本教程介绍如何使用 Python、Docker 容器、Kubernetes 和 Azure SQL Database开发新式应用程序。
新式应用程序开发面临着诸多挑战。 从选择前端的“技术栈”到按照多个竞争标准进行数据存储和处理,开发人员需要通过确保最高级别的安全性和性能来保证应用程序具有良好的扩展性和性能,并能够在多个平台上支持。 为了满足上述要求,将应用程序捆绑到容器技术(例如 Docker),并将多个容器部署到 Kubernetes 平台,目前已经称为应用程序开发中的常规方法。
在此示例中,我们将探讨如何使用 Python、Docker 容器和 Kubernetes - 所有在 Azure 平台上运行。 使用 Kubernetes 意味着你还可以灵活地使用本地环境甚至其他云,实现应用程序的无缝一致部署,并且允许使用多云部署,从而提高复原能力。 我们还将Azure SQL Database用于基于服务的、可缩放、高度复原和安全的环境,用于数据存储和处理。 事实上,在许多情况下,其他应用程序通常已使用Azure SQL Database,此示例应用程序可用于进一步使用和扩充这些数据。
此示例的范围非常全面,但却使用了最简单的应用程序、数据库和部署来说明这个过程。 你可以对此示例进行调整,让它更加可靠,甚至包括使用最新技术来处理返回的数据。 它是为其他应用程序创建模式的实用学习工具。
在实际示例中使用 Python、Docker 容器、Kubernetes 和 AdventureWorksLT 示例数据库
AdventureWorks(虚构)公司使用一个数据库来存储有关销售和营销、产品、客户和制造的数据。 该公司还使用视图和存储过程,用于联接有关产品的信息,例如产品名称、类别、价格和简要说明。
AdventureWorks 开发团队希望创建一个概念证明 (PoC),从 AdventureWorksLT 数据库中的视图返回数据,并将其作为 REST API 提供。 使用此 PoC,开发团队将为销售团队创建可缩放性更强的多云就绪应用程序。 他们已为部署的各个方面选择了Azure平台。 PoC 使用以下元素:
- 使用 Flask 包进行无外设 Web 部署的Python应用程序。
- Docker 容器,用于代码和环境隔离,存储在专用注册表中,让整个公司能够在今后的项目中重复使用应用程序容器,从而节省时间和资金。
- Kubernetes,便于部署和缩放,并可避免平台锁定。
- Azure SQL Database 不仅用于关系数据存储和在最高安全级别进行处理,还可用于选择大小、性能、缩放、自动管理和备份。
在本文中,我们将介绍创建整个概念证明项目的过程。 下面是创建应用程序的常规步骤:
- 设置先决条件
- 创建应用程序
- 创建 Docker 容器以部署应用程序和测试
- 创建Azure容器服务(ACS)注册表并将容器加载到 ACS 注册表
- 创建Azure Kubernetes Service (AKS)环境
- 将应用程序容器从 ACS 注册表部署到 AKS
- 测试应用程序
- 清理
先决条件
在本文中,有一些值应该进行替换。 请确保在每个步骤中一致地替换这些值。 在完成概念证明项目时,你可能需要打开文本编辑器并删除这些值,以便设置正确的值:
-
ReplaceWith_AzureSubscriptionName:将此值替换为你拥有的Azure订阅名称。 -
ReplaceWith_PoCResourceGroupName:将此值替换你要创建的资源组的名称。 -
ReplaceWith_AzureSQLDBServerName:将此值替换为使用 Azure 门户创建的Azure SQL Database逻辑服务器的名称。 -
ReplaceWith_AzureSQLDBSQLServerLoginName:将此值替换为在Azure门户中创建的SQL Server用户名的值。 -
ReplaceWith_AzureSQLDBSQLServerLoginPassword:将此值替换为在Azure门户中创建的SQL Server用户密码的值。 -
ReplaceWith_AzureSQLDBDatabaseName:将此值替换为使用 Azure 门户创建的Azure SQL Database的名称。 -
ReplaceWith_AzureContainerRegistryName:将此值替换为要创建的Azure Container Registry的名称。 -
