在本指南中,我们审查使用 Strimzi 操作员在 Azure Kubernetes 服务(AKS) 上部署和操作高可用性 Apache Kafka 群集的先决条件、体系结构注意事项和组件。
重要
AKS 文档和示例中都提到了开源软件。 AKS 服务级别协议、有限保修和 Azure 支持不涵盖你部署的软件。 将开源技术与 AKS 一起使用时,请查阅相应社区和项目维护者提供的支持选项来制定计划。
Microsoft 将负责生成我们在 AKS 上部署的开源包。 该责任包括对生成、扫描、签名、验证和修补过程拥有完整的所有权,以及对容器映像中的二进制文件的控制。 如需了解详细信息,请参阅 AKS 漏洞管理和 AKS 支持范围。
什么是 Apache Kafka 和 Strimzi?
Apache Kafka 是一个开源分布式事件流式处理平台,旨在处理大容量、高吞吐量和实时流数据。 因此,数千家公司将它用于高性能数据管道、流分析、数据集成和任务关键型应用程序。 但是,管理和缩放 Kafka 群集可能具有挑战性,而且通常很耗时。
Strimzi 是一个开源项目,可简化 Apache Kafka on Kubernetes 上的部署、管理和作。 它提供了一组 Kubernetes 操作者和容器镜像,通过声明性配置自动化复杂的 Kafka 运维任务。
Strimzi 运算符遵循 Kubernetes 运算符模式来自动化 Kafka 操作。 它持续协调 Kafka 组件的声明状态及其实际状态,并自动处理复杂的作任务。
若要了解有关 Strimzi 的详细信息,请查看 Strimzi 文档。
组件
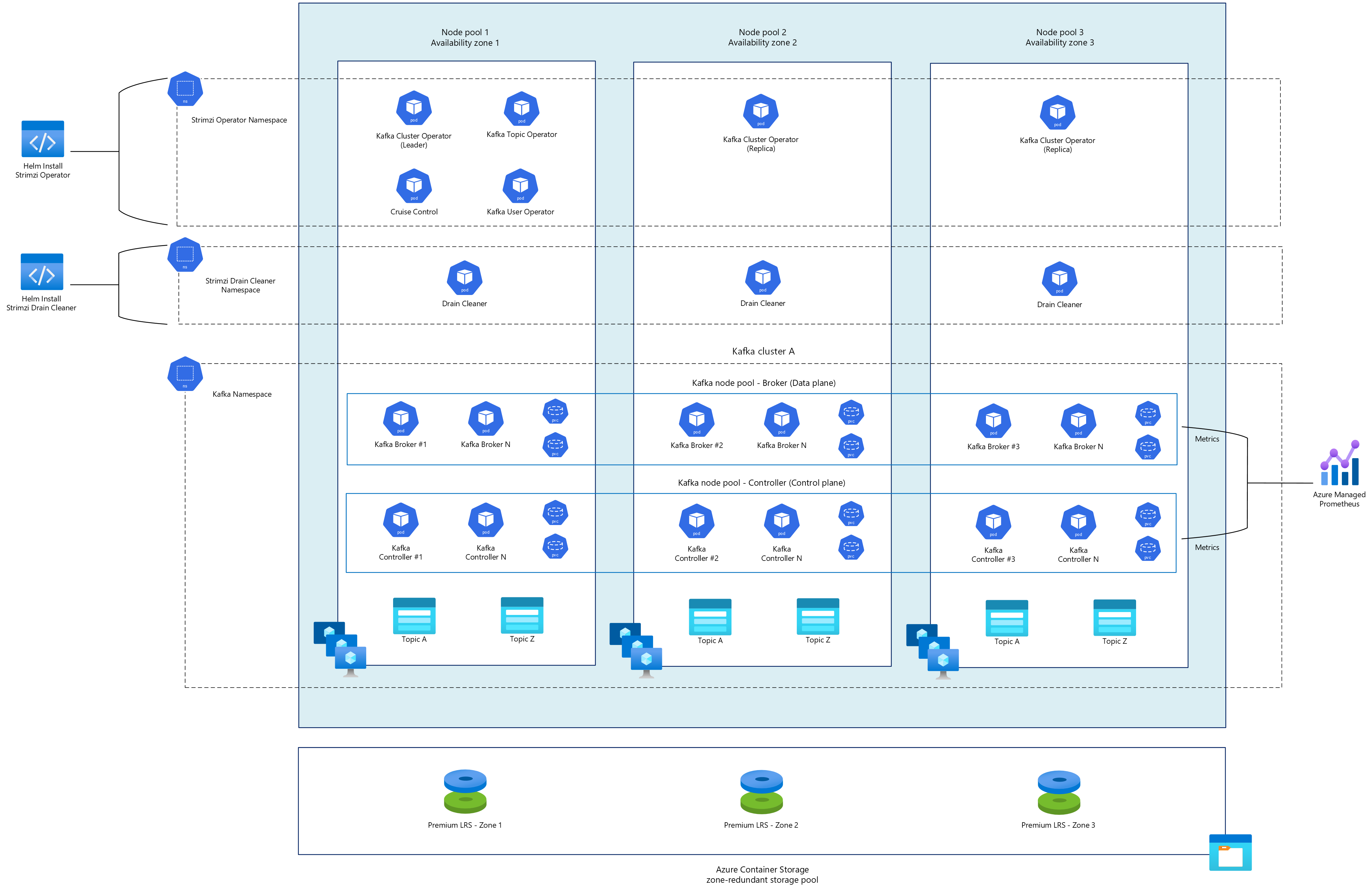
Strimzi 群集运算符
Strimzi 群集作员是管理整个 Kafka 生态系统的中心组件。 部署后,它还可以配置实体操作员,其中包括:
-
主题作员:基于
KafkaTopic自定义资源自动创建、修改和删除 Kafka 主题。 -
用户作员:通过
KafkaUser自定义资源管理 Kafka 用户及其访问控制列表(ACL)。
这些作员共同创建一个完全声明性的管理系统,其中 Kafka 基础结构被定义为 Kubernetes 资源,你可以对环境进行版本控制、审核和一致部署。
Kafka 群集
Strimzi 群集作员通过专用自定义资源管理 Kafka 群集:
- KafkaNodePools:定义具有特定角色(代理、控制器或两者)的 Kafka 节点组。
- Kafka:将所有内容关联在一起的主要自定义资源,定义群集范围的配置。
典型的 KafkaNodePools 和 Kafka 部署包括:
- 用于处理客户端流量和数据存储的专用中转站节点。
- 用于管理群集元数据和协调的专用控制器节点。
- 各个组件的多个副本分布在跨可用性区域。
巡航控制
Cruise Control 是一个高级组件,可为 Kafka 群集提供自动化工作负荷均衡和监视。 作为 Strimzi 管理的 Kafka 集群的一部分进行部署时,Cruise Control 提供:
- 自动分区重新均衡:在中转站之间重新分发分区以优化资源利用率。
- 异常情况检测:识别异常群集行为并发出警报。
- 自我修复功能:自动修复常见的群集不平衡问题。
- 工作负荷分析:提供群集性能和资源使用情况的见解。
随着工作负荷随时间的变化,巡航控制有助于保持最佳性能,从而减少在缩放事件期间或代理故障期间手动干预的需求。
管道清洁剂
