Azure SQL 中的加速数据库恢复
适用于: ![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例
加速的数据库恢复 (ADR) 是一项 SQL Server 数据库引擎功能,通过重新设计 SQL Server 数据库引擎恢复过程,极大地提高数据库可用性(尤其是存在长期运行的事务时)。
ADR 目前可用于 Azure SQL 数据库、Azure SQL 托管实例、Azure Synapse Analytics 中的数据库,以及 Azure VM 上的 SQL Server(从 SQL Server 2019 开始)。 有关 SQL Server 中 ADR 的信息,请参阅管理加速数据库恢复。
注意
在 Azure SQL 数据库和 Azure SQL 托管实例中,ADR 是默认启用的。 不支持在 Azure SQL 数据库和 Azure SQL 托管实例中禁用 ADR。
概述
ADR 的主要优势在于:
快速且一致的数据库恢复
使用 ADR,长时间运行的事务不会影响整体恢复时间,且无论系统中活动事务的数量或大小如何,都可以实现快速且一致的数据库恢复。
即时事务回滚
使用 ADR,事务回滚是即时的,与事务处于活动状态的时间或已执行的更新次数无关。
主动日志截断
即使存在长时间运行的活动事务,ADR 也会主动截断事务日志,这可以防止其增长失控。
标准数据库恢复过程
数据库恢复遵循 ARIES 恢复模式,由三个阶段组成,如下图所示,并在该示意图下附有详细的说明。
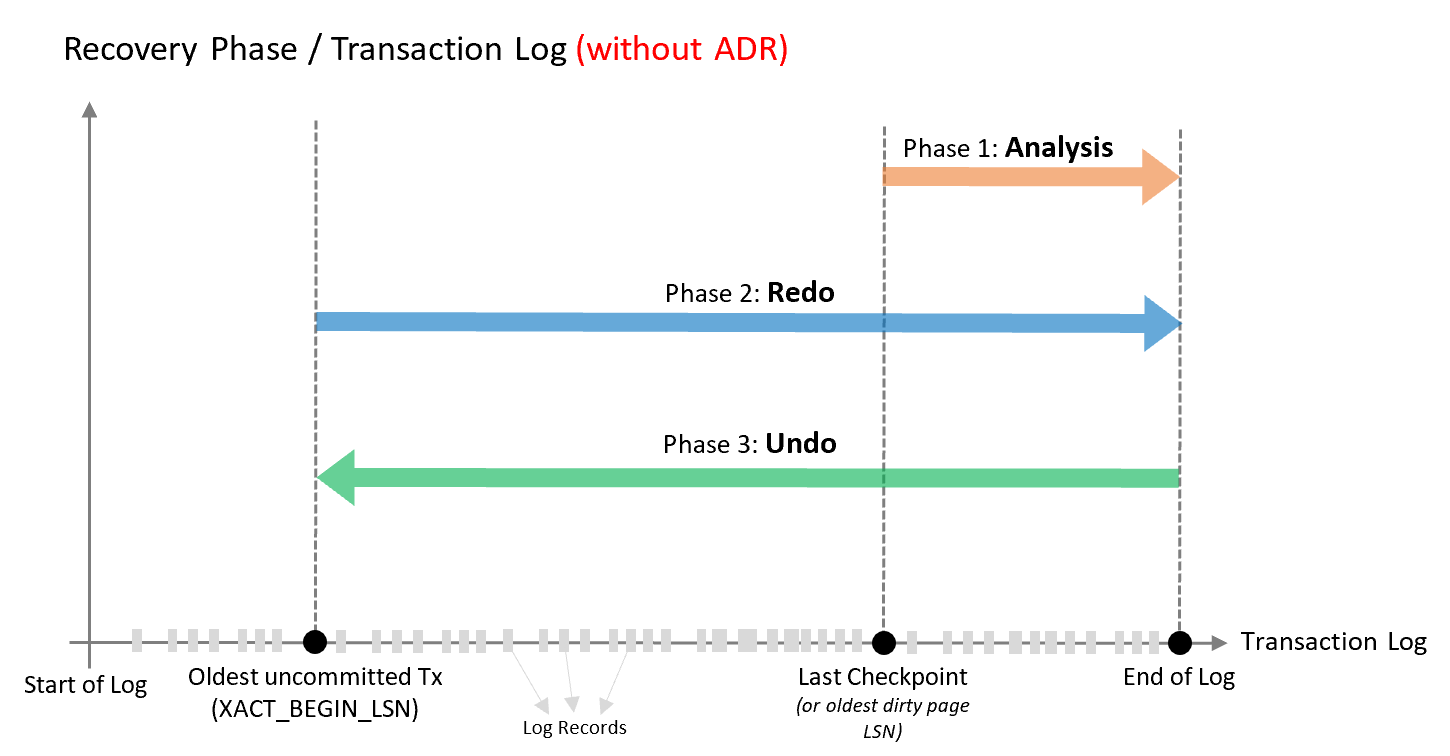
分析阶段
从最后一个成功检查点(或最早的脏页 LSN)的开头向前扫描事务日志直至结束,以确定数据库停止时每个事务的状态。
重做阶段
从最早的未提交事务开始向前扫描事务日志直至结束,通过恢复所有提交的操作将数据库恢复到故障时的状态。
撤消阶段
对于在故障时处于活动状态的每个事务,向后遍历日志,撤消该事务执行的操作。