ReplaceWith_AzureKubernetesServiceName:将此值替换为要创建的Azure Kubernetes Service的名称。
AdventureWorks 的开发人员使用 Windows、Linux 和 Apple 系统进行开发,因此它们使用 Visual Studio Code 作为其环境和源代码管理 git,这两者都运行跨平台。
对于 PoC 项目,开发团队需要满足以下先决条件:
Python、pip 和包 - 开发团队选择 Python 编程语言作为此基于 Web 的应用程序的标准。 目前,它们使用的是版本 3.10,但支持 PoC 所需包的任何版本都是可以接受的。
- 可以从 python.org 下载 Python 版本 3.10。
团队使用
mssql-python驱动程序进行数据库访问。开发团队使用
ConfigParser包来控制和设置配置变量。开发团队将 Flask 包用作应用程序的 Web 接口。
接下来,团队安装了Azure CLI工具,该工具可通过
az语法轻松识别。 借助这个跨平台工具,他们可以将命令行和脚本化方法用于 PoC,这样他们就能够在进行更改和改进时重复这些步骤。设置Azure CLI后,团队登录到其Azure订阅,并设置用于 PoC 的订阅名称。 然后,他们确保订阅可以访问Azure SQL Database服务器和数据库:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameAzure资源组是一个逻辑容器,用于保存Azure解决方案的相关资源。 通常可将共享相同生命周期的资源添加到同一资源组,以便将其作为一个组轻松部署、更新和删除。 资源组存储有关资源的元数据,你可以指定资源组的位置。
可以使用Azure门户或Azure CLI创建和管理资源组。 它们还可用于对应用程序的相关资源进行分组,并将其划分为用于生产和非生产的组,或者划分为你需要的任何组织结构。
<截屏>从 Azure 门户中显示如何搜索和筛选 Azure 资源组。
在以下代码片段中,可以看到使用
az命令来创建资源组。 在我们的示例中,我们使用 chinanorth3 Azure 区域。az group create --name ReplaceWith_PoCResourceGroupName --location chinanorth3开发团队创建了一个 Azure SQL 数据库,安装了
AdventureWorksLT示例数据库,并使用了 SQL 身份验证的登录名。AdventureWorks 已在 Microsoft SQL Server 关系数据库管理系统平台标准化,开发团队希望对数据库使用托管服务,而不是在本地安装。 使用 Azure SQL Database 可以使该托管服务在运行 SQL Server 引擎的任何地方(无论是本地、容器、Linux 或 Windows,甚至是物联网(IoT)环境),都能完全实现代码兼容。
创建期间,他们使用 Azure 管理门户将应用程序的防火墙设置为本地开发计算机,并更改了此处看到的默认值,以启用 允许所有 Azure 服务,并检索了连接凭据。
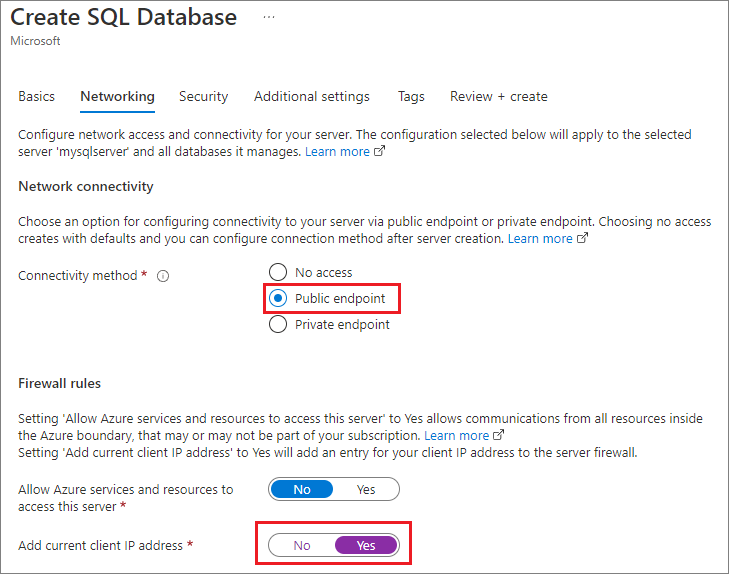
使用此方法,可在另一个区域甚至不同的订阅中访问数据库。
开发团队设置了 SQL 身份验证登录名,用于进行测试,但在安全评审中,我们将重新考虑这个决定。
开发团队为 PoC 使用了
AdventureWorksLT示例数据库,还使用了相同的 PoC 资源组。 别担心,在本教程结束时,我们将清理这个新 PoC 资源组中的所有资源。可以使用 Azure 门户部署 Azure SQL Database。 创建Azure SQL Database时,在 Additional settings 选项卡中,对于 使用现有数据选项,选择 Sample。
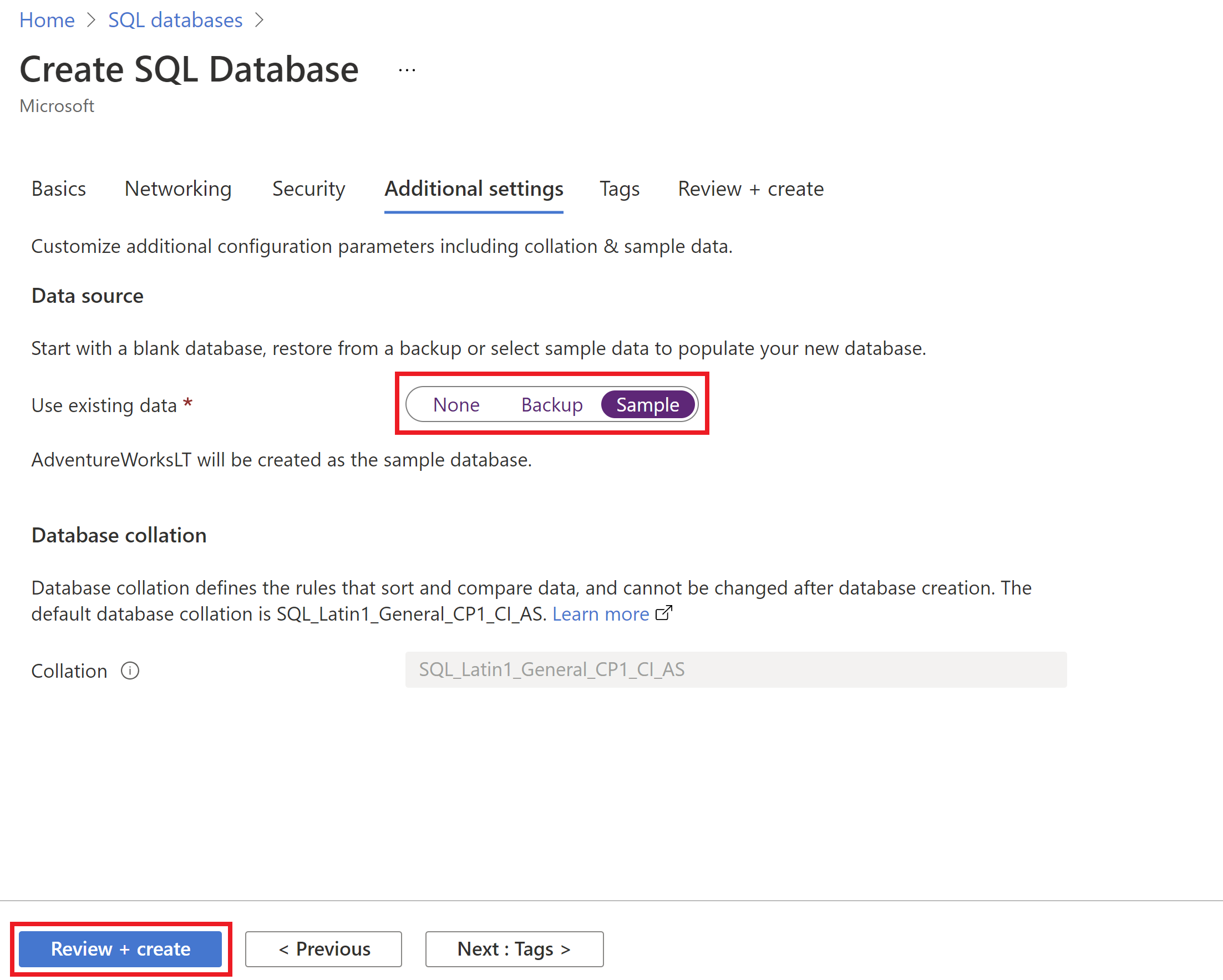
最后,在新Azure SQL Database的 Tags 选项卡上, 开发团队为此Azure资源提供标记元数据,例如 Owner 或 ServiceClass 或 WorkloadName。

创建应用程序
