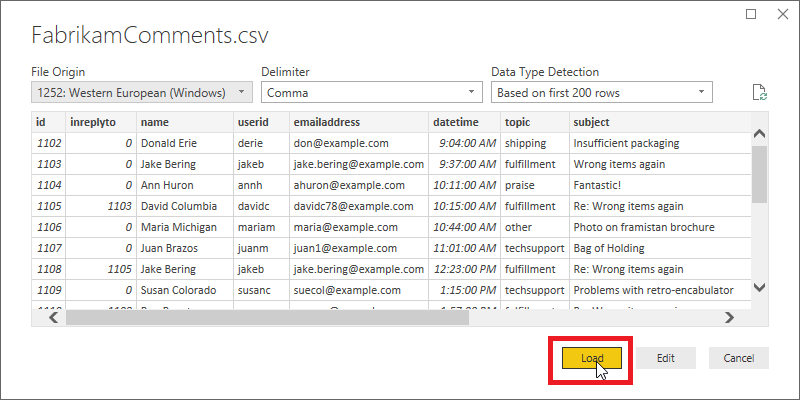
通过 CSV 导入对话框,可以验证 Power BI Desktop 是否正确检测到字符集、分隔符、标题行和列类型。 这些信息全都正确,所以选择“加载”。
若要查看加载的数据,请选择 Power BI 工作区左边缘的数据 视图 按钮。 将会打开一个包含数据的表,就像在 Microsoft Excel 中一样。
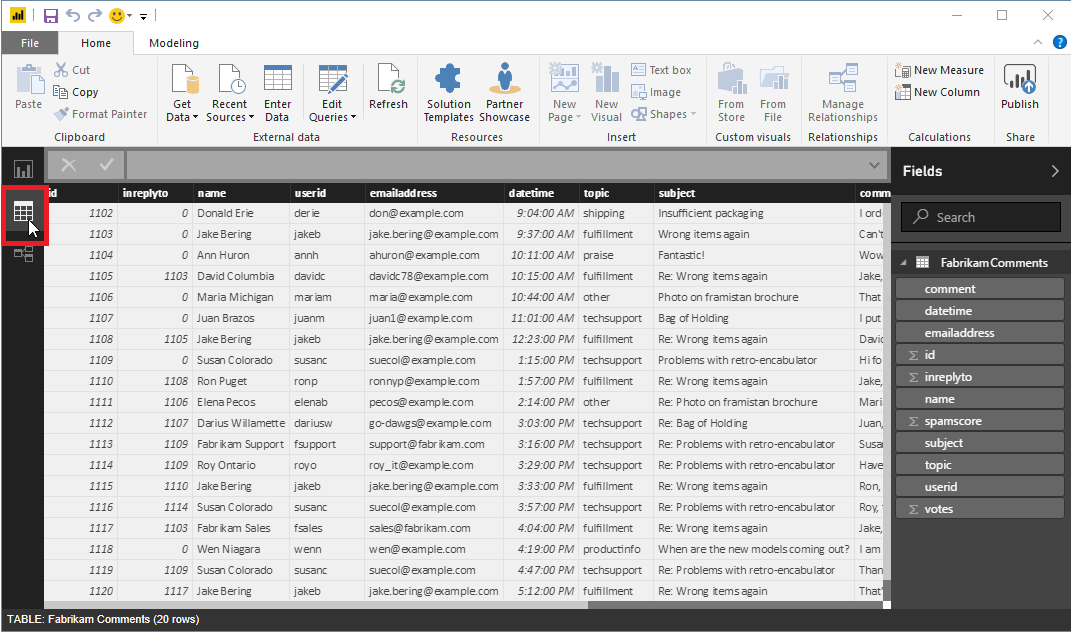
准备数据
在关键短语提取处理之前,可能需要在 Power BI Desktop 中转换数据。
示例数据包含一个 subject 列和一个 comment 列。 使用 Power BI Desktop 中的“合并列”功能,你可以从这两个列(而非仅仅 comment 列)的数据中提取关键短语。
在 Power BI Desktop 中,选择“开始”功能区。 在“外部数据”组中,选择“编辑查询”。
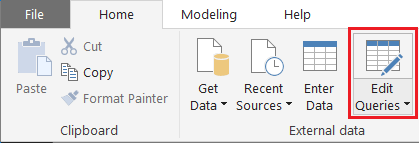
选择窗口左侧“查询”列表中的 FabrikamComments(如果尚未选择)。
现在请选择表中的 subject 和 comment 列。 可能需要进行水平滚动才能看到这些列。 首先选择 subject 列标题,然后按住 Control 键并选择 comment 列标题。
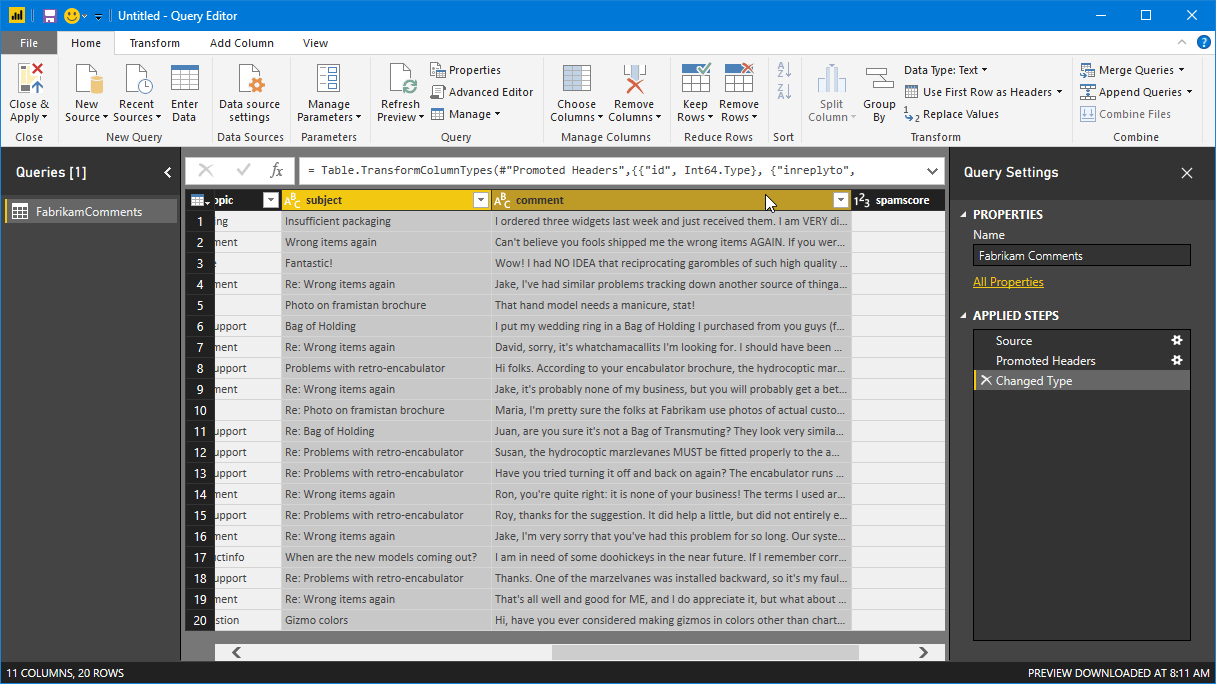
选择“转换”功能区。 在功能区的“文本列”组中,选择“合并列”。 此时会显示“合并列”对话框。
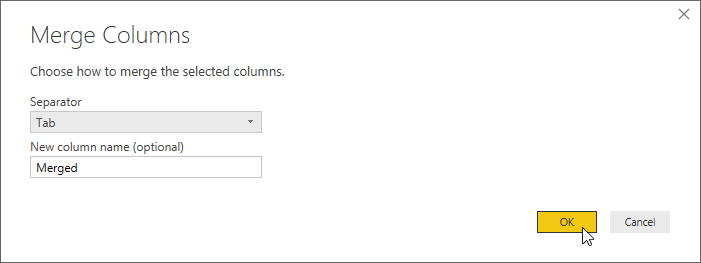
在“合并列”对话框中,选择 Tab 作为分隔符,然后选择“确定”。
也可考虑使用“删除空白”筛选器筛选掉空白消息,或者使用“洁净转换”删除无法打印的字符。 如果数据包含的一个列类似于示例文件中的 spamscore 列,则可使用“数字筛选器”跳过“垃圾”评论。
了解 API
对于每个 HTTP 请求,关键短语提取最多可以处理一千个文本文档。 Power BI 倾向于一次处理一个记录,因此在本教程中,对 API 的调用仅包含一个文档。 对于每个要处理的文档,关键短语 API 要求提供以下字段。
创建自定义函数
现在,你已准备好创建集成 Power BI 和关键短语提取的自定义函数。 此函数将要处理的文本作为参数接收。 它将数据转换为所需的 JSON 格式或从该格式进行转换,并对关键短语 API 发出 HTTP 请求。 然后该函数会分析来自 API 的响应,并返回包含所提取关键短语的逗号分隔列表的字符串。
注意
Power BI Desktop 自定义函数是以 Power Query M 公式语言(简称“M”)编写的。 M 是基于 F# 的函数编程语言。 不过,你无需成为程序员即可完成本教程;包含所需的代码。
在 Power BI Desktop 中,确保你仍处于“查询编辑器”窗口。 如果并非如此,请选择“主页”功能区,然后在“外部数据”组中,选择“编辑查询”。
现在,在“开始”功能区的“新建查询”组中,打开“新建源”下拉菜单并选择“空白查询”。
此时会在“查询”列表中显示新查询(初始名称为 Query1)。 双击此条目,将其命名为 KeyPhrases。