基于此设计,SQL Server 数据库引擎从意外重启中恢复所需的时间(大致)与故障时系统中时间最长的活动事务的大小成正比。 恢复需要回滚所有未完成的事务。 所需的时间长度与事务已执行的工作及其处于活动状态的时间成正比。 因此,存在长期运行的事务(例如对大型表的大批量插入操作或索引生成操作)时,恢复过程可能需要很长时间。
此外,基于此设计,取消/回滚大型事务也可能需要很长时间,因为它使用与上述流程相同的撤消恢复阶段。
此外,存在长期运行的事务时,SQL Server 数据库引擎无法截断事务日志,因为恢复和回退过程需要相应的日志记录。 由于 SQL Server 数据库引擎的这种设计,一些客户过去常常面临事务日志变得非常大并占用大量驱动器空间的问题。
加速的数据库恢复过程
ADR 通过完全重新设计 SQL Server 数据库引擎恢复过程来解决上述问题,具体内容如下:
- 通过避免以最早的活动事务为起始点/结束点扫描日志,使其保持恒定时间/即时状态。 使用 ADR,事务日志仅从最后一个成功检查点(或最早的脏页日志序列号 (LSN))开始处理。 因此,恢复时间不受长时间运行的事务影响。
- 由于不再需要为整个事务处理日志,因此可最大程度地减少所需的事务日志空间。 当检查点和备份出现时,可以主动截断事务日志。
从较高层次来看,ADR 可通过对所有物理数据库修改进行版本控制并仅撤消逻辑操作(逻辑操作比较有限,且几乎可以立即撤消)来实现快速数据库恢复。 在故障时处于活动状态的任何事务都被标记为已中止,因此,并发用户查询可以忽略这些事务生成的任何版本。
ADR 恢复过程与当前恢复过程具有相同的三个阶段。 下图说明了这些阶段在 ADR 中的运作方式,并在该示意图后附带了详细的说明。
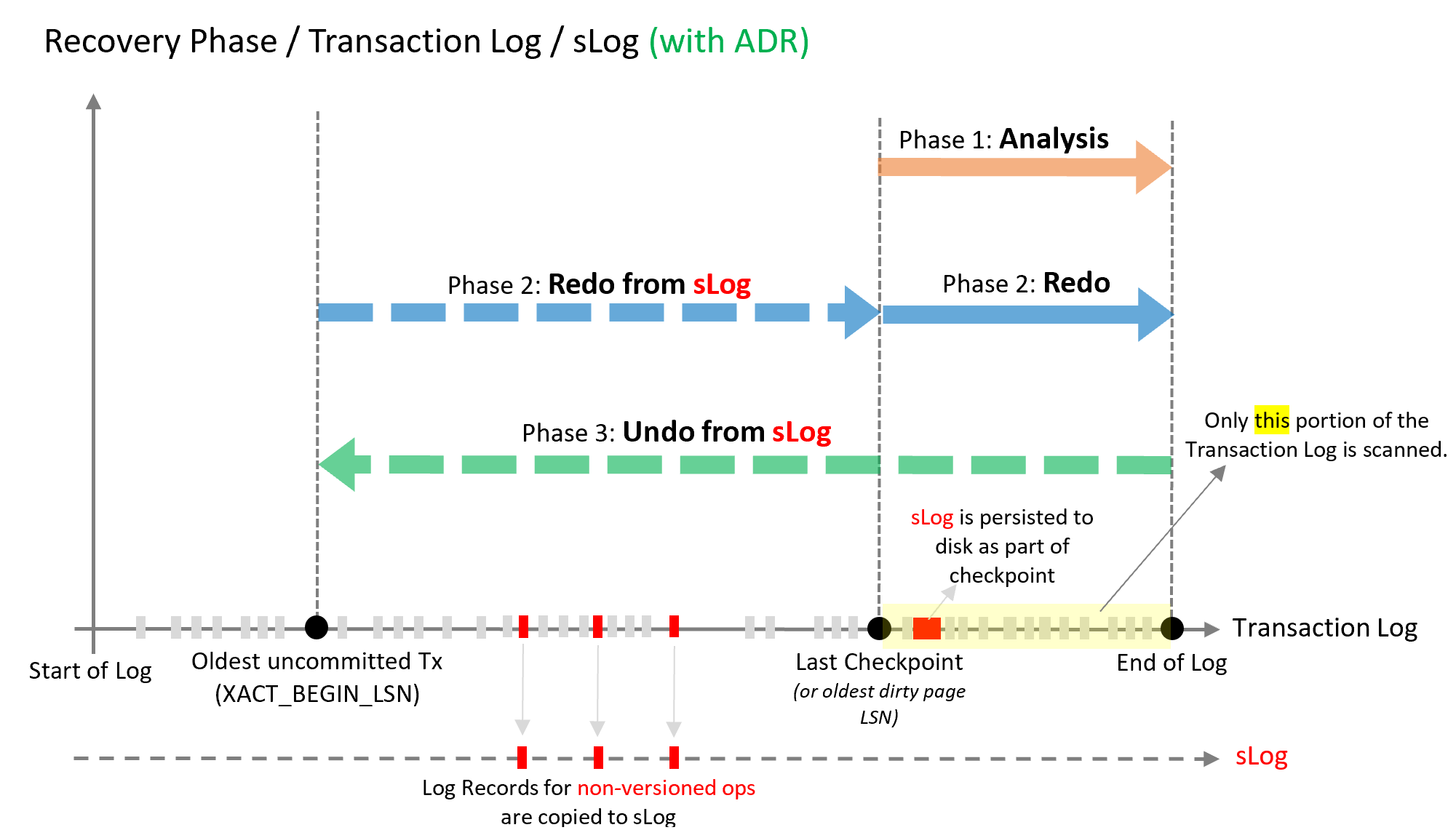
分析阶段
这个过程和以前一样,但增加了为非版本控制操作重建 SLOG 和复制日志记录。
重做阶段
分为两个阶段 (P)
阶段 1