接下来,开发团队创建了一个简单的Python应用程序,该应用程序打开了与Azure SQL Database的连接,并返回产品列表。 此代码将替换为更复杂的函数,还可能包括部署到用于生产的 Kubernetes Pod 中的多个应用程序,以便使用可靠的清单驱动的方法,提供应用程序解决方案。
开发团队创建了一个名为
.env的简单文本文件,用于保存服务器连接和其他信息的变量。 使用python-dotenv库,他们可以将变量与 Python Code 分离出来。 这是让机密和其他信息不保留在代码自身中的常见方法。SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseName注意
为简单起见,此应用程序使用从Python读取的配置文件。 由于代码将使用容器进行部署,因而连接信息也许能够从内容派生。 应该谨慎考虑用于保护安全、连接和机密的各种方法,并确定应该用于应用程序的最佳级别和机制。 始终选择最高级别的安全性,甚至选择多个级别,从而确保应用程序是安全的。 有多个选项可用于处理机密信息(如连接字符串等),以下列表显示了其中的一些选项。
有关详细信息,请参阅 Azure SQL Database security。
然后,开发团队编写了 PoC 应用程序,并将其命名为
app.py。以下脚本完成这些步骤:
- 为配置和基本 Web 接口设置库。
- 从
.env文件加载变量。 - 创建 Flask-RESTful 应用程序。
- 使用
.env文件值获取Azure SQL Database连接信息。 - 使用
mssql-python驱动程序连接到Azure SQL Database。 - 创建要对数据库运行的 SQL 查询。
- 创建用于从 API 返回数据的类。
- 将 API 终结点设置为
Products类。 - 最后,在默认 Flask 端口 5000 上启动应用程序。
# Set up the libraries for the configuration and base web interfaces import os import json from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api from mssql_python import connect # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the .env file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection string for mssql-python connection_string = f'Server={server_name};Database={database_name};UID={user_name};PWD={password};Encrypt=yes;TrustServerCertificate=no;' # Connect to Azure SQL Database using the mssql-python driver connection = connect(connection_string) # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)它们确认此应用程序在本地运行,并将页面返回到
http://localhost:5000/products。
重要
生成生产应用程序时,请勿使用管理员帐户访问数据库。 有关详细信息,请阅读有关如何为应用程序设置帐户的更多内容。 本文中的代码已简化,以便可以在 Azure 中使用 Python 和 Kubernetes 快速开始使用应用程序。
更实际的做法是,你可以使用具有只读权限的独立数据库用户,或使用连接到具有只读权限的用户分配的托管标识的登录用户或独立数据库用户。
有关详细信息,请查看
有关如何使用 Python 和 Azure SQL Database 。

将应用程序部署到 Docker 容器
容器是在计算系统中保留的受保护空间,可提供隔离和封装。 若要创建容器,请使用清单文件,这是一个文本文件,描述要包含的二进制文件和代码。 然后,使用容器运行时(例如 Docker),你可以创建一个二进制映像,其中包含要运行和引用的所有文件。 从那里,可以“运行”二进制映像,即容器,可以像引用完整的计算系统一样引用它。 与使用完整虚拟机相比,它占用的存储空间更小,可以更简单地抽象应用程序运行时和环境。 有关详细信息,请参阅容器和 Docker。
