注意
若要探索 Viseme ID 和混合形状支持的区域设置,请参阅所有受支持的区域设置的列表。 仅 en-US 区域设置支持可缩放的矢量图形 (SVG) 。
视素是口语中音素的视觉描述。 它定义了一个人说话时面部和嘴巴的位置。 每个视素都描绘与一组特定音素对应的关键人脸姿态。
可以使用视素来控制 2D 和 3D 头像模型的运动,使面部位置与合成语音完美对齐。 例如,你能够:
- 为智能展台创建动画虚拟语音助手,为客户构建多模式集成服务。
- 构建沉浸式新闻广播并通过自然面部和口部运动改善观众体验。
- 生成更多交互式游戏头像和可与动态内容交谈的卡通角色。
- 制作更有效的语言教学视频,帮助语言学员了解每个单词和音素的口部行为。
- 听障人士还可以直观地拾取声音,通过“唇读”来理解在动态人脸上显示视素的语音内容。
使用语音制作视素的整体工作流
神经文本转语音(神经 TTS)将输入文本或 SSML(语音合成标记语言)转换为逼真的合成语音。 语音音频输出可以附带视素 ID、可扩展矢量图形 (SVG) 或混合形状。 使用 2D 或 3D 渲染引擎,您可以利用这些视素事件为您的头像制作动画。
以下流程图描述了视素的整体工作流:
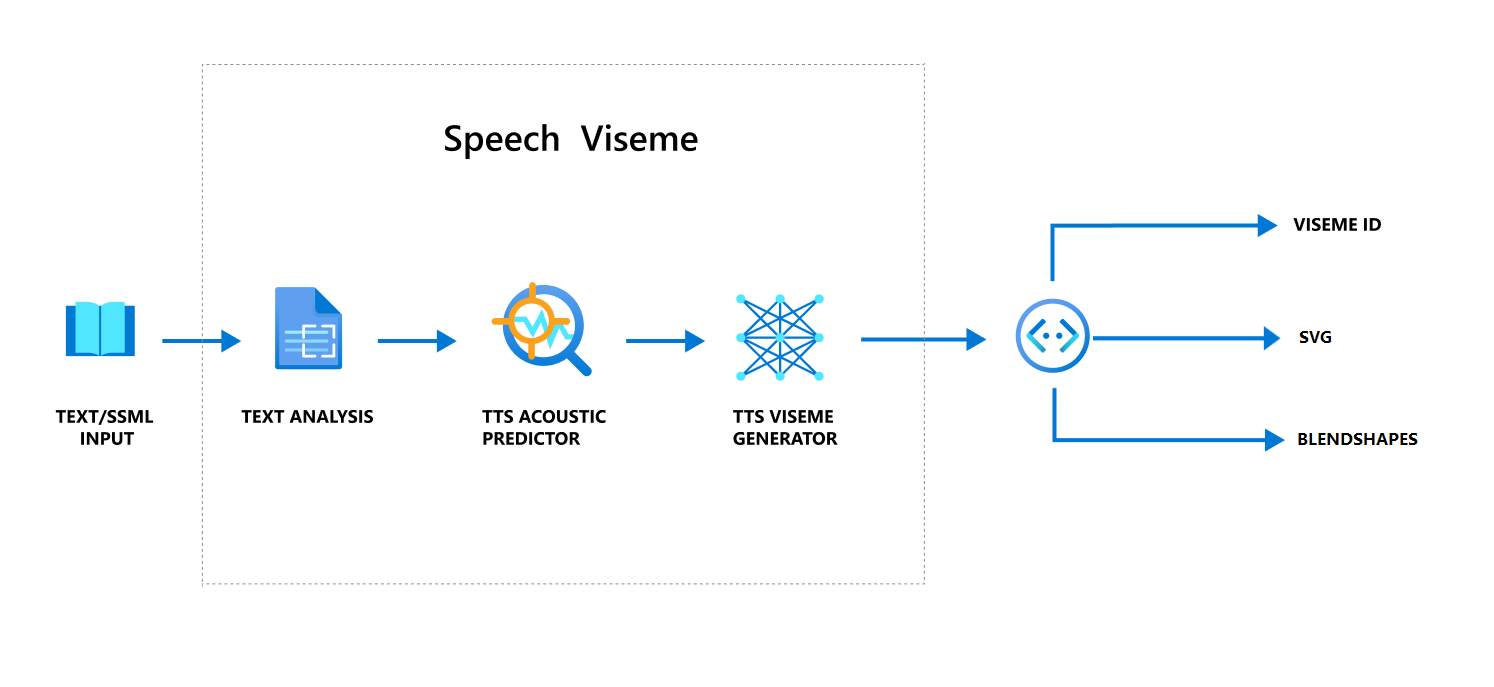
视素 ID
视位 ID 是用于指定视位的整数。 我们提供了 22 个不同的视素,每个视素描述一组特定音素的嘴部位置。 在视素和音素之间没有一对一的对应关系。 通常,多个音素对应一个视素,因为多个音素(如 s 和 z)在生成时在说话者的脸上看起来是相同的。 有关更具体的信息,请参阅将音素映射到视素 ID 的表格。
语音音频输出可以附带视素 ID 和 Audio offset。
Audio offset 指示偏移时间戳,表示每个视素的开始时间,以刻度(100 纳秒)为单位。
将音素映射到视素
视素因语言和本地化而异。 每种语言环境都有一组与其特定音素相对应的视素。 SSML 音标文档将视素 ID 映射到对应的国际音标 (IPA) 音素。 此部分中的表显示了视素 ID 与嘴部位置之间的映射关系,其中列出了每个视素 ID 的典型 IPA 音素。
| 视素 ID | IPA | 嘴部位置 |
|---|---|---|
| 0 | 静音 |