现在,在“主页”功能区的“查询”组中,选择“高级编辑器”以打开高级编辑器窗口。 删除该窗口中的现有代码,将以下代码粘贴到其中。
注意
将以下示例终结点(包含 <your-custom-subdomain>)替换为为语言资源生成的终结点。 可以通过登录到 Azure 门户,导航到你的资源并选择“密钥和终结点”来找到此终结点。
// Returns key phrases from the text in a comma-separated list
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.cn/text/analytics" & "/v3.0/keyPhrases",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""en"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
keyphrases = Text.Lower(Text.Combine(jsonresp[documents]{0}[keyPhrases], ", "))
in keyphrases
将 YOUR_API_KEY_HERE 替换为你的语言资源密钥。 还可以通过登录到 Azure 门户,导航到你的语言资源并选择“密钥和终结点”页来找到此密钥。 请务必保留密钥前后的引号。 然后选择“完成”。
使用自定义函数
现在可以使用自定义函数从每个客户评论中提取关键短语并将其存储在表的新列中。
在 Power BI Desktop 的查询编辑器窗口中,切换回 FabrikamComments 查询。 选择“添加列”功能区。 在“常规”组中,选择“调用自定义函数”。
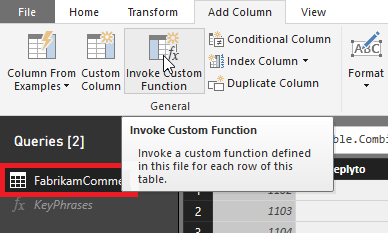
将出现“调用自定义函数”对话框。 在“新列名”中,输入 。 在“函数查询”中,选择你创建的自定义函数 。
对话框中将出现新字段“文本(可选)”。 此字段会询问我们希望使用哪一列来提供关键短语 API 的 text 参数的值。 (请记住,你已经硬编码了 language 和 id 参数的值。)从下拉菜单中选择 Merged(此前通过合并主题和消息字段所创建的列)。
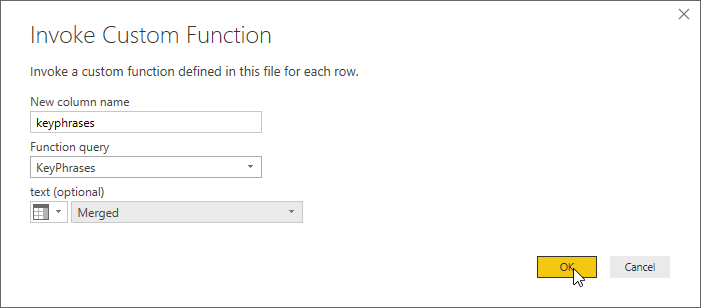
最后选择“确定”。
如果一切准备就绪,Power BI 将针对表中的每一行调用自定义函数一次。 它将查询发送到关键短语 API,并为表添加一个新列来存储结果。 但在这些操作开始之前,可能需要指定身份验证和隐私设置。
身份验证和隐私
在关闭“调用自定义函数”对话框之后,可能会出现一个横幅,要求你指定如何连接到关键短语 API。

选择“编辑凭据”,确保选中对话框中的 Anonymous,然后选择“连接”。
注意
之所以选择 Anonymous ,是因为关键短语提取使用访问密钥对请求进行身份验证,因此 Power BI 不需要为 HTTP 请求本身提供凭据。
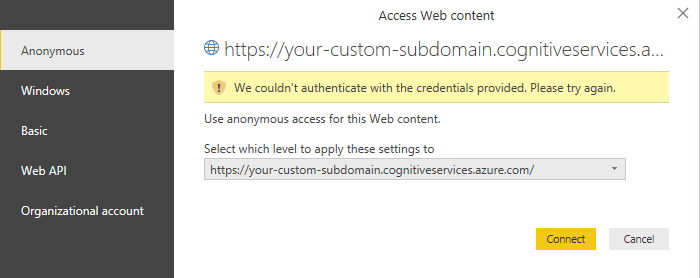
如果在选择匿名访问后看到“编辑凭据”横幅,请检查是否已将语言资源密钥粘贴到KeyPhrases中的代码中。