开发团队首先使用 DockerFile(清单),这个清单对团队要使用的元素进行了分层。 它们从基础Python映像开始,然后运行在上一步中包含程序和配置文件所需的所有命令。
以下 Dockerfile 包含以下步骤:
- 从已安装Python的容器二进制文件开始。
- 为应用程序创建工作目录。
- 将所有代码从当前目录复制到
WORKDIR。 - 安装所需的库。
- 容器启动后,运行应用程序,并打开所有 TCP/IP 端口。
# syntax=docker/dockerfile:1
# Start with a Container binary that has Python installed
FROM python:3.10-slim
# Install ODBC driver (required by mssql-python)
RUN apt-get update && apt-get install -y \
curl gnupg2 apt-transport-https \
&& curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add - \
&& curl https://packages.microsoft.com/config/debian/11/prod.list > /etc/apt/sources.list.d/mssql-release.list \
&& apt-get update \
&& ACCEPT_EULA=Y apt-get install -y msodbcsql18 unixodbc-dev \
&& rm -rf /var/lib/apt/lists/*
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
有了该文件,团队就进入编码目录中的命令提示符,并运行以下代码来从清单创建二进制映像,然后运行另一个命令来启动容器:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
开发团队再次测试 http://localhost:5000/products 链接,以确保容器可以访问数据库,他们看到以下返回结果:

将映像部署到 Docker 注册表
容器目前正在工作,但仅在开发人员的计算机上可用。 开发团队希望将此应用程序映像提供给公司的其余用户,然后提供给 Kubernetes 进行生产部署。
容器映像的存储区域称为存储库,可能同时提供容器映像的公共存储库和专用存储库。 事实上,AdventureWorks 在其 Dockerfile 中为Python环境使用了公共映像。
团队希望控制对映像的访问,而不是将其置于 Web 上,而是决定自己托管它,但在Azure,他们可以完全控制安全和访问。 可以在此处阅读有关Azure Container Registry的详细信息
返回到命令行时,开发团队使用 az CLI 来添加容器注册表服务、启用管理帐户、在测试阶段将其设置为匿名“拉取”,并将登录上下文设置为注册表:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
此上下文将在后续步骤中使用。
标记本地 Docker 镜像以对其进行上传准备
下一步是将本地应用程序容器映像发送到 Azure Container Registry (ACR) 服务,使其在云中可用。
- 在以下示例脚本中,开发团队使用 Docker 命令列出计算机上的映像。
- 它们使用
az CLI实用工具列出 ACR 服务中的映像。 - 他们使用 Docker 命令,使用在上一步中创建的 ACR 的目标名称来“标记”映像,并设置版本号以进行适当的 DevOps。
- 最后,他们再次列出本地映像信息以确保标记应用正确。
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
编写并测试代码后,开发团队运行和测试了 Dockerfile、映像和容器,设置了 ACR 服务,应用了所有标记,然后他们可以将映像上传到 ACR 服务。
他们使用 Docker“push”命令发送文件,然后使用 az CLI 实用工具来确保映像已加载:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