从 SLOG 重做(从最早的未提交事务到上一个检查点)。 重做是一种快速操作,因为它只需要处理 SLOG 中的一些记录。
阶段 2
从事务日志开始恢复,从最后一个检查点(而不是最早的未提交事务)开始
撤消阶段
使用 ADR,撤消阶段几乎即时完成 - 通过使用 SLOG 撤消非版本控制操作以及通过具有逻辑还原的持久版本存储 (PVS) 执行行级别基于版本的撤消。
ADR 恢复组件
ADR 的四个关键组件是:
持久版本存储 (PVS)
持久版本存储是一种新的 SQL Server 数据库引擎机制,用于持久保存在数据库本身生成生成(而不是在传统的
tempdb版本存储中生成)的行版本。 PVS 支持资源隔离,并提高可读辅助数据库的可用性。逻辑还原
逻辑还原是一种异步过程,负责在行级别执行基于版本的撤消 - 为所有版本化操作实现即时事务回滚和撤消功能。 逻辑还原通过以下方式来完成:
- 跟踪所有已中止事务,并将它们标记为对其他事务不可见。
- 使用 PVS 执行所有用户事务的回滚操作,而不是通过物理方式扫描事务日志并逐一撤消更改。
- 在事务中止后立即释放所有锁定。 由于中止涉及到直接在内存中标记更改,此过程很高效,因此不需长时间维持锁定状态。
SLOG
SLOG 是一个辅助内存中日志流,用于存储非版本控制操作(如元数据缓存无效、锁获取等)的日志记录。 SLOG 具有以下特性:
- 低容量和内存中
- 通过在检查点过程中序列化保留在磁盘上
- 提交事务时定期被截断
- 通过仅处理非版本控制操作来加速重做和撤消
- 通过仅保留所需的日志记录来实现主动事务日志截断
清理器
清理器是定期唤醒并清除不需要的页面版本的异步过程。
加速数据库恢复 (ADR) 模式
以下类型的工作负荷最受益于 ADR:
- 对于包含长时间运行的事务的工作负荷,建议使用 ADR。
- 对于活动事务正在导致事务日志显著增大的工作负荷,建议使用 ADR。
- 对于由于长时间运行的恢复(如意外的服务重启或手动事务回滚)而经历了数据库长时间不可用的工作负荷,建议使用 ADR。