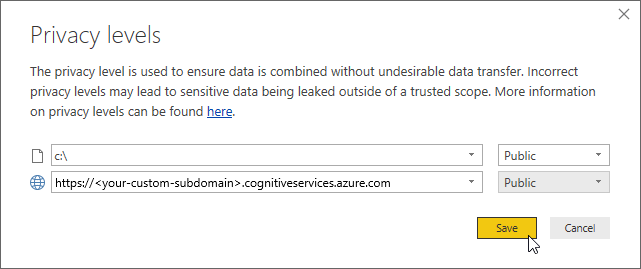
接下来可能会出现一个横幅,要求你提供有关数据源隐私的信息。

对于对话框中的每个数据源,请选择“继续”,然后选择 Public。 然后选择“保存”。
创建词云
使用显示的任何横幅进行寻址后,选择“开始”功能区中的 “关闭和应用 ”以关闭查询编辑器。
Power BI Desktop 需要时间来发出必需的 HTTP 请求。 对于表中的每一行,新的 keyphrases 列都包含关键短语 API 在文本中检测到的关键短语。
现在,使用此列生成单词云。 若要开始,请选择工作区左侧 Power BI Desktop 主窗口中的 “报表 ”按钮。
注意
为何使用提取的关键短语而不是每个评论的完整文本来生成词云? 关键短语提供的是客户评论中的重要词汇,而不仅仅是最常见词汇。 此外,生成的词云中单词的大小与其在相对较少的评论中的频繁使用无关。
如果尚未安装词云自定义视觉对象,请安装它。 在工作区右侧的“可视化效果”面板中,选择三个点(...),然后选择 “从市场导入”。 如果“云”一词不在列表中显示的可视化工具中,则可以搜索“云”并选择 Word Cloud 视觉对象旁边的“ 添加 ”按钮。 Power BI 会安装词云视觉对象并会让你知道它已成功安装。

首先,在“可视化效果”面板中选择“Word Cloud”图标。

此时会在工作区中显示新的报表。 将 keyphrases 字段从“字段”面板拖至“可视化效果”面板中的“类别”字段。 词云会显示在报表中。
现在,请切换到“可视化效果”面板的“格式”页面。 在“非索引字”类别中启用“默认非索引字”,以便从云中消除短的常用词,例如“of”。 不过,由于我们要可视化关键短语,因此它们可能不包含非索引字。
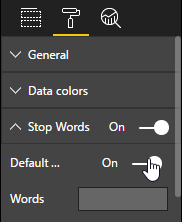
向下滚动面板并关闭 “旋转文本 ”和 “标题”。

选择报表中的“焦点模式”工具可以更好地查看词云。 该工具扩展单词云以填充整个工作区。

使用其他功能
语言还提供情绪分析和语言检测。 语言检测尤其适用于客户反馈不完全是英语的情况。
这两个其他的 API 类似于关键短语 API。 这意味着可以使用与你在本教程中所创建的近乎相同的自定义函数,将它们与 Power BI Desktop 集成。 只需创建一个空白查询,并将相应的代码粘贴到高级编辑器中,就像之前所做的那样。 (请勿忘记访问密钥!)然后,像以前那样,使用函数向表添加新列。
下面的情绪分析函数返回一个标签,指示文本中表达的情绪的正面程度。
// Returns the sentiment label of the text, for example, positive, negative or mixed.
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "<your-custom-subdomain>.cognitiveservices.azure.cn" & "/text/analytics/v3.1/sentiment",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""en"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