部署到 Kubernetes
开发团队只需运行容器,并将应用程序部署到本地和云端环境。 但是,他们希望添加应用程序的多个副本以实现缩放和可用性,添加执行不同任务的其他容器,并为整个解决方案添加监视和仪表化功能。
为了将容器组合到完整的解决方案中,开发团队决定使用 Kubernetes。 Kubernetes 可在本地和所有主要云平台上运行。 Azure具有适用于 Kubernetes 的完整托管环境,称为Azure Kubernetes Service (AKS)。 了解有关 AKS 的详细信息,请参阅在 Azure 上的 Kubernetes 介绍训练路径。
使用 az CLI 实用工具,开发团队将 AKS 添加到此前创建的同一资源组。 使用单个 az 命令,开发团队完成以下步骤:
- 在测试阶段添加两个“节点”或计算环境,以实现复原能力
- 自动生成 SSH 密钥以便访问环境
- 附加在前面的步骤中创建的 ACR 服务,让 AKS 群集能够找到要用于部署的映像
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
Kubernetes 使用命令行工具来访问和控制名为 kubectl 的群集。 开发团队使用 az CLI 实用工具来下载和安装 kubectl 工具:
az aks install-cli
由于他们当时已与 AKS 建立连接,因此可以要求其发送 SSH 密钥,以便在执行 kubectl 实用工具时使用连接:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
这些密钥存储在用户目录中名为 .config 的文件中。 设置安全上下文后,开发团队使用 kubectl get nodes 来显示群集中的节点:
kubectl get nodes
现在,开发团队使用 az CLI 工具来列出 ACR 服务中的映像:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
现在他们可以生成供 Kubernetes 用来控制部署的清单。 它是以 yaml 格式存储的文本文件。 下面是 flask2sql.yaml 文件中的注释文本:
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
定义 flask2sql.yaml 文件后,开发团队可以将应用程序部署到正在运行的 AKS 群集。 这是通过 kubectl apply 命令完成的,你应该还记得,该命令仍然有群集的安全性上下文。 然后发送 kubectl get service 命令,以便在生成群集时监视群集。
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
稍后,“watch”命令将返回外部 IP 地址。 此时,开发团队按 Ctrl-C 中断监视命令,并记录负载均衡器的外部 IP 地址。
测试应用程序
使用在上一步中获取的 IP 地址(端点),开发团队进行检查,以确保与本地应用程序和 Docker 容器相同的输出:
清理
创建、编辑、记录和测试应用程序后,团队现在可以“拆解”应用程序。 通过在 Azure 中保留单个资源组中的所有内容,只需使用 az CLI 实用工具删除 PoC 资源组即可:
az group delete -n ReplaceWith_PoCResourceGroupName -y
注意
如果在另一个资源组中创建Azure SQL Database,并且不再需要它,则可以使用Azure门户将其删除。
领导 PoC 项目的团队成员使用Microsoft Windows作为工作站,并希望保留 Kubernetes 中的机密文件,但将其从系统中删除为活动位置。 他们只需将文件复制到 config.old 文本文件,然后将其删除:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config
相关内容
- 应用程序开发概述 - SQL 数据库与 SQL 托管实例
- 连接并使用 Python 和 mssql-python 驱动程序查询Azure SQL Database
- 浏览 Azure SQL Database 的代码示例