加速数据库恢复的最佳做法
避免数据库中长时间运行的事务。 尽管 ADR 的一个目标是通过重做长时间活动的事务来加速数据库恢复,但长时间运行的事务可能会延迟版本清理并增加 PVS 的大小。
避免包含数据定义更改或 DDL 操作的大型事务。 ADR 使用 SLOG(系统日志流)机制跟踪恢复中使用的 DDL 操作。 只有在事务处于活动状态时,才使用 SLOG。 SLOG 设置了检查点,因此避免使用 SLOG 的大型事务可帮助改善整体性能。 下面这些情况可能会导致 SLOG 占用更多空间:
许多 DDL 在一个事务中执行。 例如,在一个事务中快速创建和删除临时表。
表中包含大量已修改的分区/索引。 例如,对此类表执行的 DROP TABLE 操作需要预留较大的 SLOG 内存,这会延迟事务日志的截断并延迟撤消/重做操作。 解决方法是逐步依次删除索引,然后再删除表。 有关 SLOG 的详细信息,请参阅 ADR 恢复组件。
阻止或减少不必要的中止情况。 高中止率会给 PVS 清理程序带来压力,并降低 ADR 性能。 中止可能是由高比例的死锁、重复键或其他约束冲突导致的。
sys.dm_tran_aborted_transactionsDMV 显示了 SQL Server 实例上的所有中止事务。nested_abort列指示事务已提交,但存在中止的部分(保存点或嵌套事务),这可能会阻碍 PVS 清理进程。 有关详细信息,请参阅 sys.dm_tran_aborted_transactions (Transact-SQL)。若要在工作负荷之间或维护时段内手动激活 PVS 清理过程,请使用
sys.sp_persistent_version_cleanup。 有关详细信息,请参阅 sys.sp_persistent_version_cleanup。
如果发现有关存储使用情况、高中止事务和其他因素的问题,请参阅排查 SQL Server 上的加速数据库恢复 (ADR) 问题。