sentiment = jsonresp[documents]{0}[sentiment]
in sentiment
下面是两个版本的语言检测函数。 第一个返回 ISO 语言代码(例如,表示英语的 en),而第二个则返回“友好”名称(例如 English)。 可以看到,这两个版本仅正文的最后一行有差异。
// Returns the two-letter language code (for example, 'en' for English) of the text
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.cn" & "/text/analytics/v3.1/languages",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
language = jsonresp [documents]{0}[detectedLanguage] [name] in language
// Returns the name (for example, 'English') of the language in which the text is written
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.cn" & "/text/analytics/v3.1/languages",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
language =jsonresp [documents]{0}[detectedLanguage] [name] in language
最后,下面是此前已提供的关键短语函数的变体,它返回的短语是列表对象,而不是单个字符串(包含逗号分隔的短语)。
注意
返回单个字符串简化了词云示例。 而列表则是更灵活的格式,可以与 Power BI 中返回的短语配合使用。 可以使用查询编辑器的“转换”功能区中的“结构化列”组来操作 Power BI Desktop 中的列表对象。
// Returns key phrases from the text as a list object
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.cn" & "/text/analytics/v3.1/keyPhrases",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""en"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
keyphrases = jsonresp[documents]{0}[keyPhrases]
in keyphrases
后续步骤
详细了解语言、Power Query M 公式语言或 Power BI。
- 语言概述
- Power Query M reference(Power Query M 参考)
- Power BI 文档