Strimzi 清空清理器 是一个实用工具,旨在帮助管理 Strimzi 在 Kubernetes 节点排出期间部署的 Kafka 中转站 Pod。 Strimzi 清空清理器通过其允许 Webhook 截获 Kubernetes 节点排出作,以协调 Kafka 群集的正常维护。 在对 Kafka 代理 Pod 发出驱逐请求时,该请求会被检测到,排空清理器会标注这些 Pod,以指示 Strimzi 集群操作器进行重启处理,确保 Kafka 集群保持健康状态。 此过程在例行维护作或意外节点故障期间维护群集运行状况和数据可靠性。
何时在 AKS 上使用 Kafka
在以下情况下,请考虑在 AKS 上运行 Kafka:
- 需要对 Kafka 配置和操作进行完全控制。
- 你的用例需要托管产品/服务中不可用的特定 Kafka 功能。
- 你想要将 Kafka 与其他在 AKS 上运行的容器化应用程序集成。
- 需要在没有托管 Kafka 服务的区域进行部署。
- 你的组织在 Kubernetes 和容器编排方面具有已有专业知识。
对于更简单的用例或运营开销问题,请考虑使用完全托管的服务,例如 Azure 事件中心。
Kafka on AKS 的关键注意事项
Azure 磁盘存储
对于 AKS 上的 Kafka 部署,我们使用 Azure 磁盘 CSI 驱动,它提供由 Azure 托管磁盘支持的持久卷。 Strimzi 利用 一堆磁盘(JBOD) 配置来管理数据持久性。
为了确保跨基础结构故障实现高可用性,应使用通过 WaitForFirstConsumer 卷绑定模式跨可用区分布的 Premium SSD v2 磁盘来配置存储类。 这可确保 Pod 被调度到能够创建其持久卷的区域中。 高级 SSD v2 可以提供 IO 密集型 Kafka 工作负荷所需的延迟、高 IOPS 和一致的吞吐量,且成本结构优化。
下表提供了不同 Kafka 群集大小的高级 SSD v2 配置的起点:
| Kafka 群集大小 | 磁盘大小 | IOPS | Bandwidth |
|---|---|---|---|
|
小型 (3-9 代理) |
1 TB(兆字节) | 5,000 | 250 MB/秒 |
|
中等 (10-19 经纪人) |
2兆字节 | 10,000 | 500 MB/秒 |
|
大 (20+ 经纪人) |
4 TB(兆字节) | 20,000 | 1,000 MB/秒 |
实际所需的 IOPS、带宽和磁盘大小因特定的 Kafka 工作负荷特征而异。 随着应用程序的吞吐量和保留要求的变化,这些属性可能会随着时间推移而变化。
节点池
为 AKS 上的 Kafka 部署选择适当的节点池是直接影响性能、可用性和成本效益的关键体系结构决策。 Kafka 工作负荷具有独特的资源利用率模式,其特征是高吞吐量需求、存储 I/O 强度,以及在不同负载下保持一致性能的需求。 Kafka 通常是内存密集型多于 CPU 密集型。 但是,使用消息压缩/解压缩、SSL/TLS 加密或具有许多小消息的高吞吐量方案,CPU 要求可能会显著增加。
考虑到 Strimzi 的 Kubernetes 本机体系结构,其中每个 Kafka 中转站作为单个 Pod 运行,AKS 节点选择策略应针对水平缩放而不是单节点垂直缩放进行优化。 AKS 上的正确节点池配置可确保资源利用率高效,同时保持 Kafka 组件可靠运行所需的性能隔离。
Kafka 使用 Java 虚拟机(JVM)运行。 优化 JVM 对于最佳 Kafka 性能至关重要,尤其是在生产环境中。 LinkedIn,Kafka 的创建者共享了在 Java 上运行 Kafka 的典型参数,这些参数适用于LinkedIn最繁忙的群集之一: Kafka Java 配置。
对于本指南,内存堆大小为 6GB 将用作代理的基线,并另外分配 2GB 以满足堆外内存的使用。 对于控制器,3GB 内存堆将用作基线,额外 1GB 作为开销。
为 Kafka 部署调整 VM 的规格时,请考虑以下与工作负载相关的因素:
| 工作负荷因子 | 对大小调整的影响 | 注意事项 |
|---|---|---|
| 消息吞吐量 | 更高的吞吐量需要更多的 CPU、内存和网络容量。 | - 监视每秒传入/传出字节数。 - 考虑峰值吞吐量与平均吞吐量。 - 考虑未来的增长预测。 |
| 邮件大小 | 消息大小调整会影响 CPU、网络和磁盘要求。 | - 小消息(≤1KB)受 CPU 限制。 - 大于>1MB的消息在网络上传输时更受限。 - 非常大的消息可能需要专门的优化。 |
| 保留期 | 更长的保留期会增加存储要求。 | - 根据吞吐量×保留期计算总存储需求。 |
| 使用者计数 | 更多的使用者会增加 CPU 和网络负载。 | - 每个使用者组都会增加开销。 - 高扇出设计模式需要额外的资源。 |
| 主题分区 | 分区计数会影响内存利用率。 | - 每个分区消耗内存资源。 - 过度分区可能会降低性能。 |
| 基础结构开销 | 其他系统组件会影响 Kafka 的可用资源。 | - Azure 磁盘 CSI 驱动程序的资源开销最小。 - 监视代理、日志记录组件、网络策略和安全工具增加了额外的开销。 为系统组件预留开销。 |
重要
以下建议仅用作起始指南。 最佳 VM SKU 选择应根据特定的 Kafka 工作负荷特征、数据模式和性能要求进行定制。 每个代理 Pod 估计有大约 8GB 的保留内存。 每个控制器 Pod 估计有大约 4GB 的保留内存。 您的 JVM 和堆内存要求可能会更大或更小。
小型到中型 Kafka 群集
| 虚拟机产品编号 | vCPU | RAM | 网络 | 中转站密度 (估计) | 主要优势 |
|---|---|---|---|---|---|
| Standard_D8ds | 8 | 32 GB | 12,500 Mbps | 每个节点 1-3 个 | 横向缩放经济高效,但随着缩放的增加,可能需要更多节点。 |
| Standard_D16ds | 16 | 64 GB | 12,500 Mbps | 每个节点 3-6 个 | 通过额外的 vCPU 和 RAM 提高资源利用率,需要更少的 AKS 节点。 |
大型 Kafka 群集
| 虚拟机产品编号 | vCPU | RAM | 网络 | 中转站密度 (估计) | 主要优势 |
|---|---|---|---|---|---|
| Standard_E16ds | 16 | 128 GB | 12,500 Mbps | 每个节点6个以上 | - 改善数据密集型大规模操作的性能,并优化高内存与核心比率。 - 可以支持更大的内存堆或更多水平缩放。 |
在完成生产环境之前,建议执行以下步骤:
- 使用具有代表性的数据卷和模式执行负载测试。
- 在高峰负载期间监视 CPU、内存、磁盘和网络利用率。
- 根据观察到的瓶颈,调整 AKS 节点池的 SKU 规格。
- 审查节点池 SKU 的成本。
高可用性和复原能力
若要确保 Kafka 部署的高可用性,应:
- 跨多个可用性区域进行部署。
- 配置适当的副本分发约束。
- 设定适当的 Pod 中断预算。
- 配置 Cruise Control 以重新均衡主题分区。
- 使用 Strimzi 清空清理器来处理节点清空和维护作。
监视和操作
有效监控 Kafka 群集包括:
- JMX 指标收集配置。
- 使用 Kafka 导出程序进行消费者延迟监视。
- 与 Azure 托管 Prometheus 和 Azure Managed Grafana 集成。
- 针对关键绩效指标和健康状况指标发出警报。
后续步骤
供稿人
Microsoft维护本文。 以下贡献者最初撰写了这篇文章:
- 塞尔吉奥·纳瓦尔 |高级客户工程师
- Erin Schaffer | 内容开发人员 2