|
| 1 |
æ、ə、ʌ |

|
| 2 | ɑ |

|
| 3 | ɔ |

|
| 4 |
ɛ、ʊ |

|
| 5 | ɝ |

|
| 6 |
j、i、ɪ |

|
| 7 |
w、u |

|
| 8 | o |

|
| 9 | aʊ |

|
| 10 | ɔɪ |

|
| 11 | aɪ |

|
| 12 | h |

|
| 13 | ɹ |

|
| 14 | l |

|
| 15 |
s、z |

|
| 16 |
ʃ、tʃ、dʒ、ʒ |

|
| 17 | ð |

|
| 18 |
f、v |

|
| 19 |
d、t、n、θ |

|
| 20 |
k、g、ŋ |

|
| 21 |
p、b、m |

|
2D SVG 动画
对于 2D 人物,你可以设计一个适合你场景的角色形象,并为每个视素 ID 使用可缩放矢量图形 (SVG),以获得基于时间的面部位置。
使用在 viseme 事件中提供的时间标签,这些设计良好的 SVG 经过平滑处理,为用户提供了可靠的动画。 例如,下面的插图显示了为语言学习设计的红唇角色。

3D 混合形状动画
可以使用混合形状来驱动设计的 3D 角色的面部动作。
混合形状 JSON 字符串表示为二维矩阵。 每行代表一帧。 每帧(以 60 FPS 为单位)包含 55 个面部位置的数组。
使用语音 SDK 获取视素事件
若要获取合成语音的视素,请在语音 SDK 中订阅 VisemeReceived 事件。
注意
若要请求 SVG 或混合形状输出,应该使用 SSML 中的 mstts:viseme 元素。 有关详细信息,请参阅如何在 SSML 中使用视素元素。
以下代码片段演示了如何订阅视素事件:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
以下是视素输出的示例。
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
获取视素输出后,您可以使用这些事件以驱动角色动画。 可以生成自己的角色并自动对其进行动画处理。